唯品会 1000+ 台 Hadoop 集群优化经验
性能挑战
01
HDFS 是一个分布式系统,只要有足够的资源,可以扩容上千个节点支持100PB以上的集群。我们发现Hadoop集群升级(2.5.0-cdh5.3.2-->2.6.0-cdh5.13.1)以后,NameNode RPC(remote procedure call)queue time在持续的在间隔一周左右性能恶化,在极端环境下出现一个RPC查询需要等待好几分钟的情况,Hive作业出现大量的同一类型错误失败:
Error in org.apache.Hadoop.Hive.ql.exec.mr.MapRedTask. Unable to close file because the last block does not have enough number of replicas.
重启集群以后问题可以得到缓解,但是这个问题需要从根本上考虑如何解决。
性能优化
02
RPC变慢的根源在于HDFS的NameNode吞吐量和性能瓶颈。NameNode存在最大吞吐量限制,每一次写的请求都会产生排他性“写锁”,强制其他任何操作必须在队列里等待它完成。NameNode的RPC queue time指标可以显示表达这个系统当前状态。对此我们主要从代码和业务两方面进行优化。
Datanode延迟块汇报
03
1.Datanode的块汇报
当datanode上新写完一个块,默认会立即汇报给namenode。在一个大规模Hadoop集群上,每时每刻都在写数据,datanode上随时都会有写完数据块然后汇报给namenode的情况。因此namenode会频繁处理datanode这种快汇报请求,会频繁地持有锁,其实非常影响其他rpc的处理和响应时间。
2.优化方案
通过延迟快汇报配置可以减少datanode写完块后的块汇报次数,提高namenode处理rpc的响应时间和处理速度。
配置:
dfs.blockreport.incremental.intervalMsec
300
目前我们HDFS集群上此参数配置为300毫秒,就是当datanode新写一个块,不是立即汇报给namenode,而是要等待300毫秒,在此时间段内新写的块一次性汇报给namenode。
删除块个数可配置
04
由于HDFS的单一锁设计,NN对于大目录删除行为并没有表现出很好的执行效果,严重时甚至会出现长时间block其它应用的正常请求处理。Hadoop新版本引入新结构FoldedTreeSet来存储DN的块数据,但是它并不利于update操作,因此删除问题在升级后的版本中体现更为明显了。我们也在社区上提了相关issue:https://issues.apache.org/jira/browse/HDFS-13671。
后续我们在研究HDFS删除块的行为中,发现NN在每次batch删除块的时候,是以固定size按照batch方式定期删除收集到的块信息。在每次batch间隙,其它请求就有机会得到NN锁的机会。于是我们考虑到一个改进手段,即是否能让batch size变得更加灵活可配置化,以此来控制给其它请求得到NN锁处理的概率。
基于这个思路,我们新建了以下配置项,并改动了相关代码逻辑。
dfs.namenode.block.deletion.increment
1000
The number of block deletion increment.
This setting will control the block increment deletion rate to
ensure that other waiters on the lock can get in.
此优化也已经被我们贡献到Hadoop社区,相关JIRA链接:https://issues.apache.org/jira/browse/HDFS-13831(点击阅读原文即可进入页面)
HDFS Federation
05
1.独立集群模式弊端
在日常HDFS集群维护过程中,我们发现HDFS集群独立运行模式存在着许多弊端:
●独立集群模式运维成本高,上下线机器每次都要制定分配所属集群。
●多独立集群模式无非良好均衡资源和请求,经常发现A集群平时负载要远远高于B集群,这本质上是资源共享利用的问题。
●单集群模式性能瓶颈问题。
综上,我们对现有大集群独立运行模式进行了Federation改造。Federation改造的关键前提是不同namespace的Cluster ID必须保持一致,否则DN在上报过程中会抛出异常而注册失败。鉴于我们内部集群在初始搭建时指定了统一的Cluster ID,所以并没有在前期再对Cluster ID做额外人工转换工作。
2.Federation问题解决
在Federation过程中,我们主要遇到了3个问题:
不同集群拓扑结构不一致导致DN注册上报错误,错误如下:
2019-01-29 14:12:10,821 ERROR [Thread-30] org.apache.Hadoop.HDFS.server.datanode.DataNode: Initialization failed for Block pool BP-1508644862-xx.xx.xx.xx-1493781183457 (Datanode Uuid b8a47300-9fd9-4226-93a1-6649341b3b2c) service to xx.xx.xx.xx:8022 Failed to add /default-rack/xx.xx.xx.xx:50010: You cannot have a rack and a non-rack node at the same level of the network topology.
at org.apache.Hadoop.net.NetworkTopology.add(NetworkTopology.java:414)
at org.apache.Hadoop.HDFS.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:987)
at org.apache.Hadoop.HDFS.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:5264)
at org.apache.Hadoop.HDFS.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:1291)
at org.apache.Hadoop.HDFS.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:100)
at org.apache.Hadoop.HDFS.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:29184)
上述错误产生的根本原因是DN在Federation注册时在不同的namespace拥有不同level层级。后面经过原因排查,是由于我们没有完全同步好2个集群rack-awareness的脚本映射关系,由配置项net.topology.script.file.name所配置。
后续在DN Federation上报过程中,我们又遇到了因为本地du命令不准确导致DN capacity容量double的异常,继而导致DN无非正常进行写数据块行为。因为DN在上报自身capacity容量时,需要依赖于本地系统du命令来计算实际使用空间大小。后面我们对系统du命令进行了校准修复,最后DN能正常Federation上报注册。
如今,我们已经完全打通2个独立大集群,同时加入第三套NN,来做新的namespace存储,在未来会对数据进行业务划分,将数据均衡打散在不同namespace下,充分利用每个namespace下NN的处理能力。
另外一个问题是在Federation完成后发现的。因为Federation过程是将已有独立大集群模式改造成Federation模式,而不是直接搭建新Federation集群模式,我们发现NN元数据膨胀地比较厉害,即使block的元数据没有发生多大变化,但是实质上DN和block的映射是会得到膨胀的,因此后期马上对NN的JVM参数进行了相关调整。
我们原有主集群的运行模式如下,两个独立大集群运作模式:
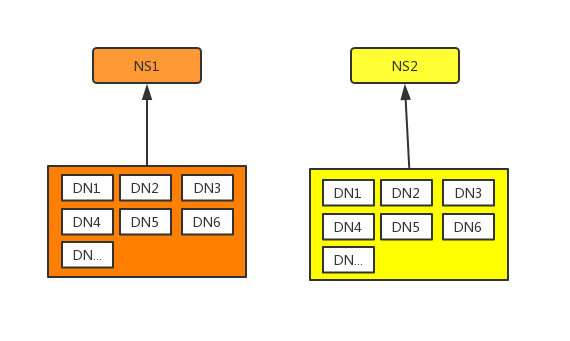
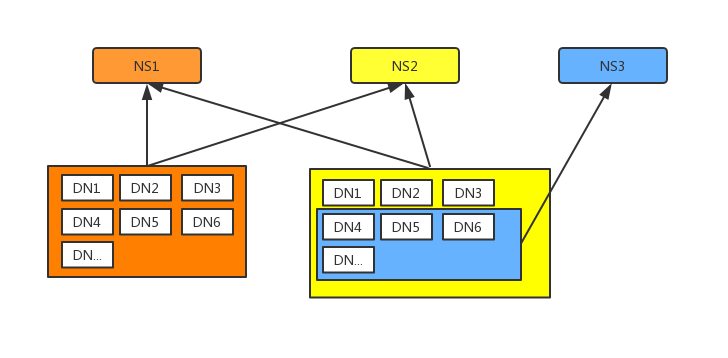
经Federation改造完成的结构如下, 最终效果是所有datanode向全部三套NN汇报:
客户端监控以及temp目录分流,Hive本身降低HDFS请求
06
1.HDFS客户端监控
客户端监控主要是从HDFS的客户端角度出发,监控HDFS的rename、create等部分rpc操作或者write这种涉及datanode操作的操作时长。这是补充HDFS服务端rpc监控的手段之一。
出发点是,有时服务端这边的监控比较正常,但是从任务(Hive,spark或者presto)角度来看,发现一些move或者load等操作依旧花费很长时间。这意味着服务端监控仅能够体现服务端处理性能,并不能很好地衡量整个集群向外提供服务的性能。

上图是rename的平均时长,考量的是一个文件被rename后的平均时长。

上图write的平均时长,考量一个只有少量数据的文件被创建时的平均时长,通过这个指标可以评估当前namenode的8022端口以及datanode性能。
2.temp目录分流
从上面分析bip以及bip03的文件操作以及rpc情况来看,可以得出如下两个结论:
●占用rpc大头的是 /mr/staging, /tmp/Hive/HDFS/, /bip/developer/vipdm, 其次还有/tmp/Hive/.Hive-staging, /mr/intermediate_done, /bip
●切换 defaultFs, 明显影响到 /mr/staging, /tmp/Hive/HDFS/ ,/mr/intermediate_done, 也非常明显影响了rpc。
●如此,对temp目录进行分流将会很大程度影响集群的rpc情况。
解决方案如下:
●在Hive引擎层面(或者在调度层面也ok),平衡切换defaultFs,确保临时目录均衡地分布在bip或者bip03上面。
●采用第三个集群,将 /mr/staging, /tmp/Hive/HDFS/, /mr/intermediate_done 迁移到上面,简而言之,就是把defaultFs设置成第三个集群(最好可以通过Federation进行分流,这样不会太大影响数据的本地性)。
●使用双报,通过自动化的方式平衡bip以及bip03的压力。
3.Hive本身降低rpc请求
Hive有很多地方都调用了HDFS的rpc接口,并发出大量rpc请求。如果能够从Hive的rpc客户方降低rpc请求,也能够很大程度缓解HDFS的压力。
●Hive的insert、create等操作产生的临时数据,需要统一放到非表下,这样能够大量减少在最后rename的操作。
●因为暂时用不上HDFS的Encryption,所以多次的Encryption检测显然非常浪费性能,可以设置参数选择性关闭。
小文件治理
07
小文件问题在大规模HDFS集群中是经常会遇到的问题。小文件过多引发的各种性能瓶颈在一定程度上影响了集群稳定性。我们采取了以下措施进行优化改善。
1.改进措施
●HDFS Federation。相当于横向扩展namenode的处理能力,增加namenode数量来共同分担元数据管理的压力。但这并不十全十美,只是暂时隐藏了小文件多的问题。
●合并小文件。这个方案说起来简单,却也并不容易。针对Hive相关任务,针对由历史任务产生大量小文件的作业,首先使用CombineHiveInputFormat,将多个小文件作为一个整体split,从而减少map数量,然后配置mapred.min.split.size.per.node和mapred.max.split.size增加map处理的文件大小。这个方案我们已经做成可配置化,用定时任务合并用户历史作业产生的数据。其次orcfile格式的Hive表,推荐使用CONCATENATE语义,orcfile的合并是stripe级别,节省了解压和格式化数据的开销,增加效率。
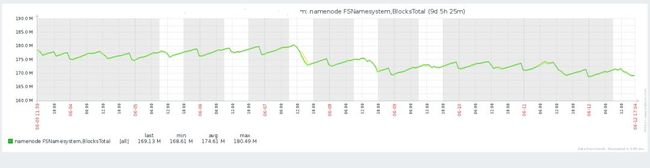
经过一段时间的努力小文件数量得到有效改善,如下图所示:
2. 未来终极解决方案:Hadoop Ozone?
Hadoop Ozone是基于 HDFS 实现的对象存储服务,支持更大规模数据对象存储,支持各种对象大小并且拥有 HDFS 的可靠性、一致性和可用性。Ozone的一大目标就是扩展 HDFS,使其支持数十亿个对象的存储。目前这个项目已经成为 Apache Hadoop 的子项目,我们也会持续关注。
猜你喜欢
1、过往记忆大数据,2019年原创精选69篇
2、Hadoop 2.7 不停服升级到 3.2 在滴滴的实践
3、深入学习 Redis 集群搭建方案及实现原理
4、Kafka 集群在马蜂窝大数据平台的优化与应用扩展

过往记忆大数据微信群,请添加微信:fangzhen0219,备注【进群】