【AI视野·今日CV 计算机视觉论文速览 第174期】Tue, 7 Jan 2020
AI视野·今日CS.CV 计算机视觉论文速览
Tue, 7 Jan 2020
Totally 57 papers
上期速览✈更多精彩请移步主页

Interesting:
**DepthTransfer,从视频中抽取深度图的方法 (from 伊利诺伊大学)

author:https://www.kevinkarsch.com/
code:https://github.com/kevinkarsch?tab=repositories
****Deep Snake, 一种高速的实例分割方法(from 浙江大学)
code:https://github.com/zju3dv/snake/
***逆问题的退化原因及解决方法, (from 剑桥)
code:https://github.com/vegarant/troub_ker
Agriculture-Vision, 农业模式数据集(from UIUC 俄勒冈大学)
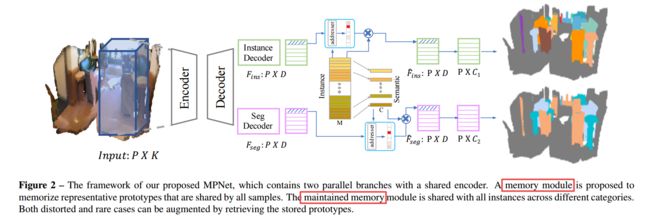
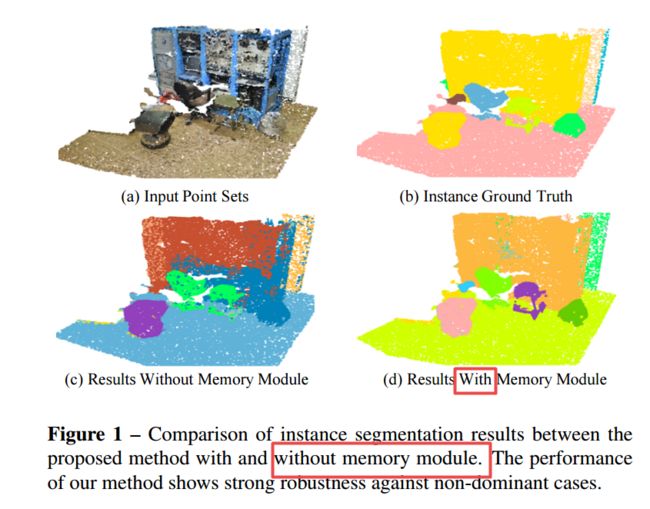
MPNet, 基于记忆模块增强的点云实例分割(from 阿德莱德大学)
高速伪造人脸检测FDFtNet(from 成均馆大学 韩国)
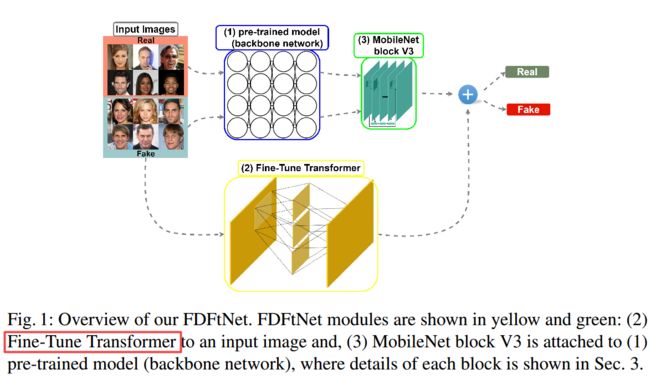
code:https://anonymous.4open.science/r/FDFtNet/
Grab,一套用户快速支付的超市结算系统(from 南加州大学)
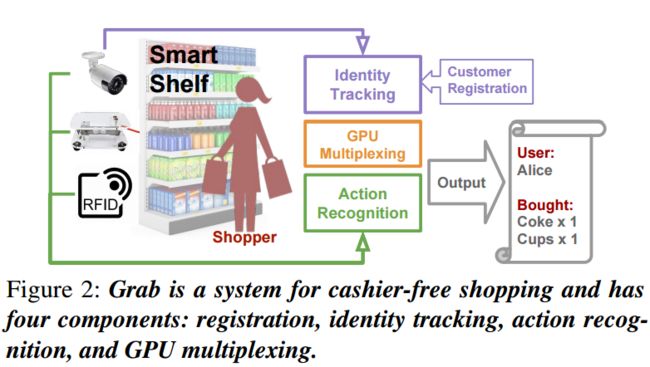
demo:https://vimeo.com/245274192,参考文献有很多技术文献值得学习
图相似性的综述,(from 英特尔实验室)
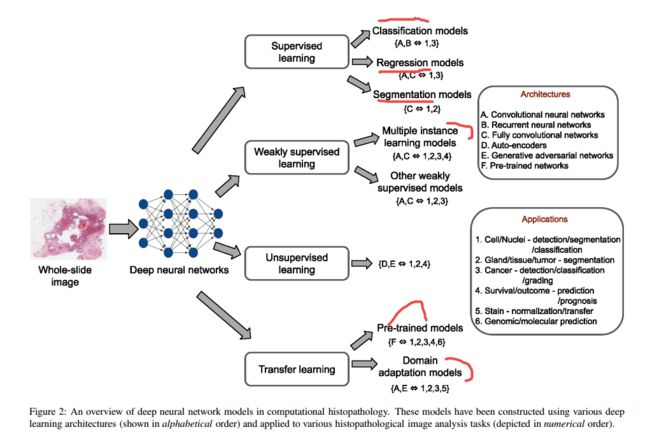
计算病理学综述, (from 多伦多大学)
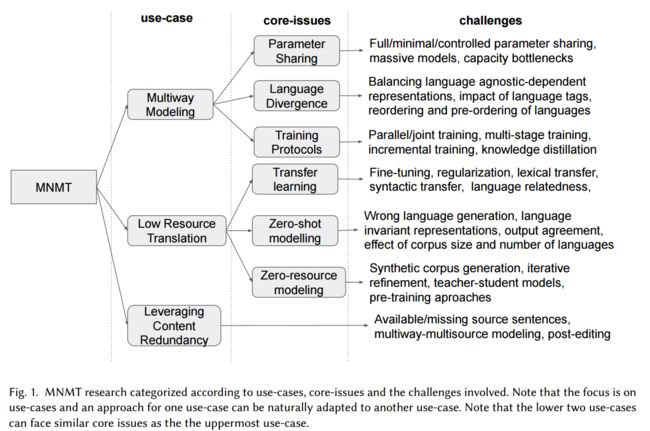
多语言神经翻译模型综述Multilingual Neural Machine Translation, (from 大阪大学 )
机器阅读理解综述, (from University
of Qom)
X-ray 安检深度学习综述, (from 杜伦大学 英)
Daily Computer Vision Papers
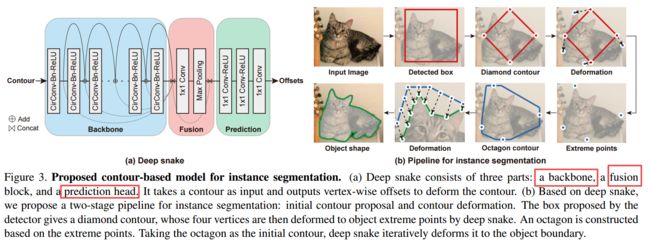
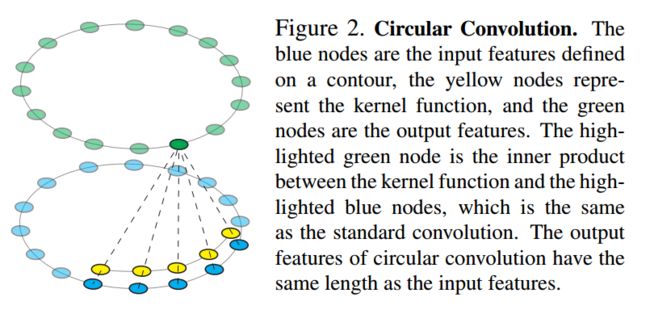
| Deep Snake for Real-Time Instance Segmentation Authors Sida Peng, Wen Jiang, Huaijin Pi, Hujun Bao, Xiaowei Zhou 本文介绍了一种新颖的基于轮廓的方法,称为深度蛇,用于实时实例分割。与一些最近的方法直接从图像中回归对象边界点的坐标不同,深蛇使用神经网络将初始轮廓迭代变形为对象边界,从而通过基于学习的方法实现了蛇算法的经典思想。对于轮廓上的结构化特征学习,我们建议在深蛇中使用圆形卷积,与通用图卷积相比,它可以更好地利用轮廓的循环图结构。在深蛇的基础上,我们开发了一个两阶段流水线,例如分割初始轮廓提议和轮廓变形,可以处理初始对象定位中的错误。实验表明,该方法在Cityscapes,Kins和Sbd数据集上达到了最先进的性能,同时对于1080Ti GPU上的512倍512幅图像的实时实例分割效率高达32.3 fps。该代码将在以下位置提供 |
| Chained Representation Cycling: Learning to Estimate 3D Human Pose and Shape by Cycling Between Representations Authors Nadine Rueegg, Christoph Lassner, Michael J. Black, Konrad Schindler 许多计算机视觉系统的目标是将图像像素转换为3D表示形式。最近流行的模型使用神经网络直接从像素回归到3D对象参数。这种方法在有监督的情况下效果很好,但是在诸如人体姿势和形状估计之类的问题中,很难获得具有3D地面真相的自然图像。为了更进一步,我们提出了一种新的体系结构,该体系结构可促进无监督或轻度监督的学习。想法是将问题分解为越来越抽象的表示形式之间的一系列转换。每个步骤都涉及一个设计为无须注释的训练数据即可学习的循环,循环链可提供最终解决方案。具体来说,我们使用2D身体部位段作为中间表示,它包含足以提升到3D的信息,同时又足够简单,可以无监督地学习。我们通过从未配对和未注释的图像中学习3D人体姿势和形状来演示该方法。我们还探索了各种数量的配对数据,并显示循环大大减轻了对配对数据的需求。尽管我们提供了模拟人类的结果,但我们的公式是通用的,可以应用于其他视觉问题。 |
| Few-shot Learning with Multi-scale Self-supervision Authors Hongguang Zhang, Philip H. S. Torr, Piotr Koniusz 从数量有限的数据点学习概念是一项具有挑战性的任务,通常通过所谓的一次或几次射击学习来解决。最近,在很少的镜头学习中应用二阶合并显示了其优越的性能,这是由于聚合步骤可以处理不同的图像分辨率,而无需修改CNN以适合特定的图像尺寸,却捕获了高度描述性的共现现象。但是,即使分辨率在整个数据集上变化,也对每个图像使用单一分辨率是次优的,因为图像内容的重要性在粗糙级别到精细级别之间有所变化,具体取决于对象及其类别标签e。例如,普通对象和场景依赖于它们的整体外观,而细颗粒对象更多地依赖于它们的局部纹理图案。多尺度表示法在图像去模糊,超分辨率和图像识别中很流行,但是由于其关系性质使标准技术的使用变得复杂,因此尚未在少数镜头学习中进行过研究。在本文中,我们基于二阶合并的性质提出了一种新颖的多尺度关系网络,以估计少量镜头设置下的图像关系。为了优化模型,我们利用比例选择器根据其二阶特征对比例明智的表示进行加权。此外,我们建议应用自我监督的规模预测。具体来说,我们利用额外的鉴别器来预测比例标签和图像对之间的比例差异。我们的模型在标准的少量镜头学习数据集上获得了最先进的结果。 |
| Multi-scale domain-adversarial multiple-instance CNN for cancer subtype classification with non-annotated histopathological images Authors Noriaki Hashimoto, Daisuke Fukushima, Ryoichi Koga, Yusuke Takagi, Kaho Ko, Kei Kohno, Masato Nakaguro, Shigeo Nakamura, Hidekata Hontani, Ichiro Takeuchi 我们提出了一种从组织病理学图像对癌症亚型进行分类的新方法,该方法可以在给定的完整幻灯片图像WSI中自动检测肿瘤的特定特征。应该通过参考WSI对癌症亚型进行分类,即WSI,通常是整个病理组织玻片的40,000x40,000像素的大尺寸图像,该图像由癌症和非癌症部分组成。构造癌症亚型分类器的一个困难来自于对不加注释的WSI进行注释所需要的高昂费用,我们必须在不了解真正标记的情况下构造肿瘤区域检测器。此外,必须通过更改图像的放大倍率从WSI中提取全局和局部图像特征。另外,应针对医院标本之间的染色差异,稳定地检测图像特征。在本文中,我们通过有效地组合可以克服这些实际困难的多实例,领域对抗和多尺度学习框架,开发了一种基于CNN的癌症亚型分类新方法。当该方法应用于多家医院收集的196例恶性淋巴瘤亚型分类时,其分类性能明显优于标准CNN或其他常规方法,其准确性优于标准病理学家。此外,我们通过免疫染色和专家病理学家的目测检查确认,可以正确检测出肿瘤区域。 |
| Hyperspectral Super-Resolution via Coupled Tensor Ring Factorization Authors Wei He, Yong Chen, Naoto Yokoya, Chao Li, Qibin Zhao 高光谱超分辨率HSR将低分辨率高光谱图像HSI和高分辨率多光谱图像MSI融合在一起,以获得高分辨率HSI HR HSI。在本文中,我们提出了一种用于高铁的新模型,称为耦合张量环分解CTRF。提出的CTRF方法同时从HSI学习高光谱分辨率核心张量和从MSI学习高空间分辨率核心张量,并通过张量环TR表示重建HR HSI。 CTRF模型可以分别利用每个类Section ref sec分析的低秩属性,而在以前的耦合张量模型中从未探讨过。同时,它继承了耦合矩阵CP分解的简单表示以及耦合Tucker分解的灵活的低秩探索。 |
| Learning From Multiple Experts: Self-paced Knowledge Distillation for Long-tailed Classification Authors Liuyu Xiang, Guiguang Ding 在现实世界中,数据倾向于呈现长尾,不平衡的分布。因此,在实际应用中开发处理这种长尾分布的算法变得必不可少。在本文中,我们提出了一种新颖的自我进度知识提炼框架,称为“向多专家学习LFME”。我们的方法是受以下观察启发的:在整个长尾分布的较少不平衡子集上训练的深度卷积神经网络CNN通常比联合训练的对等神经网络产生更好的性能。我们将这些模型称为“专家模型”,并且所提出的LFME框架汇总了来自多个专家的知识,以学习统一的学生模型。具体而言,所提出的框架涉及两个级别的自定进度的学习时间表,自定进度的专家选择和自定进度的实例选择,以便知识从多个专家自适应地转移到学生。为了验证我们提出的框架的有效性,我们对两个长尾基准分类数据集进行了广泛的实验。实验结果表明,与现有方法相比,我们的方法能够实现卓越的性能。我们还表明,我们的方法可以轻松地插入最新的长尾分类算法中,以进行进一步的改进。 |
| Mutual Mean-Teaching: Pseudo Label Refinery for Unsupervised Domain Adaptation on Person Re-identification Authors Yixiao Ge, Dapeng Chen, Hongsheng Li 人物识别ID旨在跨不同的相机识别同一个人的图像。然而,不同数据集之间的域多样性对于将在一个数据集上训练的re ID模型改编为另一数据集提出了明显的挑战。通过使用目标域上的聚类算法创建的伪标签进行优化,用于人员ID的最新无监督域自适应方法可以从源域中转移学习到的知识。尽管它们达到了最先进的性能,但是忽略了由聚类过程引起的不可避免的标签噪声。这种嘈杂的伪标记实质上阻碍了模型进一步改善目标域上的特征表示的能力。为了减轻嘈杂的伪标签的影响,我们建议通过提出一种无监督框架Mutual Mean Teaching MMT来对目标域中的伪标签进行软优化,以通过离线精炼的伪伪标签和目标域从目标域中学习更好的功能。在线以另一种训练方式改进了软伪标签。另外,通常的做法是同时采用分类损失和三元组损失,以实现个人身份识别模型的最佳性能。但是,传统的三重态损失不适用于柔和的标签。为了解决这个问题,提出了一种新的softsoftmax三重态丢失,以支持具有伪伪三重态标签的学习,以实现最佳的域自适应性能。拟议的MMT框架在市场到杜克,市场到杜克,市场到MSMT和杜克到MSMT的无监督域适应任务上实现了14.4、18.2、13.1和16.4 mAP的显着改进。代码位于 |
| Deceiving Image-to-Image Translation Networks for Autonomous Driving with Adversarial Perturbations Authors Lin Wang, Wonjune Cho, Kuk Jin Yoon 深度神经网络DNN在处理计算机视觉问题方面取得了令人印象深刻的性能,但是,已经发现DNN容易受到对抗示例的攻击。因此,最近在几个方面研究了对抗性扰动。但是,以前的大多数工作都集中在图像分类任务上,从未针对图像到图像Im2Im转换任务的对抗性扰动进行过研究,在自动驾驶和机器人技术领域中,在处理成对和/或不成对映射问题方面显示出了巨大的成功。本文研究了各种类型的对抗性扰动,它们可以欺骗Im2Im框架以实现自动驾驶。我们提出准物理和数字对抗扰动,它们可以使Im2Im模型产生出乎意料的结果。然后,我们根据经验分析这些扰动,并表明它们在用于图像合成的配对和用于样式转换的未配对设置下都能很好地概括。我们还验证了存在一些摄动阈值,超过了此阈值,Im2Im映射被破坏或无法实现。这些扰动的存在表明,Im2Im模型中存在关键的弱点。最后,我们证明了我们的方法说明了扰动如何影响输出质量,并率先提高了用于自动驾驶的当前SOTA网络的鲁棒性。 |
| Facial Emotions Recognition using Convolutional Neural Net Authors Faisal Ghaffar 人类使用面部表情来表达自己的情感。对于人类来说,很容易识别这些情绪,但是对于计算机而言,则是非常具有挑战性的。面部表情因人而异。每个随机图像的亮度,对比度和分辨率都不同。这就是为什么很难识别面部表情的原因。面部表情识别是一个活跃的研究领域。在这个项目中,我们致力于识别人类的七个基本情感。这些情绪是愤怒,厌恶,恐惧,快乐,悲伤,惊奇和中立。首先将每个图像通过人脸检测算法,以将其包括在火车数据集中。由于CNN需要大量数据,因此我们在每个图像上使用各种过滤器来复制数据。该系统使用CNN架构进行培训。尺寸为80 100的预处理图像作为输入传递到CNN的第一层。使用了三个卷积层,每个卷积层之后是一个合并层,然后是三个密集层。致密层的脱落率为20。该模型是通过结合两个公开可用的数据集JAFFED和KDEF进行训练的。其中90个数据用于训练,而10个数据用于测试。使用组合数据集,我们达到了78的最大准确性。 |
| CAE-LO: LiDAR Odometry Leveraging Fully Unsupervised Convolutional Auto-Encoder for Interest Point Detection and Feature Description Authors Deyu Yin, Qian Zhang, Jingbin Liu, Xinlian Liang, Yunsheng Wang, Jyri Maanp , Hao Ma, Juha Hyypp , Ruizhi Chen 作为3D映射,自动驾驶和机器人导航中的一项重要技术,LiDAR测距法仍然是一项艰巨的任务。利用紧凑的二维结构化球面环投影模型和保留输入数据原始形状的体素模型,我们提出了一种完全无监督的基于卷积自动编码器的LiDAR里程表CAE LO,可使用2D CAE从球面环数据中检测兴趣点并从多分辨率中提取特征使用3D CAE的体素模型。我们基于KITTI数据集做出了几个关键贡献1实验表明,我们的兴趣点可以捕获更多局部细节,从而在非结构化场景下提高匹配成功率,并且在匹配固有比率2方面,我们的功能优于现有技术50倍以上还提出了一种基于匹配对转移的关键帧选择方法,一种基于来自球形环的扩展兴趣点的关键帧的里程表细化方法以及一种向后姿态更新方法。里程计优化实验验证了所提出的想法的可行性和有效性。 |
| Learning and Memorizing Representative Prototypes for 3D Point Cloud Semantic and Instance Segmentation Authors Tong He, Dong Gong, Zhi Tian, Chunhua Shen 3D点云语义和实例分割对于3D场景理解至关重要且至关重要。由于结构复杂,点集会失衡且分散分布,这既表现为类别失衡,也表现为模式失衡。结果,深度网络很容易在学习过程中忘记非主导案例,从而导致性能不理想。尽管重新加权可以减少分类良好的示例的影响,但它们无法处理动态训练期间的非主导模式。在本文中,我们提出了一种内存增强网络,以学习和记忆涵盖了各种样本的代表性原型。具体来说,引入了一个存储模块,以通过记录在小批量训练中看到的模式来减轻遗忘问题。学习到的记忆项目始终反映主导和非主导类别和案例的可解释和有意义的信息。因此,可以通过检索存储的原型来增加失真的观察结果和罕见的情况,从而获得更好的性能和通用性。在基准(S3DIS和ScanNetV2)上进行的详尽实验反映了我们方法在有效性和效率上的优势。不仅整体准确性提高了,而且非主流类也大大提高了。 |
| Convolutional Neural Networks with Intermediate Loss for 3D Super-Resolution of CT and MRI Scans Authors Mariana Iuliana Georgescu, Radu Tudor Ionescu, Nicolae Verga 如今,医院中常用的CT扫描仪可产生低分辨率图像,最大尺寸可达512像素。图像中的一个像素对应于一毫米的组织。为了准确地分割肿瘤并制定治疗计划,医生需要更高分辨率的CT扫描。 MRI中出现相同的问题。在本文中,我们提出了一种用于3D CT或MRI扫描的单图像超分辨率的方法。我们的方法基于深度卷积神经网络CNN,该CNN由10个卷积层和一个中间扩展层组成,该中间放大层位于前6个卷积层之后。我们的第一个CNN可以提高两个轴的宽度和高度的分辨率,然后是第二个CNN,它可以提高第三轴深度的分辨率。与其他方法不同,除了计算最后一个卷积层之后的损耗外,我们还计算相对于升频层之后的地面真实高分辨率输出的损耗。中间损耗迫使我们的网络产生更好的输出,更接近地面实况。获得清晰结果的一种广泛使用的方法是使用固定的标准偏差添加高斯模糊。为了避免过度拟合固定的标准偏差,我们采用了具有各种标准偏差的高斯平滑法,这与其他方法不同。我们在来自两个数据库的CT和MRI扫描的2D和3D超分辨率的背景下评估了我们的方法,并使用2x和4x缩放因子,将其与基于各种插值方案的文献和基线的相关相关工作进行了比较。实证结果表明,我们的方法比所有其他方法都具有更好的结果。此外,我们的人体注释研究表明,医生和常规注释者都选择使用我们的方法来支持Lanczos插值,其中97.55例的放大倍数为2倍,而96.69例的放大倍数为4倍。 |
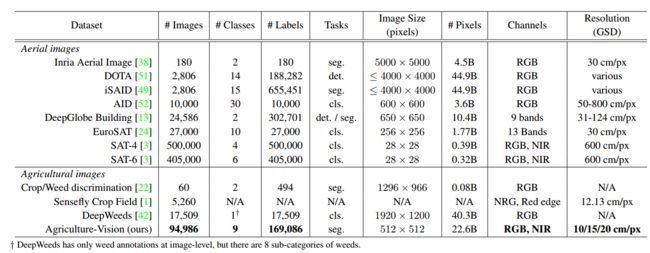
| Agriculture-Vision: A Large Aerial Image Database for Agricultural Pattern Analysis Authors Mang Tik Chiu, Xingqian Xu, Yunchao Wei, Zilong Huang, Alexander Schwing, Robert Brunner, Hrant Khachatrian, Hovnatan Karapetyan, Ivan Dozier, Greg Rose, David Wilson, Adrian Tudor, Naira Hovakimyan, Thomas S. Huang, Honghui Shi 深度学习在视觉识别任务中的成功推动了多个研究领域的进步。特别是,人们越来越关注它在农业中的应用。然而,尽管农田上的视觉模式识别具有巨大的经济价值,但由于缺乏合适的农业图像数据集,在融合计算机视觉和作物科学方面进展甚微。同时,农业问题也给计算机视觉带来了新的挑战。例如,空中农田图像的语义分割需要对具有极大注释稀疏性的超大型图像进行推理。这些挑战在大多数常见对象数据集中并不存在,并且我们证明它们比许多其他航拍图像数据集更具挑战性。为了鼓励对农业计算机视觉的研究,我们为农业视觉提供了大规模的空中农田图像数据集,用于农业模式的语义分割。我们从美国3,432个农田中收集了94,986张高质量的航空图像,其中每幅图像均由RGB和近红外NIR通道组成,分辨率高达每像素10厘米。我们注释了对农民最重要的九种田间异常模式。作为航空农业语义分割的一项先导研究,我们使用流行的语义分割模型进行了全面的实验,我们还提出了一种用于航空农业模式识别的有效模型。我们的实验证明了农业视觉对计算机视觉和农业社区的挑战。该数据集的未来版本将包括更多的航拍图像,异常模式和图像通道。有关更多信息,请访问 |
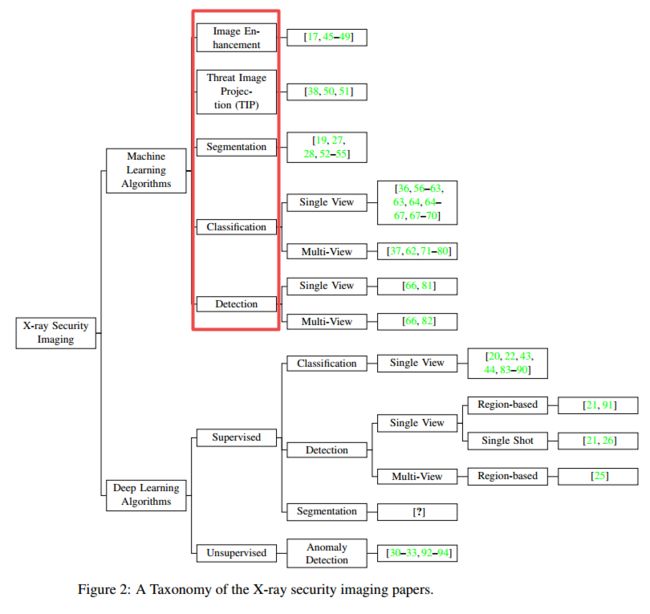
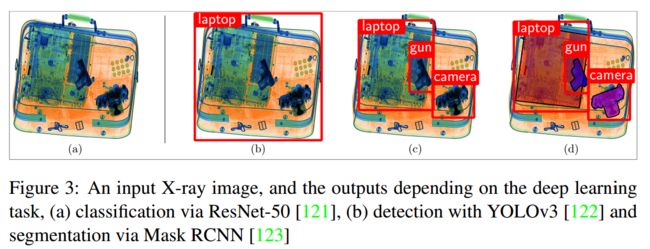
| Towards Automatic Threat Detection: A Survey of Advances of Deep Learning within X-ray Security Imaging Authors Samet Akcay, Toby Breckon X射线安全检查被广泛用于维护航空运输的安全,其重要性引起了对自动检查系统的特别关注。本文旨在通过将领域分类为常规机器学习和当代深度学习应用程序来回顾计算机化X射线安全成像算法。第一部分简要讨论了X射线安全成像中使用的经典机器学习方法,而后一部分则彻底研究了现代深度学习算法的使用。拟议的分类法将深度学习方法的使用分类为有监督,半监督和无监督学习,特别着重于对象分类,检测,分割和异常检测任务。本文进一步探索了完善的X射线数据集并提供了性能基准。基于深度学习的当前和未来趋势,本文最终提出了有关X射线安全图像的讨论和未来方向。 |
| General Partial Label Learning via Dual Bipartite Graph Autoencoder Authors Brian Chen, Bo Wu, Alireza Zareian, Hanwang Zhang, Shih Fu Chang 我们提出了一个实际却充满挑战的问题:通用部分标签学习GPLL。与传统的“部分标签学习PLL”问题相比,GPLL放宽了从实例级别的监督假设,即标签集部分标记了一个实例到组级别1,标签集部分标记了一组实例,其中缺少组内实例标签链接注释,和2个跨组链接是允许的,一个组中的实例可以部分链接到另一个组中的标签集。由于不再需要在实例级别上附加注释,因此这种模棱两可的组级别监督在现实世界中更加实用,例如,视频中的人脸命名,其中该组由框架中的人脸组成,并在相应的标题中设置了名称。在本文中,我们提出了一种新颖的图卷积网络GCN,称为双重二分图自动编码器DB GAE,以解决GPLL的标签歧义性挑战。首先,我们利用交叉组相关性将实例组表示为组和交叉组内的双二部图,它们互为补充,以解决链接歧义。其次,我们设计了一个GCN自动编码器来对其进行编码和解码,其中解码被视为经过改进的结果。值得注意的是,DB GAE是自我监督和转换的,因为它仅使用组级别监督,而没有单独的脱机培训阶段。在两个真实世界的数据集上进行的大量实验表明,在绝对的0.159 F1得分和24.8的准确性上,DB GAE明显优于最佳基准。我们进一步提供各种级别的标签歧义度分析。 |
| Learning Global and Local Consistent Representations for Unsupervised Image Retrieval via Deep Graph Diffusion Networks Authors Zhiyong Dou, Haotian Cui, Bo Wang 通过利用图像流形的高阶结构,扩散在提高无监督图像检索系统的准确性方面显示出巨大的成功。但是,现有的扩散方法有三个主要局限性:1他们通常依赖局部结构而不考虑全局流形信息2他们专注于改进现有图像输入输出输出中的成对相似性,而缺乏灵活性来归纳地学习新颖的未见实例的表示法3他们失败了由于过度的内存消耗和整个图的固有高阶运算所带来的计算负担,因此可以扩展到大型数据集。在本文中,为了解决这些局限性,我们提出了一种新的方法,即图扩散网络GRAD Net,它采用了图神经网络GNNs,这是一种针对不规则图的深度学习算法的新颖变体。 GRAD Net通过无监督地利用图像流形的局部和全局结构来学习语义表示。通过使用稀疏编码技术,GRAD Net不仅可以在图像流形上保留全局信息,还可以进行可扩展的训练和高效的查询。在几个大型基准数据集上进行的实验证明了我们的方法在无监督图像检索方面优于现有的扩散算法的有效性。 |
| Deep Transfer Convolutional Neural Network and Extreme Learning Machine for Lung Nodule Diagnosis on CT images Authors Xufeng Huang, Qiang Lei, Tingli Xie, Yahui Zhang, Zhen Hu, Qi Zhou 计算机断层扫描CT图像对肺部良性恶性结节的诊断对于确定肿瘤水平和降低患者死亡率至关重要。然而,由于深度结构的冗余和缺乏足够的训练数据,因此基于深度学习的肺部CT图像诊断诊断既费时又不准确。本文探索了一种基于深度转移卷积神经网络DTCNN和极限学习机ELM的诊断方法,该方法融合了两种算法的协同作用,以进行良性恶性结节的分类。首先采用最佳DTCNN提取肺结节的高级特征,该特征已事先通过ImageNet数据集进行了训练。此后,进一步开发了ELM分类器以对良性和恶性肺结节进行分类。为了验证该方法的有效性和有效性,我们进行了两个数据集,包括肺图像数据库联盟和图像数据库资源倡议LIDC IDRI公共数据集以及来自中国广州医科大学附属第一医院的私人数据集。实验结果表明,与当前的最新方法相比,我们新颖的DTCNN ELM模型提供了最可靠的结果。 |
| Automated Segmentation of Vertebrae on Lateral Chest Radiography Using Deep Learning Authors Sanket Badhe, Varun Singh, Joy Li, Paras Lakhani 这项研究的目的是开发一种使用深度学习在胸部X光片上进行胸椎分割的自动算法。获得了124例针对独特患者的侧位胸部X光片。可见椎骨的分割是由一名医学生手动进行的,并由一名经过董事会认证的放射科医生进行了验证。 74张图像用于训练,10张用于验证,40张用于测试。利用骰子系数和二进制交叉熵之和作为损失函数,采用U Net深度卷积神经网络进行分割。在测试集上,该算法显示出平均骰子系数值为90.5,并且在联合IoU上的平均交集为81.75。深度学习在胸部X光片的椎骨分割中显示出希望。 |
| Self-Orthogonality Module: A Network Architecture Plug-in for Learning Orthogonal Filters Authors Ziming Zhang, Wenchi Ma, Yuanwei Wu, Guanghui Wang 在本文中,我们研究了正交正则化OR对深度学习(无论是单独还是协作)的经验影响。最近关于OR的工作在准确性上显示了一些有希望的结果。但是,在我们的消融研究中,与基于体重下降,脱落和批次归一化的常规训练相比,我们没有观察到现有OR技术的显着改善。为了从角度估计中受局部敏感哈希LSH启发,从OR中识别出真正的收益,我们建议在OR中引入隐式自正则化,以将网络中滤波器角度的均值和方差同时推向90和0,以实现接近正交过滤器之间,而无需使用任何其他显式正则化。我们的正则化可以实现为体系结构插件,并且可以与任意网络集成。我们发现OR有助于稳定训练过程并导致更快的收敛和更好的泛化。 |
| FDFtNet: Facing Off Fake Images using Fake Detection Fine-tuning Network Authors Hyeonseong Jeon, Youngoh Bang, Simon S. Woo 由于生成对抗网络GAN的发展,如今创建虚假图像和视频(例如Deepfake)变得更加容易。此外,最近的研究(例如少量镜头学习)可以仅使用少量图像来创建高度逼真的个性化假图像。因此,Deepfake被用于传播恶意图像和视频等各种恶意意图的威胁日益普遍。而且检测这些机器生成的伪造图像比以往任何时候都更具挑战性。在这项工作中,我们提出了一种基于轻量级鲁棒微调神经网络的分类器架构,称为伪造检测微调网络FDFtNet,它能够检测许多新的伪造人脸图像生成模型,并且可以轻松地与现有图像分类网络结合使用。并在一些数据集上进行了微调。与许多现有方法相比,我们的方法旨在仅使用少量图像来重用流行的预训练模型,以进行微调以有效检测假图像。我们方法的核心是引入一个基于图像的自我关注模块,称为Fine Tune Transformer,该模块仅使用关注模块和向下采样层。该模块被添加到训练有素的模型中,并对一些数据进行微调,以搜索新的特征空间集以检测伪图像。我们在基于GANs的数据集Progressive Growing GAN和基于Deepfake的数据集Deepfake和Face2Face上使用FDFtNet进行了实验,并以64x64的小输入图像分辨率使检测复杂化。我们的FDFtNet在检测从基于GAN的数据集生成的伪造图像方面达到90.29的总体准确度,性能超过了现有技术。 |
| A Robust Pose Transformational GAN for Pose Guided Person Image Synthesis Authors Arnab Karmakar, Deepak Mishra 生成任何看不见的姿势的人类对象的逼真的图像在生成对象的完整外观模型中具有至关重要的应用。但是,从计算机视觉的角度来看,由于无法对基于姿势的数据分布进行建模,因此此任务变得非常具有挑战性。现有作品使用具有各种附加功能(例如前景分割,人体解析等)的复杂姿态转换模型来实现鲁棒性,从而导致计算开销。在这项工作中,我们提出一种利用残差学习方法的简单而有效的姿势变换GAN,而无需进行任何额外的特征学习就可以以任意姿势生成给定的人像。使用有效的数据增强技术并巧妙地调整模型,我们在照明,遮挡,失真和缩放方面实现了鲁棒性。我们提出了定性和定量的详细研究,以证明我们的模型在两个大型数据集上优于现有方法的优越性。 |
| Exploiting Event-Driven Cameras for Spatio-Temporal Prediction of Fast-Changing Trajectories Authors Marco Monforte, Ander Arriandiaga, Arren Glover, Chiara Bartolozzi 本文研究了机器人技术中人工智能轨迹预测问题的解决方案,以改善运动目标的拦截,例如接住弹跳球。意外的,高度非线性的轨迹无法轻松地通过基于回归的预测来解决,因此,我们寻求学习方法。此外,使用最新的事件摄像机可以更好地检测快速移动的目标,该事件摄像机会产生由空间变化触发的异步输出,而不是像传统摄像机那样是固定时间段。我们研究了LSTM模型如何适用于事件摄像机数据,特别是与同步采样方法相比,使用异步数据的好处。 |
| Cooperative Initialization based Deep Neural Network Training Authors Pravendra Singh, Munender Varshney, Vinay P. Namboodiri 研究人员提出了各种激活功能。这些激活功能可帮助深度网络学习非线性行为,从而对训练动力学和任务性能产生重大影响。这些激活的性能还取决于权重参数的初始状态,即,不同的初始状态导致网络性能的差异。在本文中,我们提出了一种协作初始化,以使用ReLU激活函数来训练深度网络,以提高网络性能。我们的方法在训练网络的最初几个时期使用了多个激活函数来更新所有重量参数集。这些激活功能共同克服了权重参数更新方面的弊端,从而有效地学习了更好的特征表示并在以后提高了网络性能。基于协作初始化的培训还有助于减少过拟合问题,并且不会增加参数的数量,不会在最终模型中推断测试时间,同时还能提高性能。实验表明,我们的方法优于各种基准,并且同时在各种任务(例如分类和检测)上表现良好。在CIFAR 100数据集上,使用我们的方法训练的模型的前1个分类准确度对于VGG 16提高了2.8,对于ResNet 56提高了2.1。 |
| EcoNAS: Finding Proxies for Economical Neural Architecture Search Authors Dongzhan Zhou, Xinchi Zhou, Wenwei Zhang, Chen Change Loy, Shuai Yi, Xuesen Zhang, Wanli Ouyang 神经体系结构搜索NAS在许多计算机视觉任务中均取得了重大进展。虽然已经提出了许多方法来提高NAS的效率,但是搜索进度仍然很费力,因为在较大的搜索空间上训练和评估合理的架构非常耗时。因此,在代理下,即在计算上减少了设置的情况下评估网络候选者变得不可避免。在本文中,我们观察到大多数现有代理在维持网络候选者之间的等级一致性方面表现出不同的行为。特别是,某些代理人可能会更可靠,与降低的设置表现和最终表现相比,候选者的排名相差无几。在本文中,我们系统地研究了一些被广泛采用的还原因子,并报告了我们的观察结果。受这些观察的启发,我们提出了可靠的代理,并进一步制定了分层代理策略。该策略在可能更准确的候选网络上花费了更多的计算,而在早期使用快速代理丢弃了没有希望的计算。这导致了基于经济的基于进化的NAS EcoNAS,与基于进化的8或3150 GPU天相比,可显着减少400倍的搜索时间。我们的观察结果导致的一些新代理也可以用于加速其他NAS方法,同时仍然能够发现性能与以前的代理策略所发现的性能相匹配的良好候选网络。 |
| Spatial-Scale Aligned Network for Fine-Grained Recognition Authors Lizhao Gao, Haihua Xu, Chong Sun, Junling Liu, Yu Wing Tai 现有的用于细粒度视觉识别的方法着重于学习基于边缘区域的表示,同时忽略空间和比例失调,从而导致性能下降。在本文中,我们提出了空间尺度对齐网络SSANET,并隐式地解决了识别过程中的不对齐问题。特别是,SSANET包括1具有形态对齐约束的自我监督提议挖掘公式2具有判别性的尺度挖掘DSM模块,它通过循环矩阵利用特征金字塔,并提供用于快速尺度对齐的傅立叶求解器3定向池化OP模块,在几个预定义的方向上执行池化操作。每个方向都定义一种空间对齐方式,并且网络会通过学习自动确定哪种是最佳对齐方式。借助提出的两个模块,我们的算法可以自动确定准确的本地提议区域,并生成不依赖于各种外观差异的更可靠的目标表示。大量实验证明,SSANET能够胜任更好的空间尺度不变目标表示,在多个基准上的细粒度识别任务中表现出卓越的性能。 |
| Informative Sample Mining Network for Multi-Domain Image-to-Image Translation Authors Jie Cao, Huaibo Huang, Yi Li, Ran He, Zhenan Sun 深度生成模型的最新进展显着提高了多域图像到图像翻译的性能。现有方法可以使用统一模型来实现所有视觉域之间的转换。但是,当域差异较大时,其结果远不能令人满意。在本文中,我们发现改进样本选择策略是一种有效的解决方案。为了选择信息样本,我们在生成对抗性网络的过程中动态估计样本重要性,并提供信息样本挖掘网络。我们从理论上分析了样本重要性与全局最优判别器预测之间的关系。然后推导了基于通用判别器的实用重要性估计函数。此外,我们提出了一种新颖的多阶段样本训练方案,以在保持样本信息量的同时降低样本硬度。在广泛的特定图像到图像翻译任务上进行了广泛的实验,结果证明了我们比当前最先进的方法优越。 |
| The Human Visual System and Adversarial AI Authors Yaoshiang Ho, Samuel Wookey 本文将现有关于人类视觉系统的研究引入对抗性AI。迄今为止,对抗AI已使用L1,L2,L0和L无穷大范数建模了干净图像与对抗图像之间的差异。当在对抗性AI的背景下应用于图像时,这些规范具有易于数学解释和独特的视觉表示的优势。然而,在过去的几十年中,图像处理的其他现有领域已经从简单的数学模型(例如均方误差MSE)转向了更多地理解人类视觉系统HVS的模型。我们演示了将HVS整合到Adversarial AI中的概念证明,并希望激发更多的研究将HVS整合到Adversarial AI中。 |
| Spatio-Temporal Relation and Attention Learning for Facial Action Unit Detection Authors Zhiwen Shao, Lixin Zou, Jianfei Cai, Yunsheng Wu, Lizhuang Ma 面部动作单元之间的时空关系AU传达了用于AU检测的重要信息,但尚未得到充分利用。主要原因是当前的AU检测工作无法同时学习空间和时间关系,并且缺乏用于AU特征学习的精确定位信息的能力有限。为了解决这些限制,我们提出了一种新颖的时空关系和注意力学习框架来进行AU检测。具体来说,我们引入了一个时空图卷积网络来捕获动态AU的空间和时间关系,其中AU关系被公式化为具有自适应学习的时空图,而不是预定义的边缘权重。而且,对AU之间的时空关系的学习需要各个AU特征。考虑到AU的动态性和形状不规则性,我们提出了一种注意力正则化方法,以自适应地学习捕获高度相关区域并抑制不相关区域的区域注意,从而为每个AU提取一个完整的特征。大量实验表明,我们的方法相对于BP4D尤其是DISFA基准测试中最先进的AU检测方法取得了显着改进。 |
| End-To-End Trainable Video Super-Resolution Based on a New Mechanism for Implicit Motion Estimation and Compensation Authors Xiaohong Liu, Lingshi Kong, Yang Zhou, Jiying Zhao, Jun Chen 视频超分辨率旨在从其低分辨率对应对象生成高分辨率视频。随着深度学习的迅速兴起,许多最近提出的视频超分辨率方法将卷积神经网络与显式运动补偿结合使用,以利用低分辨率帧内和跨低分辨率帧的统计依赖性。这种方法的两个常见问题值得注意。首先,最终重建的HR视频的质量通常对运动估计的准确性非常敏感。其次,运动补偿所需的翘曲网格由两个流图所指定,描绘了水平和垂直方向上的像素位移,这往往会引入额外的误差并危及视频帧之间的时间一致性。为了解决这些问题,我们提出了一种新颖的动态局部滤波器网络,该方法通过经由局部连接的层采用针对目标像素量身定制的特定于样本和特定于位置的动态局部滤波器来执行隐式运动估计和补偿。我们还提出了一个基于ResBlock和自动编码器结构的全局优化网络,以利用非局部相关性并增强超分辨帧的空间一致性。实验结果表明,所提出的方法优于现有技术,并在局部变换处理,时间一致性以及边缘清晰度方面验证了其强度。 |
| TCM-ICP: Transformation Compatibility Measure for Registering Multiple LIDAR Scans Authors Aby Thomas, Adarsh Sunilkumar, Shankar Shylesh, Aby Abahai T., Subhasree Methirumangalath, Dong Chen, Jiju Peethambaran 多视图和多平台LiDAR扫描的刚性配准是3D映射,机器人导航和大规模城市建模应用程序中的一个基本问题。使用LiDAR传感器进行数据采集涉及从不同角度扫描多个区域,从而生成现实世界场景中部分重叠的点云。传统上,ICP迭代最近点算法用于将采集的点云注册在一起,以形成捕获扫描的现实世界场景的唯一点云。常规ICP面临局部极小问题,并且通常需要粗略的初始对齐才能收敛到最佳状态。在这项工作中,我们提出了一种用于注册多个重叠的LiDAR扫描的算法。我们介绍了一种称为“转换兼容性度量” TCM的几何度量,该度量可帮助选择最相似的点云以在算法的每次迭代中进行配准。然后,使用单工技术转换与参考LiDAR扫描最相似的LiDAR扫描。然后使用梯度下降和模拟退火技术对转换进行优化,以改善所得配准。我们在四个不同的真实世界场景上评估了该算法,实验结果表明该方法的注册性能与传统的注册方法相当或优于传统的注册方法。此外,即使在处理离群值时,该算法也可以获得出色的配准结果。 |
| COPD Classification in CT Images Using a 3D Convolutional Neural Network Authors Jalil Ahmed, Sulaiman Vesal, Felix Durlak, Rainer Kaergel, Nishant Ravikumar, Martine Remy Jardin, Andreas Maier 慢性阻塞性肺疾病COPD是一种不能完全逆转的肺部疾病,是世界上发病率和死亡率的主要原因之一。早期发现和诊断COPD可以提高患者的生存率并降低COPD进展的风险。当前,诊断COPD的主要检查工具是肺活量测定法。但是,计算机断层扫描CT用于检测COPD的症状和亚型分类。即使对于医生来说,使用不同的成像方式也是一项艰巨而繁琐的任务,并且受观察者之间和观察者之间差异的影响。因此,开发能够自动将COPD与健康患者进行分类的方法引起了人们的极大兴趣。在本文中,我们提出了一种3D深度学习方法,仅使用体积明智的注释对COPD和肺气肿进行分类。我们还演示了使用来自预先培训的COPD分类模型的知识转移,可以将迁移学习对肺气肿分类的影响。 |
| Represented Value Function Approach for Large Scale Multi Agent Reinforcement Learning Authors Weiya Ren 在本文中,我们考虑了大规模多主体强化学习的问题。首先,我们研究了成对值函数的表示问题,以减少代理之间交互的复杂性。其次,我们采用l2范数技巧来确保近似值函数的琐碎项是有界的。第三,对战游戏的实验结果证明了该方法的有效性。 |
| RPR: Random Partition Relaxation for Training; Binary and Ternary Weight Neural Networks Authors Lukas Cavigelli, Luca Benini 我们提出了随机分区松弛RPR,这是一种将神经网络权重量化为二进制1 1和三进制1 0 1的方法。从预先训练的模型开始,我们对权重进行量化,然后将它们的随机分区放宽到其连续值以进行再训练,然后再对其进行重新量化并切换到另一个权重分区以进行进一步调整。我们使用基于SGD的训练方法演示了二元和三元权重网络,其精度超出了GoogLeNet的技术水平,并具有ResNet 18和ResNet 50的竞争性能,可以轻松地集成到现有框架中。 |
| Res3ATN -- Deep 3D Residual Attention Network for Hand Gesture Recognition in Videos Authors Naina Dhingra, Andreas Kunz 手势识别是视频中要解决的艰巨任务。在本文中,我们使用了3D残差注意力网络,该网络经过端到端训练以用于手势识别。基于堆叠的多个关注区域,我们构建了一个3D网络,该网络在每个关注区域生成不同的功能。可以构建基于3D注意的残差网络Res3ATN,并将其扩展到非常深的层。使用此网络,可以基于三个公共可用数据集在其他3D网络上进行广泛的分析。将Res3ATN网络性能与C3D,ResNet 10和ResNext 101网络进行比较。我们还将研究和评估具有不同数量关注点的基线网络。比较表明,具有3个注意块的3D残留注意网络在注意学习方面具有较强的鲁棒性,并且能够对手势进行更好的分类,从而胜过现有网络。 |
| Pixel-Semantic Revise of Position Learning A One-Stage Object Detector with A Shared Encoder-Decoder Authors Qian Li, Nan Guo, Xiaochun Ye, Dongrui Fan, Zhimin Tang, Honggang Chen, Wenming Li 我们分析,基于通道或位置注意机制的不同方法在规模上会产生不同的性能,并且应用了特征金字塔的一些最新检测器与各种变体卷积集成在一起,并具有多种机制来增强信息,从而增加了运行时间。这项工作通过构造具有共享模块的无锚检测器解决了这个问题,该共享模块由具有注意机制的编码器和解码器组成。首先,我们将与主干网不同的级别功能(例如ResNet 50)视为基本功能。其次,将特征输入一个简单的块中,而不是进行各种复杂的操作,然后分别通过探测器头和分类器获得位置和分类任务。同时,我们使用语义信息来修改几何位置。此外,我们表明检测器是位置的像素语义修改,通用,有效且易于检测,尤其是大型物体。更重要的是,这项工作比较了不同特征处理,例如,整个通道的平均,最大或最小性能。最后,我们提出,与在标准MSCOCO基线上基于MNC的ResNet 101相比,我们的方法将检测精度提高了3.8 AP。 |
| Discrimination-aware Network Pruning for Deep Model Compression Authors Jing Liu, Bohan Zhuang, Zhuangwei Zhuang, Yong Guo, Junzhou Huang, Jinhui Zhu, Mingkui Tan 我们研究网络修剪,该修剪旨在删除冗余通道内核,从而加快对深层网络的推断。现有的修剪方法要么具有稀疏性约束而从头开始训练,要么使预训练模型的特征图与压缩模型的特征图之间的重构误差最小。两种策略都有一些局限性,前一种算法计算量大且难以收敛,而后一种优化重构误差,却忽略了信道的判别能力。在本文中,我们提出了一种简单而有效的方法,称为“区分歧视的信道修剪DCP”,以选择实际上有助于区分能力的信道。请注意,通道通常由一组内核组成。除了通道中的冗余之外,通道中的某些内核也可能是冗余的,并且无法对网络的判别能力作出贡献,从而导致内核级冗余。为了解决这个问题,我们提出了一种区分歧视的内核修剪DKP方法,以通过删除冗余内核来进一步压缩深度网络。为了防止DCP DKP选择冗余通道内核,我们提出了一种新的自适应停止条件,该条件可以自动确定所选通道内核的数量,并且通常会导致具有更好性能的更紧凑模型。在图像分类和面部识别方面的大量实验证明了我们方法的有效性。例如,在ILSVRC 12上,最终减少30个通道的ResNet 50模型甚至比基线模型的Top 1精度要高0.36。修剪后的MobileNetV1和MobileNetV2在移动设备上分别实现1.93倍和1.42倍的推理加速,而性能下降可忽略不计。可以在以下位置获得源代码和经过预先训练的模型 |
| Adversarial-Learned Loss for Domain Adaptation Authors Minghao Chen, Shuai Zhao, Haifeng Liu, Deng Cai 最近,在跨域学习可转移表示方面已取得了显着进步。领域适应的先前工作主要基于领域对抗学习和自我训练这两种技术。但是,领域对抗性学习仅使领域之间的特征分布对齐,而不考虑目标特征是否具有歧视性。另一方面,自我训练利用模型预测来增强对目标特征的辨别力,但无法显式对齐域分布。为了结合这两种方法的优势,我们提出了一种新的方法,称为“针对域自适应ALDA的对抗性学习损失”。我们首先分析伪标签方法,这是一种典型的自我训练方法。但是,伪标签与基本事实之间仍然存在差距,这可能会导致错误的训练。因此,我们引入了混淆矩阵,该矩阵通过在ALDA中通过对抗的方式来学习,以减小间隙并对齐特征分布。最后,从学习到的混淆矩阵中自动构建一个新的损失函数,该函数用作未标记目标样本的损失。我们的ALDA在四个标准域适应数据集中的表现均优于最新方法。我们的代码位于 |
| Understanding Image Captioning Models beyond Visualizing Attention Authors Jiamei Sun, Sebastian Lapuschkin, Wojciech Samek, Alexander Binder 本文解释了除了视觉化注意力本身之外,具有注意力机制的图像字幕模型的预测。在本文中,我们开发了分层明智相关反向传播LRP和梯度反向传播的变体,专门针对图像字幕而设计。结果同时为字幕中的每个单词提供了逐像素图像解释和语言解释。我们显示给定标题中要解释的单词,诸如LRP的解释方法会显示支持和相对像素以及单词。我们将注意力热图的属性与通过解释方法(例如LRP,Grad CAM和Guided Grad CAM)计算出的属性进行系统比较。我们证明了解释方法,首先,与注意力相比,其与对象位置的关联度更高,其次,它能够识别出不受图像内容支持的对象词,其次,可为消除偏见提供指导并改进模型。报告了使用Flickr30K和MSCOCO2017数据集训练的两种不同注意力模型进行图像字幕的结果。实验分析表明,解释方法可以帮助理解图像字幕注意模型。 |
| FrequentNet : A New Deep Learning Baseline for Image Classification Authors Yifei Li, Zheng Wang, Kuangyan Song, Yiming Sun 在本文中,我们从称为PCANet的方法中概括了这一思想,以实现用于图像分类的新基线深度学习模型。代替在PCANet中使用主成分向量作为滤波向量,我们在离散傅里叶分析和小波分析中使用基础向量作为滤波向量。两者在基准数据集中均达到了与PCANet相当的性能。值得注意的是,我们的算法不需要任何优化技术即可获得这些基础。 |
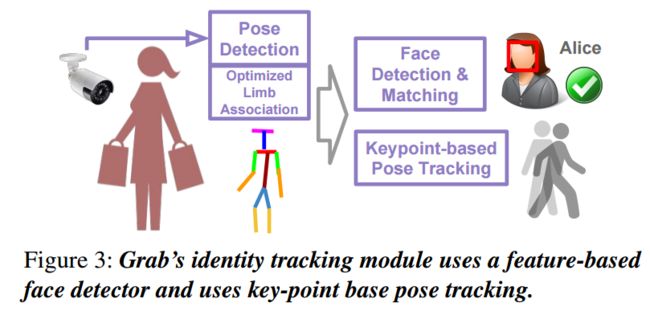
| Grab: Fast and Accurate Sensor Processing for Cashier-Free Shopping Authors Xiaochen Liu, Yurong Jiang, Kyu Han Kim, Ramesh Govindan 像Amazon Go这样的免费收银购物系统可以改善购物体验,但是可能需要重新设计商店。在本文中,我们提出了Grab,这是一个利用现有基础架构和设备来实现收银员免费购物的实用系统。 Grab需要准确地识别和跟踪客户,并将每个购物者与他或她从货架上取回的物品相关联。为此,它使用基于关键点的姿势跟踪器作为识别和跟踪的构建块,开发基于鲁棒特征的面部跟踪器以及用于关联和跟踪手臂运动的算法。它还使用概率框架融合来自相机,重量和RFID传感器的读数,以便准确评估哪个购物者捡起哪个物品。在零售商店进行试点部署的实验中,Grab可以实现90多种精度,并且即使设计了40种购物动作来使系统感到困惑,Grab仍可以实现召回。此外,Grab进行了优化,可将计算基础设施的投资减少四倍。 |
| Segmentation-Aware and Adaptive Iris Recognition Authors Kuo Wang, Ajay Kumar 虹膜识别已成为人类识别的最准确,最方便的生物特征之一,并已越来越广泛地应用于各种电子安全应用中。已知在远处或在较少约束的成像环境下获取的虹膜图像的质量会降低虹膜匹配精度。眼周信息固有地嵌入在这种虹膜图像中,并且可以被利用来在这种非理想情况下辅助虹膜识别。我们对这种虹膜模板的分析还表明,在感兴趣区域中虹膜识别可以从相似距离中受益,而该相似距离可以考虑不同二进制位的重要性,而不是在文献中直接使用汉明距离,因此虹膜识别可以从相关区域中显着降低。通过合并可用虹膜区域有效区域中的差异,可以动态增强眼周信息,以实现更准确的虹膜识别。本文提出了这样一种分割辅助的自适应框架,用于更准确,不受约束的虹膜识别。使用三个数据集内和跨数据集性能评估,在三个可公开获取的虹膜数据库上评估了该框架的有效性,并验证了所提出的虹膜识别框架的优点。 |
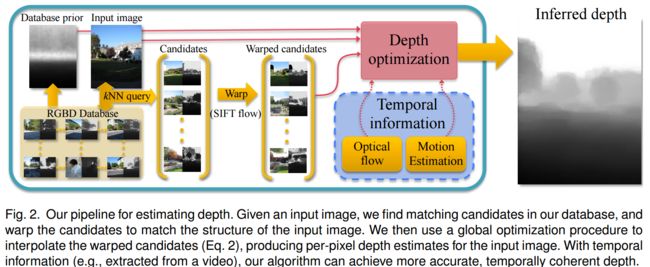
| DepthTransfer: Depth Extraction from Video Using Non-parametric Sampling Authors Kevin Karsch, Ce Liu, Sing Bing Kang 我们描述了一种使用非参数深度采样从视频自动生成合理的深度图的技术。在过去的方法无法平移相机和动态场景而失败的情况下,我们将演示我们的技术。我们的技术适用于单个图像以及视频。对于视频,我们使用局部运动提示来改善推断的深度图,同时使用光流来确保时间深度的一致性。为了进行培训和评估,我们使用基于Kinect的系统来收集包含已知深度的立体视频的大型数据集。我们表明,我们的深度估计技术优于基准数据库上的最新技术。我们的技术可用于自动将单视场视频转换为立体声以进行3D可视化,并且我们通过各种室内和室外场景的视觉效果(包括故事片Charade的效果)进行演示。 |
| Inverse Rendering Techniques for Physically Grounded Image Editing Authors Kevin Karsch 从一幅场景的单个图片中,人们通常可以立即掌握空间布局,甚至可以很好地猜测材料的属性以及光线从何处照射场景。例如,我们可以可靠地分辨出哪些物体遮挡了其他物体,该物体是由什么构成的,其粗糙的形状,被照明或阴影的区域等等。有趣的是,人们对我们做出这些决定的能力知之甚少,我们仍然无法稳健地教导计算机进行与人类相同的高级观察。本文档介绍了用于从单个图像理解固有场景属性的算法。这些逆渲染技术的目标是仅使用图像中可见的信息来估计场景元素的几何形状,材料,灯具,相机参数等的配置。这样的算法在机器人技术和计算机图形学中具有应用。一种这样的应用是在物理基础上的图像编辑中,通过利用物理空间的知识使照片编辑更加容易。这些应用程序允许在几秒钟内执行复杂的编辑操作,从而可以无缝添加,删除或重新放置图像中的对象。 |
| A Deep Neuro-Fuzzy Network for Image Classification Authors Omolbanin Yazdanbakhsh, Scott Dick 将神经网络和模糊系统组合成神经模糊系统,将模糊推理规则集成到连接网络中。然而,现有的神经模糊系统是在具有较低泛化能力的浅层结构下开发的。我们提出了首个端到端的深度神经模糊网络,并研究了其在图像分类中的应用。根据Takagi Sugeno Kang TSK模糊模型的定义,开发了两个新的运算,即模糊推理运算和这些运算的模糊池运算堆栈构成了该网络中的各层。我们在MNIST,CIFAR 10和CIFAR 100数据集上评估了网络,发现该网络在这些基准测试中具有合理的准确性。 |
| A Hybrid Approach to Temporal Pattern Matching Authors Konstantinos Semertzidis, Evaggelia Pitoura 图形模式匹配的主要目标是在大型数据图形中查找输入图形模式查询的所有外观。这种出现称为比赛。在本文中,我们感兴趣的是找到时间图中交互模式的匹配。为此,我们提出了一种混合方法,该方法可同时基于结构和时间实现对潜在匹配项的有效过滤。我们的方法利用图形表示,其中边缘按时间排序。我们使用真实的数据集进行实验,这些数据集说明了我们方法的效率。 |
| Opportunities and Challenges in Deep Learning Methods on Electrocardiogram Data: A Systematic Review Authors Shenda Hong, Yuxi Zhou, Junyuan Shang, Cao Xiao, Jimeng Sun 目的从模型架构及其应用任务的角度对心电图心电图数据的深度学习方法进行系统的综述。方法首先,我们广泛搜索了在2010年1月1日至2019年9月30日期间由Google Scholar,PubMed和DBLP发布的关于ECG数据的深度学习深度神经网络网络部署论文。然后从任务,模型和数据三个方面对它们进行分析。最后,我们总结了现有模型无法很好解决的未解决的挑战和问题。结果论文总数为124篇,其中近两年后发表论文97篇。几乎所有常见的深度学习架构都已用于ECG分析任务,例如疾病检测分类,注释定位,睡眠阶段,生物特征识别,去噪等。结论近年来,有关ECG数据深度学习的著作数量呈爆炸式增长。确实,这些作品在准确性方面取得了更好的性能。但是,存在一些新的挑战和问题,例如可解释性,可伸缩性,效率,这些问题都需要解决并引起更多关注。此外,还值得通过从数据集视图和方法视图中发现新的有趣应用程序进行研究。意义本文从多种角度总结了现有的深度学习方法,用于心电图数据建模,同时指出了现有的挑战和问题,同时也可能成为未来的潜在研究方向。 |
| Deeper Insights into Weight Sharing in Neural Architecture Search Authors Yuge Zhang, Zejun Lin, Junyang Jiang, Quanlu Zhang, Yujing Wang, Hui Xue, Chen Zhang, Yaming Yang 随着深度神经网络的成功,作为自动模型设计方法的神经体系结构搜索NAS引起了广泛关注。由于从头开始训练每个子模型非常耗时,因此最近的工作利用权重分配来加快模型评估过程。这些方法通过在超级网上维护权重的单个副本并在每个子模型之间共享权重,从而大大减少了计算。但是,重量分配没有理论上的保证,其影响以前还没有得到很好的研究。在本文中,我们进行了全面的实验以揭示权重分配的影响1来自不同运行或什至来自同一运行的连续时期的最佳性能模型具有显着的方差2即使存在高方差,我们也可以从训练超级运动中提取有价值的信息权重共享的净值3子模型之间的干扰是导致高方差的主要因素。4适当降低权重分配的程度可以有效地减少方差并提高性能。 |
| Classification of Large-Scale High-Resolution SAR Images with Deep Transfer Learning Authors Zhongling Huang, Corneliu Octavian Dumitru, Zongxu Pan, Bin Lei, Mihai Datcu 卫星获取的高分辨率高分辨率SAR地面覆盖图像的分类是一项艰巨的任务,面临许多困难,例如具有专业知识的语义注释,由于成像参数变化或区域目标区域差异而导致的数据特征变化以及复杂的散射机制不同于光学成像。鉴于从TerraSAR X图像收集的大规模SAR土地覆盖数据集具有150个类别的分层三级注释,包括100,000多个补丁,解决了自动解释高度失衡类别,地理多样性和标签噪声的SAR图像的三个主要挑战。 。在这封信中,提出了一种基于类似注释的光学土地覆盖数据集NWPU RESISC45的深度转移学习方法。此外,引入了具有成本敏感参数的前2个平滑损失函数,以解决标签噪声和类别不平衡的问题。所提出的方法在从类似注释的遥感数据集传输信息方面显示出很高的效率,在高度不平衡的类上具有鲁棒的性能,并且减轻了由标签噪声引起的过拟合问题。此外,学习的深度模型对其他SAR特定任务具有良好的概括性,例如MSTAR目标识别,其分类精度为99.46。 |
| Identifying and Compensating for Feature Deviation in Imbalanced Deep Learning Authors Han Jia Ye, Hong You Chen, De Chuan Zhan, Wei Lun Chao 我们调查学习如何使用类不平衡数据学习ConvNet分类器。我们发现,即使使用通用ERM进行训练,ConvNet仍然非常适合没有足够训练实例的次要课程。我们进行了一系列分析,并认为训练实例和测试实例之间的特征偏差是主要原因。我们建议在学习ConvNet CDT时将依赖于类的温度CDT纳入训练中,以迫使次要类实例在训练中具有较大的决策值,从而补偿测试中特征偏差的影响。我们在几个基准数据集上验证了我们的方法,并取得了可喜的结果。我们的研究进一步表明,班级失衡数据以非常不同的方式影响传统的机器学习和最近的深度学习。我们希望我们的见解可以启发新的思维方式来解决班级不平衡的深度学习。 |
| The troublesome kernel: why deep learning for inverse problems is typically unstable Authors Nina M. Gottschling, Vegard Antun, Ben Adcock, Anders C. Hansen 有大量的经验证据表明,深度学习DL导致从图像分类和计算机视觉到医学中的语音识别和自动诊断的应用中不稳定的方法。最近,当使用DL解决计算科学中的某些问题(即成像中的逆问题)时,已经发现了类似的不稳定性现象。在本文中,我们提供了全面的数学分析,解释了逆问题中DL不稳定现象的许多方面。我们的主要结果不仅解释了为什么会发生这种现象,而且还阐明了为什么在实践中很难找到治愈不稳定的方法。此外,这些定理表明,不稳定性通常不是罕见事件,即使测量受到完全随机噪声的影响,不稳定性也可能发生,因此破坏某些受过训练的神经网络的稳定性有多容易。我们还研究了重建性能与稳定性之间的微妙平衡,尤其是DL方法如何能胜过现有的稀疏正则化方法,但要以不稳定为代价。最后,我们证明了训练神经网络的反直觉现象通常可能无法产生针对反问题的最佳重构方法。 |
| Biologically-Motivated Deep Learning Method using Hierarchical Competitive Learning Authors Takashi Shinozaki 这项研究提出了一种新的深度卷积神经网络CNN的生物动机学习方法。 CNN和反向传播BP学习的结合是最近机器学习方案中最强大的方法。但是,它需要大量的标签数据来进行培训,并且该要求有时可能会成为现实应用程序的障碍。为了解决此问题并利用未标记的数据,我建议引入无监督竞争学习,该学习仅要求将正向传播信号作为CNN的预训练方法。该方法通过使用MNIST,CIFAR 10和ImageNet数据集的图像辨别任务进行了评估,并在ImageNet实验中作为生物学驱动的方法获得了最先进的性能。结果表明,该方法能够仅从正向传播信号实现高级学习表示,而无需向后误差信号来学习卷积层。所提出的方法对于各种标记较差的数据(例如时间序列或医学数据)可能很有用。 |
| Image Speckle Noise Denoising by a Multi-Layer Fusion Enhancement Method based on Block Matching and 3D Filtering Authors Huang Shuo, Zhou Ping, Shi Hao, Sun Yu, Wan Suiren 为了改善块匹配3d滤波BM3D方法的斑点噪声去噪,提出了一种基于非下采样contourlet变换NSCT的图像频域多层融合增强方法MLFE BM3D。该方法设计了一个NSCT硬阈值去噪增强来对图像进行预处理,然后在NSCT域中使用融合增强来融合NSCT硬阈值去噪前后的图像初步估计结果,最后对融合后的图像进行BM3D去噪,获得最终的去噪结果。在自然图像和医学超声图像上的实验表明,MLFE BM3D方法比BM3D方法具有更好的视觉效果,去噪图像的峰值信噪比PSNR提高了0.5dB。 MLFE BM3D方法可以改善纹理区域中斑点噪声的去噪效果,并且在图像的平滑区域中仍保持良好的去噪效果。 |
| Visual Semantic SLAM with Landmarks for Large-Scale Outdoor Environment Authors Zirui Zhao, Yijun Mao, Yan Ding, Pengju Ren, Nanning Zheng 语义SLAM是自动驾驶和智能代理中的重要领域,可以使机器人实现高级导航任务,获得简单的认知或推理能力并实现基于语言的人机交互。在本文中,我们构建了一个系统,该系统通过将ORB SLAM中的3D点云与卷积神经网络模型PSPNet 101中的语义分割信息相结合来创建大规模环境的语义3D地图。此外,还建立了一个新的KITTI序列数据集,其中包含GPS信息和序列相关街道中Google Map的地标标签。此外,我们找到了一种将现实世界地标与点云图关联的方法,并基于语义图构建了拓扑图。 |
| Painting Many Pasts: Synthesizing Time Lapse Videos of Paintings Authors Amy Zhao, Guha Balakrishnan, Kathleen M. Lewis, Fr do Durand, John V. Guttag, Adrian V. Dalca 我们引入了一个新的视频合成任务,该任务合成了延时视频,这些视频描述了如何绘制给定的绘画。艺术家使用画笔,描边,颜色和图层的独特组合进行绘画。通常有很多可能的方法来创建给定的绘画。我们的目标是学习捕捉这种丰富的可能性。 |
| Distributed Stochastic Algorithms for High-rate Streaming Principal Component Analysis Authors Haroon Raja, Waheed U. Bajwa 本文考虑了从流设置中的独立且均匀分布的数据样本中估计协方差矩阵的主特征向量的问题。在许多现代应用中,数据的流传输速率可能足够高,以致单个处理器无法在新样本到达之前完成现有特征向量估计方法的迭代。本文提出并分析了经典Krasulina方法D Krasulina的分布式变体,该方法可以通过在多个处理节点之间分配计算负载来跟上高数据流率。分析表明,在适当的条件下,D Krasulina以一种顺序最优的方式收敛到主特征向量,即在所有节点上接收M个样本后,其估计误差可以为O 1 M。为了减少网络通信开销,本文还开发并分析了D Krasulina的小批量扩展,称为DM Krasulina。 DM Krasulina的分析表明,即使由于通信延迟而不得不在网络内丢弃某些样本时,它也可以在适当的条件下实现阶次最优估计误差率。最后,对合成数据和现实世界数据进行了实验,以验证D Krasulina和DM Krasulina在高速率流设置中的收敛行为。 |
| Segmentation of Cellular Patterns in Confocal Images of Melanocytic Lesions in vivo via a Multiscale Encoder-Decoder Network (MED-Net) Authors Kivanc Kose, Alican Bozkurt, Christi Alessi Fox, Melissa Gill, Caterina Longo, Giovanni Pellacani, Jennifer Dy, Dana H. Brooks, Milind Rajadhyaksha 体内光学显微镜正在进入常规临床实践,以非侵入性方式指导癌症和其他疾病的诊断和治疗,从而开始减少传统活检的需要。然而,光学显微镜图像的读取和分析通常仍是定性的,主要依靠视觉检查。在这里,我们提出了一种称为多尺度编码器解码器网络MED Net的自动语义分割方法,该方法以定量方式将像素级标记提供给模式类别。我们方法的新颖之处在于可以在多个尺度上对纹理图案进行建模。这模仿了检查病理图像的过程,该过程通常从低放大率,低分辨率,大视野开始,然后以更高的放大率,更高分辨率,更小的视野仔细检查可疑区域。我们在117个反射性共聚焦显微镜检查的黑素细胞病变的RCM马赛克的非重叠分区上训练和测试了我们的模型,该模型是该应用程序的广泛数据集,在美国的四个诊所和意大利的两个诊所中收集。通过耐心的交叉验证,我们在六个类别上分别达到了像素级的平均灵敏度和特异性,分别为70 pm11和95 pm2,骰子系数为0.71 pm0.09。在这种情况下,我们明智地对数据诊所进行了划分,并在多个诊所中测试了该模型的可推广性。在这种设置下,我们获得了0.75 Dice系数的逐像素平均灵敏度和特异性分别为74和95。我们将MED Net与最先进的语义细分模型进行了比较,并获得了更好的定量细分性能。我们的结果还表明,由于其嵌套的多尺度体系结构,MED Net模型更加连贯地注释了RCM镶嵌图,避免了不切实际的零碎注释。 |
| Semi-supervised Classification using Attention-based Regularization on Coarse-resolution Data Authors Guruprasad Nayak, Rahul Ghosh, Xiaowei Jia, Varun Mithal, Vipin Kumar 在多种分辨率下可以观察到许多现实世界的现象。设计用来预测这些现象的预测模型通常分别考虑不同的分辨率。在需要以高分辨率进行预测但缺乏可用训练数据的应用中,这种方法可能会受到限制。在本文中,我们提出了分类算法,该算法利用较粗分辨率的监督来帮助训练较细分辨率的模型。在多视图框架中,将不同的分辨率建模为数据的不同视图,该框架利用不同视图之间功能的互补性来改进两个视图上的模型。与传统的多视图学习问题不同,在我们的案例中,关键的挑战是在我们的案例中,跨不同视图的实例之间没有一对一的对应关系,这需要对跨分辨率的实例对应关系进行显式建模。我们建议使用不同分辨率的实例特征来通过注意力机制来学习不同分辨率的实例之间的对应关系。通过卫星观测对城市区域进行地图绘制以及对文本数据进行情感分类的实际应用实验证明了所提出方法的有效性。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com