FCN模型训练中遇到的困难
前前后后大概忙了3个月了 中间穿插了导师给的项目和论文的任务 总算把fcn给run起来了
之前也有参考一些博客作为指导 不过博客有的是有误导性的 导致我的loss居高不下 根本不收敛
还有一些奇奇怪怪的问题 我在下面逐一列举
个人有一篇从零开始运行FCN的博客 如果需要的话可以去看下:http://blog.csdn.net/wangkun1340378/article/details/70238290
问题1.使用infer.py时候遇到no display name and no $DISPLAY environment variable
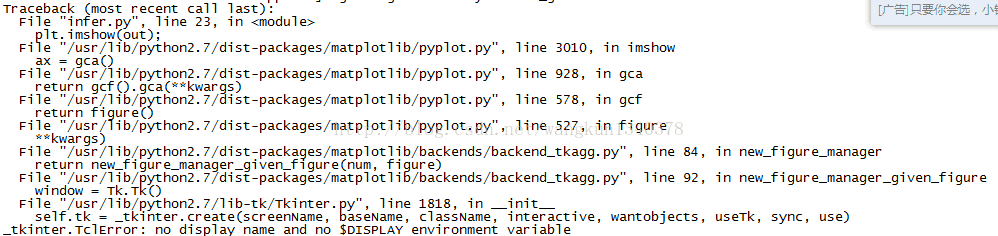
出现这个问题 是由于在远程服务器上运行 并且 服务器上没有显卡 直接导致plt无法运行 所以报错
2个解决方法:
方法一:
在infer.py中加入
import cv2
print type(out)
print out, out.shape
cv2.imwrite("output.png", out)
用cv2来保存图片,并且注释掉plt
不过这样虽然能保存图片 但是图片效果不行 具体表现为颜色不对 结果可以看下图

正确的结果如下所示 大家可以对比一下

如果觉得方法一不行 就采用方法2
方法2:采用python notebook
用本机访问自己在远程服务器上的账号 在本机上执行代码
问题2:lisi out of range
这个是由于solve.py中
caffe.set_device(int(sys.argv[1]))
caffe.set_mode_gpu()
可以把这两行代码注释掉 或者 利用nvidia-smi看看存在那个gpu就选那个gpu
问题3:no module named caffe
方法 在py文件import caffe前加上
import sys
sys.path.append('/home/my/caffe-master/caffe-master/python')
具体路径根据自己实际情况而定
问题4:no module named XXX
解决方法 把fcn.berkeleyvision.org-master目录下所有的py文件统统复制到你的solve.py所在的文件夹
例如 surgery 等等等等
问题5,:利用得到的model怎么测试图片
方法:运行fcn.berkeleyvision.org-master目录下的infer.py文件,注意修改model路径和deploy文件路径,还有测试图片路径
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import sys
sys.path.append('/home/my/caffe-master/caffe-master/python')
import caffe
import cv2
# load image, switch to BGR, subtract mean, and make dims C x H x W for Caffe
im = Image.open('test_3.jpg')
in_ = np.array(im, dtype=np.float32)
in_ = in_[:,:,::-1]
#in_ -= np.array((104.00698793,116.66876762,122.67891434))
#in_ -= np.array((111.67446899,109.91841125,105.24302673))
in_ -= np.array((105.24302673,109.91841125,111.67446899))
in_ = in_.transpose((2,0,1))
# load net
#net = caffe.Net('deploy.prototxt', 'siftflow-fcn32s-heavy.caffemodel', caffe.TEST)
net = caffe.Net('deploy.prototxt', 'siftflow-fcn32s/train_iter_100000.caffemodel', caffe.TEST)
#net = caffe.Net('deploy.prototxt', 'train_iter_96000.caffemodel', caffe.TEST)
# shape for input (data blob is N x C x H x W), set data
net.blobs['data'].reshape(1, *in_.shape)
net.blobs['data'].data[...] = in_
# run net and take argmax for prediction
net.forward()
out = net.blobs['score_sem'].data[0].argmax(axis=0)
#out = net.blobs['score_geo'].data[0].argmax(axis=0)
#print type(out)
#print out, out.shape
#cv2.imwrite("output.png", out)
plt.imshow(out,cmap='gray');
plt.imshow(out);
plt.axis('off')
plt.savefig('test_3_out.png')
plt.show()
如上面代码所示
net = caffe.Net('deploy.prototxt', 'siftflow-fcn32s/train_iter_100000.caffemodel', caffe.TEST)siftflow-fcn32s/train_iter_100000.caffemodel为模型所在路径,deploy文件如果没有 可以参照一下方法
首先,根据你利用的模型,例如模型是siftflow32s的,那么你就去siftflow32s的文件夹,
里面有train.prototxt文件,将文件打开,全选,复制,新建一个名为deploy.prototxt文件,粘贴进去,
然后ctrl+F 寻找所有名为loss的layer 只要有loss 无论是loss还是geo_loss 将这个layer统统删除
然后在文件顶部加上
layer {
name: "input"
type: "Input"
top: "data"
input_param {
# These dimensions are purely for sake of example;
# see infer.py for how to reshape the net to the given input size.
shape { dim: 1 dim: 3 dim: 256 dim: 256 }
}
}
其中shape{dim:1 dim:3 dim:256 dim:256}这两个256,是由于我的测试图片是256X256 如果你的是500X500 那你就将最后两个dim改为500 500
需要注意的是 如果你执行的是siftflow32s,你没有deploy,你需要加入inputdata layer,你如果执行sififlow16s的model 那么是不需要加inputdata layer的
因为他们的train.prototxt文件里已经有了inputdata layer
问题6:
利用得到的模型 测试单张图片 结果全黑
这个问题可能有多个原因
原因1:在于loss太高 模型未收敛 或者 deploy文件的参数设置有误。
原因2:如果针对sififlow数据集 那么请保证deploy文件的准确性
原因3:infer.py的有误 没有将
问题7:
在训练过程中,loss高居不下,模型不收敛
原因:
这个问题的原因有很多,我只能说出个人的经历,我开始训练时候,模型也是不收敛,在这里我详细说明一下这个问题的处理方式
首先,我在根据siftflow数据集训练fcn32s的模型时候遇到了这种情况,模型的loss高居不下,训练10w次,loss依然高于2w
这是由于我参照的博客的说明有误
在这里郑重声明一下:如果训练fcn32s的网络模型,
一定不要将fc6,fc7重新命名,
并且一定要修改solve.py
利用transplant的方式获取vgg16的网络权重;
具体操作为
import sys
sys.path.append('/home/my/caffe-master/caffe-master/python')
import caffe
import surgery, score
import numpy as np
import os
import sys
try:
import setproctitle
setproctitle.setproctitle(os.path.basename(os.getcwd()))
except:
pass
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
# init
caffe.set_mode_gpu()
# caffe.set_device(int(sys.argv[0]))
caffe.set_device(7)
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)
solver = caffe.SGDSolver('solver.prototxt')
vgg_net=caffe.Net(vgg_proto,vgg_weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
# surgeries
interp_layers = [k for k in solver.net.params.keys() if 'up' in k]
surgery.interp(solver.net, interp_layers)
# scoring
test = np.loadtxt('../data/sift-flow/test.txt', dtype=str)
for _ in range(50):
solver.step(2000)
# N.B. metrics on the semantic labels are off b.c. of missing classes;
# score manually from the histogram instead for proper evaluation
score.seg_tests(solver, False, test, layer='score_sem', gt='sem')
score.seg_tests(solver, False, test, layer='score_geo', gt='geo')
#solver = caffe.SGDSolver('solver.prototxt')
#solver.net.copy_from(weights)添加了solver = caffe.SGDSolver('solver.prototxt')
vgg_net=caffe.Net(vgg_proto,vgg_weights,caffe.TRAIN)
surgery.transplant(solver.net,vgg_net)
del vgg_net
并且在import后添加了
vgg_weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'
vgg_proto = '../ilsvrc-nets/VGG_ILSVRC_16_layers_deploy.prototxt'
weights = '../ilsvrc-nets/vgg16-fcn.caffemodel'VGG_ILSVRC_16_layers_deploy.prototxthttp://pan.baidu.com/s/1geLL6Sz
如果训练fcn16s,则可以直接copy自己的fcn32s的model的权重,不需要transplant,也就是不需要修改solve.py
如果训练fcn8s,则可以直接copy自己的fcn16s的model的权重,不需要transplant,也就是不需要修改solve.py
总的来说,算是在自己的fcn道路上成功踏出了第一步,上面的问题有的是请教自己的学长,有的是百度或者google,有的是和网友交流得来的心得
下面附上几个之前参考的博客
http://www.cnblogs.com/xuanxufeng/p/6240659.html
http://www.cnblogs.com/xuanxufeng/p/6243342.html
顺便感谢 踏雪霏鸿,一生不可自决,与人不争,大喷菇 等人的帮助 以上!