监督学习——支持向量机SVM
支持向量机属于监督学习,是一种二类分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,支持向量机包括核心技巧,这使它成为实质上的非线性分类器。支持向量机的学习策略是间隔最大化,可形式化为一个求解凸二次规划的问题。
支持向量机学习方法包含构建由简至繁的模型:
线性可分支持向量机、线性支持向量机及非线性支持向量机。
当训练数据线性可分时,通过硬间隔最大化,学习一个线性的分类器,即线性可分支持向量机,又称为硬间隔支持向量机;
当训练数据线性近似可分时,通过软间隔最大化,可学习一个线性的分类器,即线性支持向量机,又称为软间隔支持向量机;
当训练数据线性不可分时,通过使用核及软间隔最大化,学习非线性支持向量机。
1.1.1.1. 预备知识
1.1.1.1.1. 超平面
其实就是过原点的平面,3维空间中平面方程可表示为ax+by+cz+d=0;那么高维空间平面可表示为: ![]() ; w 和 x 都是 n 维列向量,x 为平面上的点,w 为平面上的法向量,决定了超平面的方向,b 是一个实数,代表超平面到原点的距离。且
; w 和 x 都是 n 维列向量,x 为平面上的点,w 为平面上的法向量,决定了超平面的方向,b 是一个实数,代表超平面到原点的距离。且
![]()
![]()
1.1.1.1.2. 函数间隔与几何间隔
函数间隔先不管,如果有兴趣自己查资料;几何间隔: ![]()
分子就是函数间隔。
1.1.1.1.3. KKT条件
KKT条件(最优化条件),满足一些有规则的条件了一个非线性规划问题能有最优化解法的一个充要条件。
约束条件是等式的优化问题,可以用拉格朗日乘子法去求取最优值;
约束条件是不等式的优化问题,可以用KKT条件去求取;
如以下非线性最优化问题:

其中,f(x)是需要最小化的函数,![]() 是不等式约束条件,
是不等式约束条件,![]() 是等式约束条件,定义函数:
是等式约束条件,定义函数:
![]()
其中,![]() 是拉格朗日乘子,所谓的KKT最优化条件,即是使得f(x)最小值的
是拉格朗日乘子,所谓的KKT最优化条件,即是使得f(x)最小值的![]() 满足KKT条件:
满足KKT条件:

不等式约束条件有方向性,所以![]() ,而等式约束条件无方向性,所以
,而等式约束条件无方向性,所以![]() 。
。
1.1.1.2. 为什么要引入KKT条件和对偶问题
1.1.1.2.1. 原始问题
考虑约束最优化问题:
![]()
![]()
称为约束最优化问题的原始问题。
现在如果不考虑约束条件,原始问题就是:
![]()
引进广义拉格朗日函数(generalized Lagrange function):
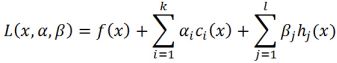
现在,如果把![]() 看作是关于
看作是关于![]() 的函数,要求其最大值,即
的函数,要求其最大值,即
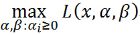
再次注意![]() 是一个关于
是一个关于![]() 的函数,经过我们优化(不要管什么方法),就是确定
的函数,经过我们优化(不要管什么方法),就是确定![]() 的值使得
的值使得![]() 取得最大值(此过程中把
取得最大值(此过程中把![]() 看做常量),确定了
看做常量),确定了![]() 的值,就可以得到
的值,就可以得到![]() 的最大值,因为
的最大值,因为![]() 已经确定,显然最大值
已经确定,显然最大值![]() 就是只和
就是只和![]() 有关的函数,定义这个函数为:
有关的函数,定义这个函数为:
![]()
原始问题就是:

1.1.1.2.2. 对偶问题
定义关于![]() 的函数:
的函数:
![]()
注意等式右边是关于![]() 的函数的最小化,
的函数的最小化,![]() 确定以后,最小值就只与
确定以后,最小值就只与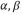 有关,所以是一个关于
有关,所以是一个关于![]() 的函数.
的函数.
考虑极大化![]() ,即
,即
![]()
这就是原始问题的对偶问题,再把原始问题写出来:
![]()
形式上可以看出很对称,只不过原始问题是先固定![]() 中的
中的![]() ,优化出参数
,优化出参数![]() ,再优化最优
,再优化最优![]() ,而对偶问题是先固定
,而对偶问题是先固定![]() ,优化出最优
,优化出最优![]() ,然后再确定参数
,然后再确定参数![]() .但是对偶问题求解要比原始问题简单的多。
.但是对偶问题求解要比原始问题简单的多。
1.1.1.2.3. 对偶问题是凸问题
对于拉格朗日的多个约束条件函数的逐点取最小值,而这样得到的函数一定是凹的。可以参照下图理解。

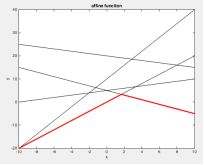
红色的线为逐点取最小值得到的函数图像。
这便是为什么要有对偶算法这个算法的一个原因,因为对偶问题都是凸问题,而凸优化问题在求解上会简单很多。一般而言,如果可以把一个问题表述成凸优化问题,那么就相当于基本解决了这个问题。
1.1.1.2.4. 原始问题与对偶问题关联:
原始问题的最小值大于等于对偶问题的最大值;
原问题最小值和对偶问题的最大值之差 叫 duality gap △=f∗−g∗
如果△=0 就是强对偶,否则就是弱对偶;
如果满足原问题是凸优化问题,并且至少存在绝对一个绝对可行点(什么叫绝对可行点,就是一个可以让所有不等式约束都不取等号的可行点),那么就具有强对偶性。这个条件就是传说中的Slater’s condition。
由此可知一个只有等式约束的凸优化问题和其对偶问题一定具有强对偶性,因为根本就没有不等式约束(推论)。
既然只有强对偶条件时才能保证对偶问题的最大值是原问题的最小值,也就是说只有等式约束时对偶问题的最大值是原始问题的最小值;所以当有不等式约束时就要满足KKT条件;而拉格朗日乘数法正是KKT条件在等式约束优化问题的简化版。
1.1.1.3. 线性可分支持向量机与硬间隔最大化
学习的目标是在特征空间中找到一个分离超平面,能将实例分到不同的类。分离超平面对应的方程为![]() ,它有向量w和截距b决定,可用(w,b)来表示超平面。
,它有向量w和截距b决定,可用(w,b)来表示超平面。
因此线性可分支持向量机可定义为,给定线性可分训练数据集,通过最大间隔化或等价的求解相应的凸二次规划问题,得到分离超平面:
![]()
以及相应的分类决策函数:
![]()
对于一个超平面(w,b),函数间隔:![]() ,几何间隔:
,几何间隔: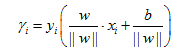 ,则几何间隔
,则几何间隔![]() 。
。
求一个几何间隔最大的超平面:
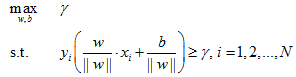
约束条件表示的是超平面的几何间隔至少是γ。

函数间隔![]() 的取值并不影响求解,若比例改变w和b为
的取值并不影响求解,若比例改变w和b为![]() 和
和![]() ,函数间隔也变为
,函数间隔也变为![]() ,对目标函数的优化求解无影响,所以取
,对目标函数的优化求解无影响,所以取![]() =1,得到:
=1,得到:

这是一个凸二次规划问题,其中,最大化![]() 和最小化
和最小化![]() 是等价的,为了方便计算做此转变。
是等价的,为了方便计算做此转变。
将它作为原始最优化问题,应用拉格朗日对偶性,求解对偶问题得到原始问题的最优解,这样的优点:
1. 对偶问题往往更容易求解;
2. 自然引入核函数,进而推广到非线性问题。
首先构建拉格朗日函数:

原始问题为:![]() ,不好解w,b;
,不好解w,b;
转化为对偶问题:![]() ;
;
1.求![]()
将拉格朗日函数![]() 分别对w和b求偏导并令其等于0:
分别对w和b求偏导并令其等于0:
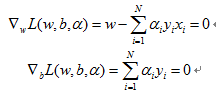
可得:
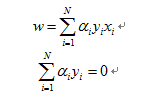
带入拉格朗日函数得:
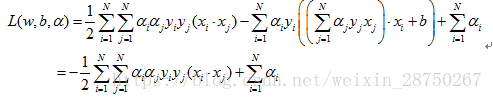
即 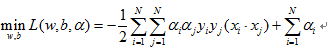
2.再对![]() 求α的极大:
求α的极大:

去掉负号那就对等于求下面的极小:
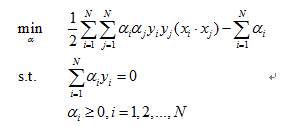
解得:
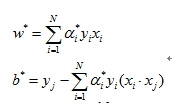
至此,分离超平面可表示为:
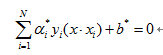
分类决策函数可表示为:
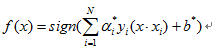
1.1.1.4. 线性可分支持向量机与软间隔最大化
如果训练数据集不是线性可分的,但是近似线性可分,有一些特异点,把这些特异点去掉后就可以线性可分,这时候就要用软间隔最大化。
这就意味着,有些特意样本点不满足函数间隔等于1的约束条件,为解决这个问题,可以对每个样本点引入一个松弛变量![]() >=0,使函数间隔加上松弛变量大于等于1,这样,约束条件变为:
>=0,使函数间隔加上松弛变量大于等于1,这样,约束条件变为:
![]()
同时,对每个松弛变量![]() ,支付一个代价,目标函数变为:
,支付一个代价,目标函数变为:
![]()
对偶问题变为:
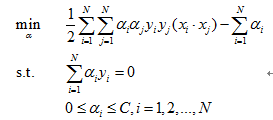
1.1.1.5. 非线性支持向量机与核函数
解决办法:利用一个非线性映射,把原数据集转化到一个更高维的空间,在这个高维空间找一个线性超平面来根据现行可分的情况处理。
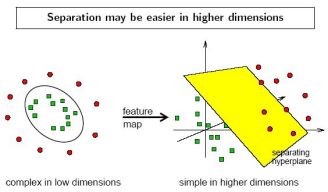
核函数:![]() ,其中
,其中![]() 就是把数据集从低维映射到高维空间的映射函数。用核函数代替原目标函数中
就是把数据集从低维映射到高维空间的映射函数。用核函数代替原目标函数中![]() 内积,因此,目标函数变为:
内积,因此,目标函数变为:
![]()
相应的分类决策函数变为:
![]()
常用的核函数:
多项式函数:
![]()
高斯核函数(高斯径向基核函数)RBF:
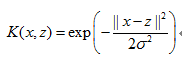
S型核函数(Sigmoid核函数):
![]()
如果我们对数据有一定的先验知识,比如图像分类,通常使用RBF,文字不使用RBF。
如果不知道,通常使用交叉验证的方法,来试用不同的核函数,误差最小的即为效果最好的核函数;也可以多个核函数结合起来,形成混合核函数。
还有一些不常用的核函数,幂指数核,拉普拉斯核,ANOVA核,二次有理核,多元二次核,逆多元二次核也属于径向基核函数;
幂指数核(Exponential Kernel)

拉普拉斯核(Laplacian Kernel)
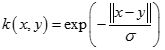
ANOVA核(ANOVA Kernel)
![]()
二次有理核(Rational Quadratic Kernel)
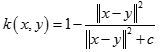
多元二次核(Multiquadric Kernel)
![]()
逆多元二次核(Inverse Multiquadric Kernel)
![]()
感知机
感知机是神经网络与支持向量机的基础,学会SVM感知机就会了。感知机是二分类的线性分类模型,输出为实例的类别,属于判别模型。感知机学习旨在求出将训练数据进行线性划分的分离超平面,导入基于误分类的损失函数,利用梯度下降法对损失函数进行极小化,求得感知机模型。
假设存在某个超平面S:![]() 能够将数据集的正实例点和负实例点完全正确的划分到超平面两侧。定义一个损失函数,令损失函数最小化。
能够将数据集的正实例点和负实例点完全正确的划分到超平面两侧。定义一个损失函数,令损失函数最小化。
损失函数:
1. 误分类点的总数:这样的损失函数不是参数w,b的连续可导函数,不易优化;
2. 误分类点到超平面S的总距离:定义:感知机:![]() 的损失函数为:
的损失函数为:![]() ,M为误分类点的集合。
,M为误分类点的集合。
问题转化为求解:![]()
假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度:
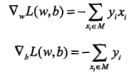
随机选取一个误分类的点,对w,b进行更新:
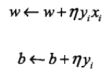
![]() 是步长,学习率。
是步长,学习率。
感知机具体算法:
输入:训练数据集![]() ;学习率
;学习率![]() ;
;
输出:w,b;感知机模型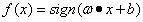
(1)选取初值![]()
(2)在训练集中选取数据![]()
(3)如果![]()
![]()
(4)转至(2),直至训练集中么有误分类点。
用汉语描述算法:当一个实例点被误分类,即位于分离超平面的错误一侧时,则调整w,b的值,使分离超平面向该误分类点的一侧移动,以减少误分类点与超平面的距离,直至超平面越过该误分类点使其被正确分类。