最近在 HireInTech 上学习了一门课程 System Design for Tech Interviews,做了一些笔记,中英结合。
课程介绍
In this course you will see what such system design interview questions look like and what is expected from you in order to solve them.
We'll teach you more about designing scalable software systems through examples. 如何设计一个可扩展的软件系统。
We will also teach you some strategies for presenting your knowledge and skills in the best possible way. 一些策略来最好的展示你的知识和技能。
What are system design questions? 什么是系统设计问题?
例如设计一个:
- Application
- Service
- API
几个示例:
- Design a URL shortening service like bit.ly. 设计一个短地址服务。
- How would you implement the Google search? 设计一个Google搜索应用。
- Design a client-server application which allows people to play chess with one another. 设计一个C/S架构的下棋应用。
- How would you store the relations in a social network like Facebook and implement a feature where one user receives notifications when their friends like the same things as they do? 如何存储社交网络的用户关系。
The idea of these questions is to have a discussion about the problem at hand. What’s important for the interviewer is the process, which you use to tackle the problem. 面试官看重的是过程,包括对问题的讨论,对问题的解决。
The typical outcome of such a discussion is a high-level architecture addressing the goals and constraints in the question. 系统设计类问题的典型输出是一个高层次的架构,能够对应到问题的目标及约束。
Remember that there is no one right answer. A system can be built in different ways. 没有一个明确的答案,可以从不同的角度,用不同的方式去设计。
Finally, keep in mind that the discussion about the same system design problem could go in different directions depending on the goals of the interviewer. They may be willing to see how you create a high-level architecture covering all aspects of the system. Or rather, they could be more interested in looking at a few specific areas and diving deeper into them. 对同一个系统设计问题的讨论可能会走向不同的方向。有的面试官会关注你如何构建一个高层次的架构,包括各个模块。有的面试官会关注某一个小的方面,并不断深入。
The System Design Process 系统设计的过程
Step 1: Constraints and use cases 约束及用例
The very first thing you should do with any system design question is to clarify the system's constraints and to identify what use cases the system needs to satisfy. 对于任何的系统设计问题,第一件事就是:明确系统的约束,识别用例。
Spend a few minutes questioning your interviewer and agreeing on the scope of the system. 花费几分钟向面试官提问,就系统的Scope达成一致。
Never assume things that were not explicitly stated. 不要对没有明确陈述的事情做假设。
例如对于一个短地址服务:
关于Constraints约束:
- could be meant to serve just a few thousand users, but each could be sharing millions of URLs. 只服务少量用户,但是每个用户分享大量URL
- could be meant to handle millions of clicks on the shortened URLs, or dozens. The service may have to provide extensive statistics about each shortened URL (which will increase your data size), 大量的点击
-
or statistics may not be a requirement at all.
 Constraints约束
Constraints约束
关于Use Cases用例:
- You will also have to think about the use cases that are expected to occur. Your system will be designed based on what it's expected to do. 系统基于User Cases用例来设计。
 Use Cases用例
Use Cases用例
总结:
Scope the problem: 确定问题的范围
- Don't make assumptions; 不要做假设
- Ask questions; 多问问题
- Understand the constraints and use cases. 明确系统的约束,识别用例
Step 2: Abstract design 抽象设计
You can tell the interviewer that you would like to do that and draw a simple diagram of your ideas. 告诉面试官你的想法,并画出一个简单的图。
Sketch your main components and the connections between them. 描述主要的components组件,及他们之间的关系。
Don’t get lured to dive deep into some particular aspect of the abstract design. 不要在抽象设计的某个具体方面陷入太深。
Usually, this sort of high-level design is a combination of well-known techniques, which people have developed. You have to make sure you are familiar with what's out there and feel comfortable using this knowledge. 使用现有的技术,当然你需要清楚并能够熟练使用这些技术。

Step 3: Understanding bottlenecks 清楚瓶颈
Now that you have your high-level design, start thinking about what bottlenecks it has.
- Perhaps your system needs a load balancer and many machines behind it to handle the user requests. 或许你的系统需要做负载均衡
- Or maybe the data is so huge that you need to distribute your database on multiple machines. 或许数据量很大,你需要使用分布式的数据库
- What are some of the downsides that occur from doing that? Is the database too slow and does it need some in-memory caching? 或许数据库太慢,需要使用缓存
Remember, usually each solution is a trade-off of some kind. Changing something will worsen something else. However, the important thing is to be able to talk about these trade-offs, and to measure their impact on the system given the constraints and use cases defined. 每一个方案都有优劣。重要的是,你要能够识别这些优势和劣势,并且能够基于系统的约束和用例来度量他们的影响。

Step 4: Scaling your abstract design 扩展抽象设计



Scalability 扩展性
Fundamentals 基础知识
Following concepts:
- Vertical scaling 垂直扩展
- Horizontal scaling 水平扩展
- Caching 缓存
- Load balancing 负载均衡
- Database replication 数据库备份
- Database partitioning 数据库切分
- Using NoSQL instead of scaling a relational database 使用NoSQL
- Being asynchronous 异步策略
Examples 示例
一些已有的网站和系统是如何扩展的:
- Deep Learning in production: Great story about how EyeEm built their production system running multiple deep learning models on huge amounts of images
- Uber: A nice article about how Uber had to scale fast, about breaking your service into many micro services spread across many repos
- Facebook: How Facebook handles 800,000 simultaneous viewers on a live stream
- Kraken.io: How to scale image optimisation at a large scale, this article will look in more detail at some specific hardware solutions used, as well as deployment, monitoring and other important aspects
- Twitter: How Twitter handles 3,000 image uploads per second and why the old ways it used would not work nowadays
- PlentyOfFish: A great example of what a single engineer can achieve in terms of scalability
- Salesforce: A relatively short example from Salesforce.
- ESPN: Another awesome and thorough example, this time from the digital media industry.
- Finally, some good example of Twitter subcomponents: Storing data (video | text), and Timeline (video | text).
- For more advanced examples, check out these posts on Google, Youtube (video | text), Tumblr, StackOverflow, and Datashift.
How to Practice? 如何实践
- Solve with Friends
- Mock Interviews
实践 The Twitter Problem
Intro & Statement 问题描述
Design a simplified version of Twitter where people can post tweets, follow other people and favorite* tweets.
Clarifying Questions 明确问题
- First of all, how many users do we expect this system to handle? 系统有多少个用户?每天有多少个请求?
- Since we have the notion of following someone, how connected will these users be? 每个用户会follow多少个人?
- Producing new tweets and favoriting them should be the most common write operations in the application. But how many requests will that generate? 每天会有多少个帖子?每个帖子会有几个favorite?
There are many other questions that one could ask and we will get to some more in the next sections just to illustrate that sometimes questions pop up when you start thinking about the solution. 还可以提出很多其他问题。
This session where you ask questions and get answers should probably not last more than just a few minutes assuming your interview lasts 40-45 minutes and especially if this is not the only problem you get in it. 但是提问时间不要太长。
通过提问,我们可以得到一些结论:
- 10 million users
- 10 million tweets per day
- 20 million tweet favorites per day
- 100 million HTTP requests to the site
- 2 billion “follow” relations
- Some users and tweets could generate an extraordinary amount of traffic
High-level Design 高层次设计
We can divide our architecture in two logical parts:
-
- the logic, which will handle all incoming requests to the application 逻辑层,用来处理外部来的请求。
-
- the data storage that we will use to store all the data that needs to be persisted. 数据存储层,用来持久化数据。
我们系统要能够处理如下的请求:
- posting new tweets
- following a user
- favoriting a tweet
- displaying data about users and tweets
Let’s make it more concrete how the user will interact with our application and design something that will support such interactions. We can describe to the interviewer how we imagine this to work. 我们可以同面试官描述用户如何同我们的系统进行交互。例如,默认打开首页,显示了最新的帖子,点击每一个帖子,可以看到。。。等等
Handling user requests 处理用户请求:使用负载均衡策略,例如Nginx。
Storing the data 数据存储:使用缓存策略,例如memcached。
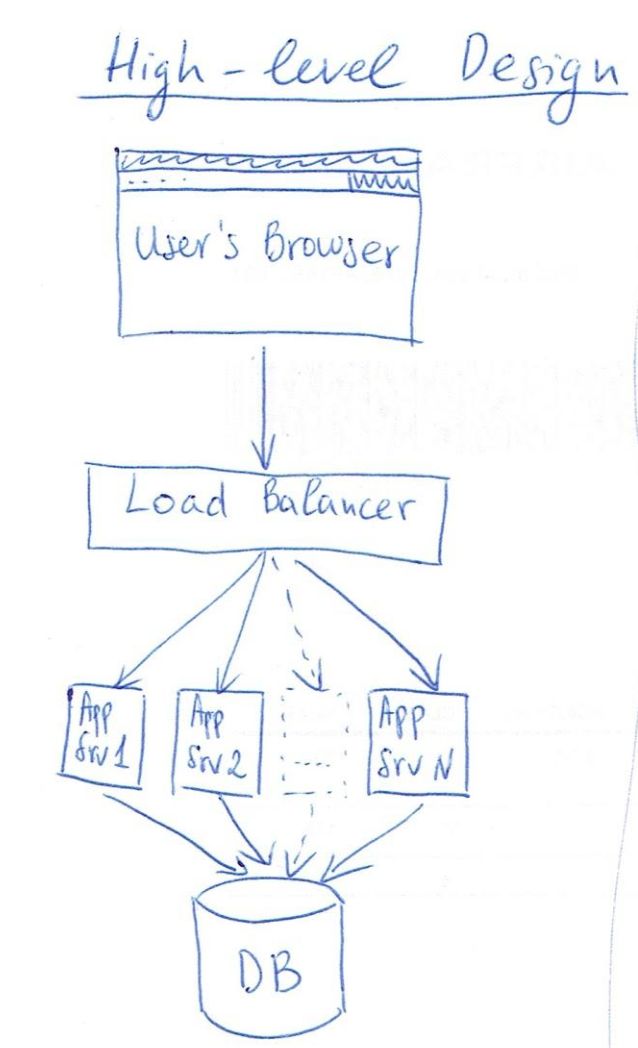
Low-level Issues 低层次的一些问题
Database schema 数据表结构:
用户表 users
ID (id)
username (username)
full name (first_name & last_name)
password related fields like hash and salt (password_hash & password_salt)
date of creation and last update (created_at & updated_at)
description (description)
and maybe some other fields.
帖子表 tweets
ID (id)
content (content)
date of creation (created_at)
user ID of author (user_id)
用户关联表 connections
ID of user that follows (follower_id)
ID of user that is followed (followee_id)
date of creation (created_at)
favorites表 favorites
ID of user that favorited (user_id)
ID of favorited tweet (tweet_id)
date of creation (created_at)
随后可以再考虑如下问题:
- 对以上的数据表会有哪些常用的查询query
- 基于常用的query,如何设计索引 Index
Building a RESTful API 创建 RESTful 接口:
例如:
GET /api/users/GET /api/users//tweets GET /api/users//tweets?page=4 GET /api/users//followers GET /api/users//followees POST /api/users//tweets POST /api/users//followers GET /api/users//tweets/ /favorites POST /api/users//tweets/ /favorites
Additional Considerations 额外的考虑
Increased number of read requests 不断增加的read请求:
随着请求数目的不断增加,现有设计的哪些地方会出现瓶颈?
- One very natural answer is our database. 首先一个性能瓶颈是数据库。
One typical way to handle more read requests would be to use replication. 使用数据库的复制,即访问不同机器上的不同的副本,当然每一份副本的内容是一样的。
Of course, this will help if the write requests are not increased dramatically. 如果写请求没有快速增长,使用多个副本来满足快速增长的读请求是可行的。
An alternative approach could be to shard our database and spread the data across different machines. 另一种方案是,数据分块,不同块放在不同的机器上。This will help us if we need to write more data than before and the database cannot handle it. 这可以解决写请求也快速增长的情况。 - If we manage to stabilize our database, another point where we could expect problems is the web application itself. 下一个瓶颈是应用本身。
If we’ve been running it on a limited set of machines, which cannot handle all the load anymore this could lead to slow response times. One good thing about our high-level design is that it allows us to just add more machines running the application. 增加更多的机器。 - One approach mentioned above is to add an in-memory cache solution in front of the database with the goal to not send repeated read requests to the database itself. We could use a key-value store like memcached to handle that. 在数据库之前增加一个缓存,例如memcached或者redis。
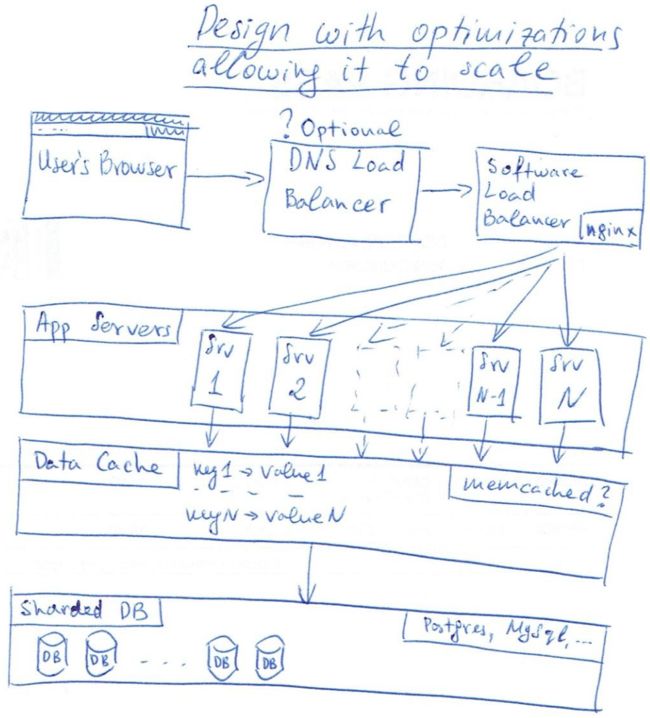
实践 The Summarization Problem
Intro & Statement 问题描述
"In our company we already have developed a great library that can be used to summarize text articles. Just feed it the whole text and it will return a decent summary that is just a few sentences long.
We need to put this in production and make it scalable. We expect that our customers will submit text articles from our mobile app and also from our website.
The library currently takes between 0.1 and 5 seconds to summarize an article. You need to design a system that uses our existing library and allows users to submit text articles through the mobile app and through the website.
We anticipate that this service will be used around 1 million times a month. Our desire is to not respond in more than 10 seconds to each request."
Clarifying Questions 明确问题
- What is the expected maximum number of simultaneous requests? 能够接受的最大并发量是多少?
- Do you want to store the results of the processing for a longer period of time? 是否需要存储结果?
- What is the expected way of presenting the results within the website and the mobile app? 在网站和手机App上如何显示结果?
通过提问,我们可以得到一些结论:
- The expected monthly requests are around 1 million
- There should be at most 50 requests per second but the architecture should easily be expandable to handle more than that, if needed
- Responses should not take more than 10 second, with the summarization library possibly taking 5 seconds to do its job
- The summaries will be presented to the users asynchronously, meaning that we will not wait for the summary to be in the HTTP response that comes after the initial HTTP request
High-level Design 高层次设计
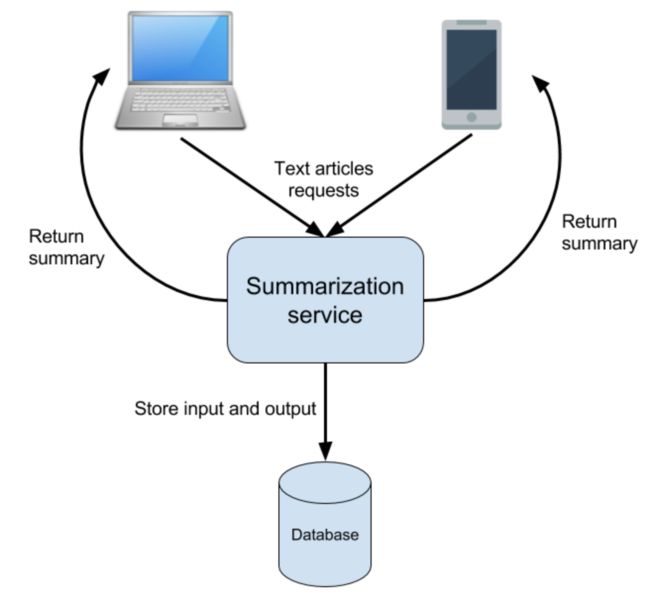
Low-level Issues 低层次的一些问题
This suggestion was probably the simplest possible implementation - to expose a RESTful API from the service, which accepts text articles for summarization. 最初的设计是将Summarization Service暴露一个 RESTful API。这会带来一个扩展性的问题。
If at a given point in time the incoming requests increase, the summarization service may be unable to handle all incoming requests and some of them could time out. This will result in poor experience for the customer. 如果同时有大量的请求,Summarization Service无法快速处理完。
We could make sure that we have a number of instances that are running the summarization service and put a load balancer in front of them. This will allow us to handle more requests and scale horizontally by adding more instances of the summarization service. The load balancer will route the requests to the instances that are less loaded. 我们可以使用多个Instance来提供Summarization Service,并使用一个 load balancer 来进行调度。
However, there is another problem with this solution. If for some reason an instance of the summarization service is not able to handle requests and a request is routed to it, this request will most likely be lost. Such a thing could happen if all allocated instances are busy with other work. Also, if a given instance is not responding for some reason, due to a bug in the code, or some other issue, we could again lose a request that was routed to it by the load balancer. 这样也会带来一个问题,如果某一个Summarization Service的实例挂了,该请求将会丢失。
An alternative approach that resolves the issues above is to use a message queue to store the summarization requests. In short, a message queue will allow us to enqueue on it all summarization requests. Let’s call all such requests stored on the queue jobs. Then, if we have a set of workers running the summarization service, each worker could pull jobs from the queue, one at a time. Each job can be processed by the worker that picked it up and the results can be stored in the database. 使用消息队列。将请求放入队列中,称之为一个job,每一个work从队列中以此获取一个job,处理,并将结果存放到数据库中。
Imagine that suddenly the traffic increases. The queue will start to fill up with jobs because the allocated workers cannot handle the increased number of requests. We could have a monitoring service that would detect this situation and would spin up additional workers, which will also start pulling from the queue and will alleviate the load on the existing workers. 假设请求数目突然增多,导致消息队列快满了。我们可以建立一个监督进程来检测该情形,此时可以增加更多的work,即更多的Summarization Service实例。
Also, with this solution, we know that only properly operating workers will be pulling jobs from the queue. Hence, jobs will not be lost due to not responding workers. 由于只有活跃的worker才会从队列中获取job,因此job不会分配给有问题的worker。
It is still possible that a worker takes a job but crashes while processing it. For example, if we have a bug in the summarization code and it crashes in the middle of the operation. This means that a job was pulled from the queue but a result was never computed. Does this mean that the job was lost? Not necessarily. 当然,一个worker可能会在处理job的过程当中出现了问题,导致挂了,这种情况下,我们也可以通过一些策略来避免该job被丢失。
We will need to make sure that our message queue requires an acknowledgement that the job was successfully processed. This means that each worker will have to let the queue know that the job that it pulled was processed. If the worker crashes it won’t notify the queue. After a given timeout passes the queue will assume that the job was not processed successfully and will make it available for pulling. This can be done a number of times until the job is discarded to some other place. 我们要求,每一个worker在成功处理完一个job后,需要通知 acknowledgement 消息队列,此时队列移除该job。如果一个worker在处理job的过程当中出现了问题,导致挂了,这种情况下,消息队列在 time out 时间内没有收到该worker的 acknowledgement,则重新将该job设置为可取的状态。
The important point is that using a message queue we achieve two useful things: 使用消息队列的两点优势:
- We are ready to scale up easily by spinning up more summarization workers 通过增加更多的summarization workers 可以很简单的实现系统性能的扩展。
- We can handle unexpected problems with jobs processing without losing jobs 能够处理异常情况,防止job被丢失。
关于数据的存储:
Each summarization service instance could write its result to the database once it’s ready with the work. This would mean that we have multiple instances writing to this database because we plan to have multiple summarization workers handling requests. This should be fine as long as we don’t have too many such workers, which occupy all available connections to the database. With the expected load we should not be in such a situation any time soon. 每一个 summarization service instance 将结果写入到数据库。
An alternative would be to let the workers write their results to another message queue, which is then processed by one or more workers. The job of these additional workers would be to pull summarization results from the queue and store them in the database. This is a possible solution but in our case it’s not really necessary to implement. 另外一个方案,summarization service instance 将结果写入另一个消息队列,有一些专门的worker负责将该队列中的结果存储到数据库中。
Once the results are in the database our front-end clients could use some mechanism that allows them to display these results to the customer who requested them. 结果存储到数据库后,前端可以访问并展示这些结果。
