自学网络结构(一):Neural Architecture Search With Reinforcement Learning
论文:Neural Architecture Search With Reinforcement Learning
链接:https://arxiv.org/abs/1611.01578
代码链接:https://github.com/tensorflow/models
这是ICLR2017的文章,讲述如果用强化学习(reinforcement learning)来学习一个最优的网络结构。这篇文章的搜索方式现在看来较为简单粗暴,没有计算资源支持的话基本上跑不起来。这篇文章(可以结合Figure1看)通过一个controller在搜索空间(search space)中得到一个网络结构(child network),然后用这个网络结构在数据集上训练得到准确率,再将这个准确率回传给controller,controller继续优化得到另一个网络结构,如此反复进行直到得到最佳的结果。原文有一句概括写的不错:In this paper, we use a recurrent network to generate the model descriptions of neural networks and train this RNN with reinforcement learning to maximize the expected accuracy of the generated architectures on a validation set. 所以比较新颖的地方就是如何通过controller得到一个child network。
Figure1解释了如何通过一个controller来搜索最优结构并训练网络和优化controller的过程。可以看出最关键的部分就是controller,而作者的controller采用的就是RNN结构。关于为什么可以用RNN结构做controller来搜索最优结构,作者也给出了解释:Our work is based on the observation that the structure and connectivity of a neural network can be typically specified by a variable-length string. It is therefore possible to use a recurrent network – the controller – to generate such string. 因此和其他超参数优化只能在一个fixed-length space中搜索模型不同的是,这里可以在一个variable-length space中搜索模型。训练这个RNN网络则是通过梯度算法去优化的。

了解了controller,那么具体是优化过程是什么样的呢?这部分原文解释得非常清晰,可以结合Figure1一起看:Training the network specified by the string – the “child network” – on the real data will result in an accuracy on a validation set. Using this accuracy as the reward signal, we can compute the policy gradient to update the controller. As a result, in the next iteration, the controller will give higher probabilities to architectures that receive high accuracies. In other words, the controller will learn to improve its search over time.
Figure2表达的是controller如何得到一个child network的示意图,这里训练的搜索空间(search space)包括每一层的Filter尺寸、数量,stride的数值等。

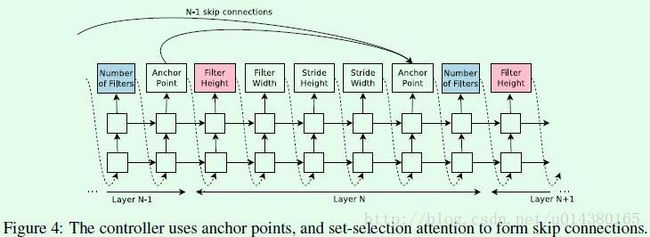
不过Figure2这样的搜索空间只是包含了常规的一些网络结构的元素,而没有包含类似GooleNet和ResNet那样的branching layer和skip connection,因此作者又做了一些工作,具体而言就是:At layer N, we add an anchor point which has N-1 content-based sigmoids to indicate the previous layers that need to be connected. 具体公式如下:
![]()
where hj represents the hiddenstate of the controller at anchor point for the j-th layer, where j
ranges from 0 to N-1.
Wprev、Wcurr和v就是模型要训练的参数,所以添加了skip connection的controller就是Figure4这样:
但是skip connection可能会带来一个问题:compilation failures。这是一个比较大的概括的词,包括的内容比如一些层没有输入或者输出、concate的feature map的尺寸不一等问题。具体解决方案作者陈述了如下3点:
1、If a layer is not connected to any input layer then the image is used as the input layer.
2、At the final layer we take all layer outputs that have not been connected and concatenate them before sending this final hiddenstate to the classifier.
3、If input layers to be concatenated have different sizes, we pad the small layers with zeros so that the concatenated layers have the same sizes.
另外在作者的框架中:If one layer has many input layers then all input layers are concatenated in the depth dimension.
那么controller要优化到什么程度才能得到一个网络结构呢(对应Figure1中从红色矩形框到蓝色矩形框的过程)?答案是当层数大于一个特定值的时候,生成网络的过程就会停止,而这个值是随着训练controller的进行而增长的,这个增长策略在CIFAR-10数据集中是从第6层开始,当每搜索1600个samples的时候就增加2层。当controller生成一个网络结构后(文中称这个网络结构为child network),那么就用这个网络结构在训练集上训练,并在验证集上得到准确率。准确率回传给controller,然后用reinforcement learning(强化学习)继续训练controller,如此反复迭代,最终得到最优的controller参数,也就是网络结构。强化学习采用policy gradient method来更新controller的参数。
接下来就要介绍如何生成controller。controller是一个RNN结构,下面这个式子就是一个最简单的RNN层的式子,也就是文中提到的recurrent cell:
![]()
因为The computations for basic RNN and LSTM cells can be generalized as a tree of steps that take xt and ht-1 as inputs and produce ht as final output. 因此在Figure5中介绍如何生成recurrent cell的过程也是基于树来介绍。Figure5左边图包含两个leaf node(index 0和index 1)和一个internal node(index 2)。作者在实验中用的是8个leaf node,具体可以参看论文最后的附录A。

原文关于Figure5的介绍比较详细,其中下面这5个step就和Figure5对应。比如Figure5中间图共分成5个部分,就和下面的5个step一一对应。这5个step就构成了recurrent cell,recurrent cell用于构成controller,因此本质上就是所谓controller的search space。

实验结果:
文章主要用到的数据集包括用于图像分类的CIFAR-10和用于语言任务的Penn Treebank。接下来仅介绍下CIFAR-10数据集上的实验结果,更多实验细节可以参看论文。
先来看看用于CIFAR-10的search space:
Our search space consists of convolutional architectures, with rectified linear units as non-linearities (Nair & Hinton, 2010), batch normalization (Ioffe & Szegedy, 2015) and skip connections between layers (Section 3.3). For every convolutional layer, the controller RNN has to select a filter height in [1, 3, 5, 7], a filter width in [1, 3, 5, 7], and a number of filters in [24, 36, 48, 64]. For strides, we perform two sets of experiments, one where we fix the strides to be 1, and one where we allow the controller to predict the strides in [1, 2, 3].
另外对于learning rate、weight decay、batchnorm epsilon、what epoch to decay the learning rate则采用grid search的方法来调,然后就得到了下面这个Table1的结果。不得不说有机器资源就是任性啊。
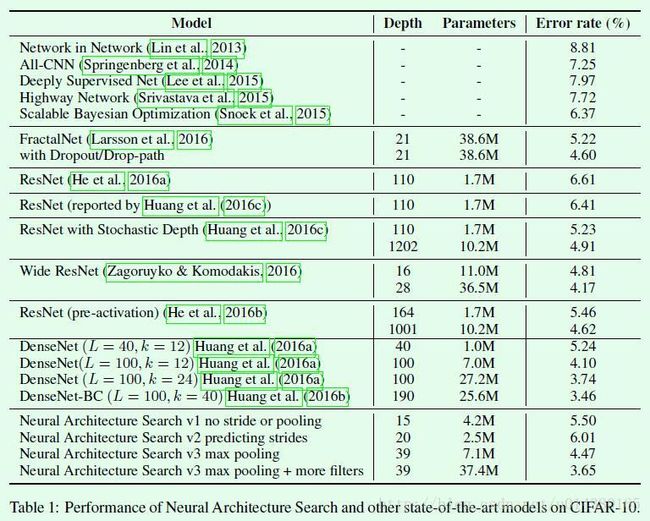
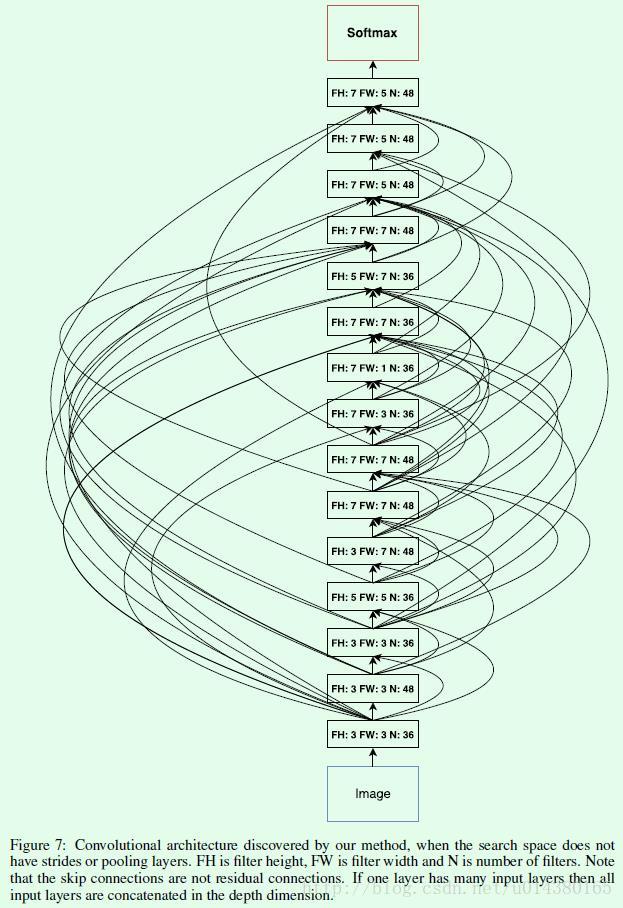
Table1中的倒数第4个:Neural Architecture Search v1 no stride or pooling的结构如下Figure7所示,看起来有点抓狂。注意几个点:在越靠近最后的softmax层的时候卷积核的尺寸反而更大一些,而且整体上来看,有不少卷积核是长方形,而不是常见的正方形。这些结论或许可以作为人工设计网络的一个参考。