2019独角兽企业重金招聘Python工程师标准>>> 
摘要:在MaxCompute生态中,命令行工具究竟处于什么样的位置?它又发挥着什么样的作用?能够帮助开发者如何更好使用MaxCompute?在本文中,阿里巴巴计算平台产品专家曲宁将通过一个完整简单的小例子为大家介绍MaxCompute命令行工具odpscmd的使用以及其所具有的各种能力。
直播视频回看,戳这里!https://yq.aliyun.com/webinar/play/467
分享资料下载,戳这里!https://yq.aliyun.com/download/2946
以下内容根据演讲视频及PPT整理而成。
本文将主要按照以下五个方面进行介绍:
1. 命令行工具odpscmd在MaxCompute生态中的定位
2. 快速开始:一个完整简单的小例子
3. 客户端提供的能力框架
4. 客户端重点场景说明
5. 容易碰到的问题
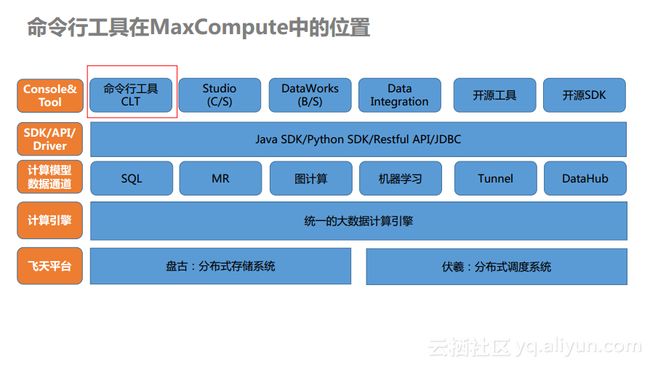
一、命令行工具odpscmd在MaxCompute生态中的定位
odpscmd其实就是MaxCompute的命令行工具的名称,其在整个MaxCompute中的位置是位于最上端的。如下图所示,整个MaxCompute生态自下而上是支撑的关系,而真正暴露给用户的是一套Rest API,这套API也是最核心的接口,无论是Java还是Python的SDK都需要调用这些核心API。而命令行工具就是对于MaxCompute开放的Rest API做了深度的包装,在客户端使得用户可以使用命令的方式来提交作业,这些作业又将会通过接口提交给MaxCompute集群进行相关的管理和开发。可能大家对于MaxCompute以及DataWorks这个组合比较熟悉,这是因为使用MaxCompute之前需要在DataWorks上面进行开通。实际上,MaxCompute自身也有一些生态工具,比如odpscmd以及MaxCompute Studio等。
二、快速开始:一个完整简单的小例子
在本部分中,将通过一个简单而完整的例子对使用odpscmd客户端进行数据处理的各个阶段进行介绍。在文中仅对于各个步骤进行简略描述,具体的实践操作详见视频分享。

作为MaxCompute的客户端工具,odpscmd与Hive CLI以及PSQL这样客户端工具是比较类似的,都是一个黑屏的操作管理工具。接下来为大家分享一个完整而简单的小例子,这个例子能够完整地覆盖大数据处理的各个环节,包括了环境准备、数据接入、数据处理加工以及数据消费。在大家常见的大数据场景中,业务数据往往分散在数据库以及其他的生产环境中,而定期会进行数据采集或者同步,将生产环境中的增量数据同步到数据仓库中去,这样就会涉及到数据接入。之后在数据仓库中就会周期性地做一些数据处理加工,这些加工有时候会用常见的SQL做,对于MySQL而言提供了MR这样的编程框架,而一些具有深度需求的用户则会通过UDF来实现一些比较复杂的业务逻辑,同时在数据加工的时候会需要监控作业的执行情况,所以也会有对于进度以及成功状态等的作业查看和管理的需求。作业处理完毕之后,这时候基本上完成了数据的清洗和聚合,这时候就可以提供给数据消费方使用。对于数据使用消费方而言,往往需要将加工好的可消费数据回流到业务系统来支撑在线应用,或者通过JDBC接口连接BI工具进行可视化分析,而业务分析师也往往希望下载一些数据进行二次加工和处理。
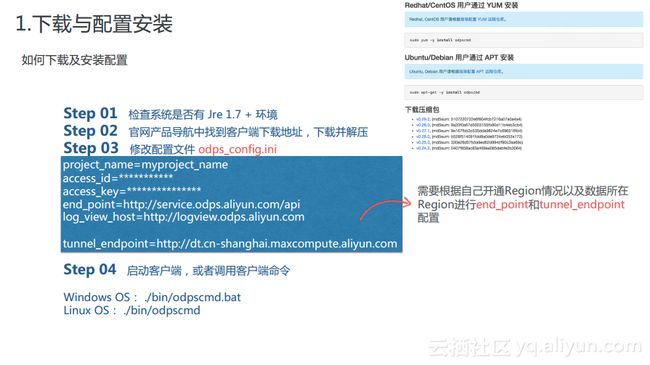
1.下载与配置安装
对于odpscmd而言,大家可以在官方网站上找到其下载地址,通过浏览器下载到本地的是一个ZIP包,解压之后就可以看到odpscmd一些相关目录。而对于Linux用户而言,也可以通过yarn源去下载并安装相应的包。下载完成之后,需要修改odps_config.ini配置文件,如下图蓝框中所示,需要录入项目名称,填写登录访问者所拥有的access_id和access_key等认证信息。同时,这里需要注意MaxCompute在国内的Region里面的end_point域名是一致的;而对于tunnel_endpoint而言,则是和Region密切相关的,所以对于不同的Region而言,所填写的tunnel_endpoint是不同的。在填写完配置文件之后就可以启动odpscmd客户端了。
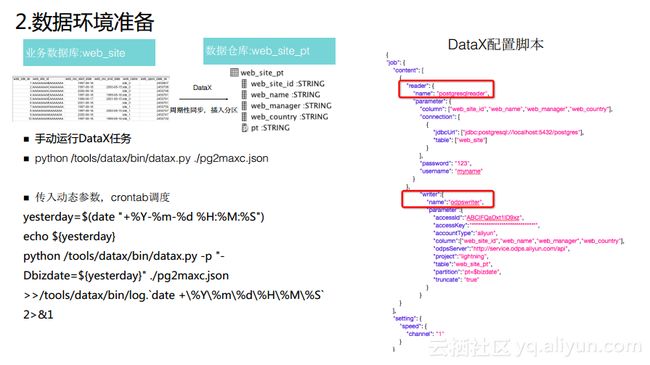
2.数据环境准备
对于使用odpscmd客户端的同学而言,往往会深度地使用shell以及一些开源的工具进行配合。这里举个例子,在业务数据库中有一张日常的业务表,可能存储了日常业务点击的日志以及新增的订单数据,那么常见场景是需要将数据同步到数据仓库,这个过程需要一些数据同步工具周期性地将数据加载到数据仓库的表里面,而且往往会需要建立相应的分区表,将相应的数据放入到相应的分区里面去。这一个任务可以通过开源工具DataX完成,实现将数据同步地插入到数据仓库表里面去。而当手工配置DataX命令时,有一些像分区字段这样的参数往往是动态的,所以也需要动态地放入到DataX脚本的参数当中。
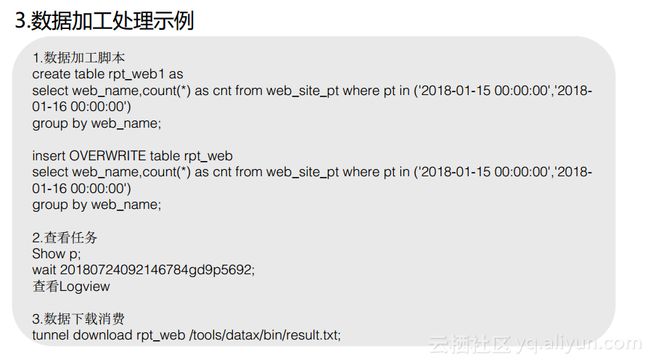
3.数据加工处理
当数据同步完成之后,在很多的场景中需要对一些分区表做加工处理,如下图所示的例子中是新建一张表或者insert OVERWRITE一张表,还会对于数据表中由于增量同步而引入的新的分区数据进行汇总聚合计算,并将结果生成到新表中。而当作业非常长的时候,odpscmd工具也提供了作业监控命令“Show p”,就能够检索出全量历史作业。而每个作业都会有自己的instance_id,而对于MaxCompute而言,最基本的任务单元就是instance,每个instance就是提交作业的实例。根据instance_id在事后还可以检索到其对应的Logview。总之,odpscmd本身就提供了完整的作业提交、作业事后查看以及对于指定作业详情的查看能力。在本次分享的例子中,使用的是Tunnel对于MaxCompute的结果数据集进行下载,并通过Excel或者其他的工具进行分析,因此执行tunnel download就能够将结果数据表下载到本地文件中。
三、客户端提供的能力框架
上述的内容其实是希望通过一个简单的例子将日常较为复杂的大数据处理流程和环节进行简单回溯,借此希望向大家传达MaxCompute客户端工具能够支持日常工作的各个环节。那么,MaxCompute客户端工具究竟有什么样的功能能够支撑各个环节的需要呢?其实,odpscmd的功能包含了对于项目空间的管理,对表、视图以及操作分区的操作管理,对资源、函数的管理,对作业实例的管理,并且提供数据上传下载的数据通道,同时也提供安全与权限管理等其他的操作。接下来就为大家依次介绍。
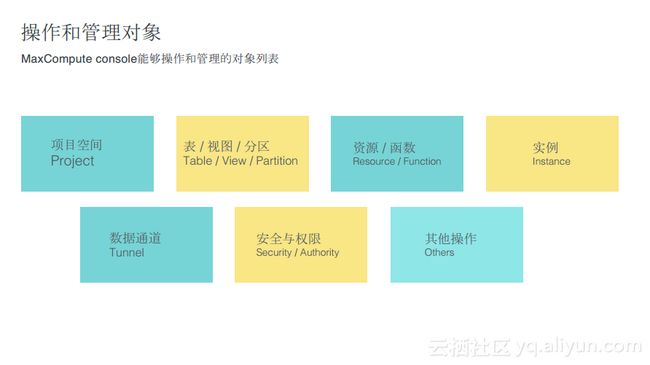
项目空间相关操作
在连接项目之前首先已经创建了一个MaxCompute项目,在使用项目的时候可以使用类似于Hive数据库一样“use
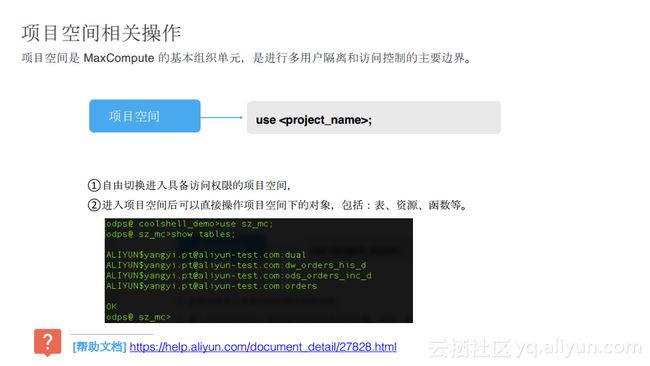
表相关操作
表相关操作的命令在odpscmd客户端工具上能够很轻松地进行操作,其包含了表的创建和删除以及对于表的修改,比如修改列名、修改分区、修改属主Owner、非分区数据的删除等。其他的操作诸如show tables也都兼容了Hive的使用习惯。在下图中为大家列出了与表相关的操作命令以及帮助文档。
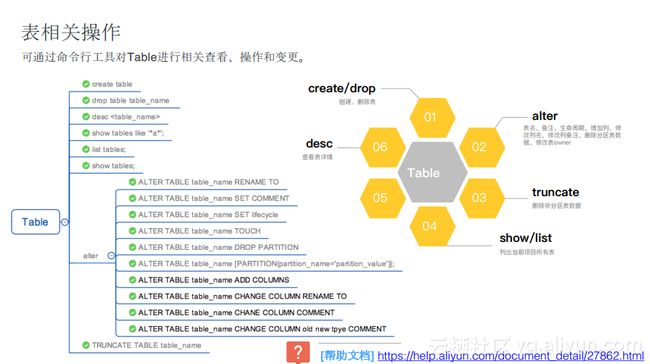
视图及分区相关操作
对于视图和分区而言,odpscmd也可以通过view方式把一些复杂的处理逻辑进行二次封装,更容易地对外进行暴露。对于view而言,提供了创建、修改、删除以及查看的操作。对于Partition而言,大家关注的也比较多,常见的就是如何查看表的分区,通过show partition <表名>的方式就能够列出这张表里面有多少个分区,同时分区的名称是什么。同时可以借助alter <表名>的方式将某一个分区删除掉或者修改其命名。
资源与函数相关操作
深度用户在使用时就会发现,很多内置函数不能够满足自身逻辑需求,往往会需要使用一些UDF来进行复杂计算,也可以通过MR来做更自由的计算逻辑,这些时候用户需要上传一个自定义开发包,这些对于MaxCompute而言就是资源Resource。通过odpscmd可以上传也可以查看项目中的资源。对于函数而言,用户创建UDF的时候,就可以使用create方式很容易地进行创建。

实例相关操作
对于实例而言,大家可能会在客户端运行很多作业,可能在某个时间想要看看作业是否已经运行完成了,但是又记不住作业的具体ID是什么,这时候就可以使用show p和show instance命令来列出提交过的历史作业,并且还支持按照时间等条件进行过滤。当instance列表获取之后,对特定的任务做操作还可以使用“wait”命令查看其详情。

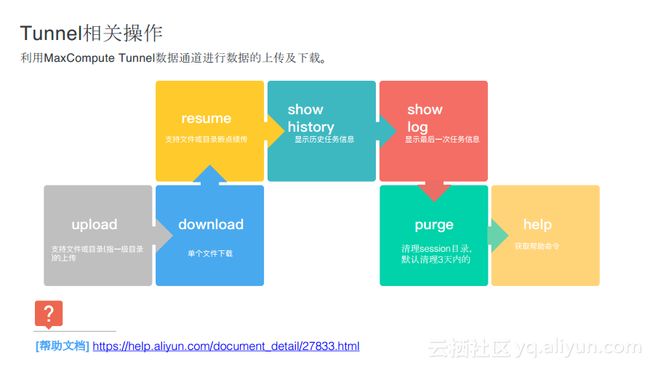
Tunnel相关操作
有一种操作命令实际上是提交给控制、管理、数据查询作业的命令,并且还有一部分是做数据的上下行,这有别于前面提到的任务提交,更多的是对于数据的吞吐量要求比较高,因此odpscmd集成了Tunnel工具,能够在命令行里面进行数据上传以及下载等。这里经常会遇到的问题就是很多开发者在自己的生产环境里面通过Tunnel做数据同步,而这时候对于断点续传的能力要求就会比较高了。
安全及权限相关操作
很多用户对于DataWorks比较熟悉,DataWorks里面有比较简单明了的用户角色授权管理的能力。而做数据库的一些同学则更加习惯于黑屏的方式,也就是通过命令方式做安全和权限的管理。

角色相关权限管理
比如对于角色相关权限的管理,可以通过create role可以在大数据项目中创建角色,并对角色赋权,将某一个用户加入到角色当中去,或者移除相关的角色。同时也能够查看究竟有哪些角色。

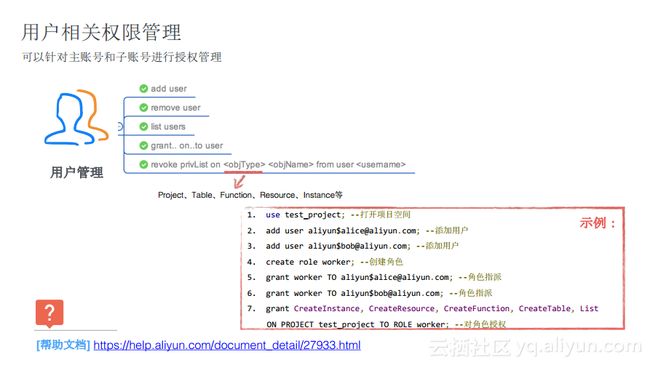
用户相关权限管理
对于用户相关权限管理而言,最常见就是将一个阿里云的账号加进项目中去,并为用户指定具体的角色,并获取对应的权限。
项目空间的数据保护
一些管理员对于项目空间的保护要求比较高,而在MaxCompute当中天然对于多租户支持方面做了很多工作。比如可以设置禁止项目数据被下载,仅允许几个授信的项目之间共享数据,这样就可以将与项目空间相关的权限保护能力都放在odpscmd中。

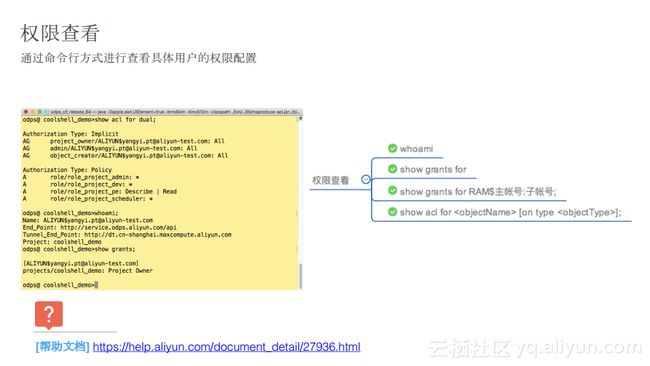
权限查看
同时,odpscmd也给出了权限查看相关的命令。
其他操作
odpscmd还提供一些其他常用的操作。大家可能经常会遇到一些性能优化的场景,比如对于一张比较大的数据表做扫描分区的切分,这样可以增加作业任务的并行度,这些优化手段的开关都可以通过命令行进行快速设置,同时也可以对于一些SQL进行成本预估,并且也可以轻松地获取帮助信息。综上所述,odpscmd是一个比较强大并且完整的客户端工具。

四、客户端重点场景说明
接下来重点分享几个客户端使用的重点场景。
场景1:通过shell脚本调用tunnel命令进行文件上下传
在这种场景下,默认会通过分隔符的方式进行上传。而当用户遇到了一些非标准化的分隔符时,通过-fd方式就能够快速适配对应的列分隔符。而很多同学也希望通过shell脚本的方式能够动态地进行调度,这里也会涉及到动态参数传入的问题。如下图中示例所示,可以将日期动态地传入到Tunnel命令当中去,周期性地将新增的日志文件上传或者下载到对应的目录中去。

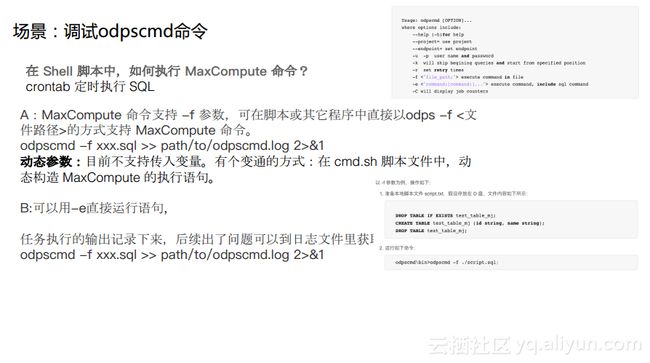
场景2:调试odpscmd命令
在非交互式的场景下,MaxCompute命令支持-f参数,可在脚本或其它程序中直接以odps -f <文件路径>的方式支持MaxCompute命令。此外MaxCompute命令还支持-e参数,在这种方式下需要通过括号的方式将SQL命令嵌入进去。
场景3:运行数据查询/数据加工作业UDF
在odpscmd里面能够原生地支持UDF和MR,如下图所示的是UDF作业的使用流程。

在前两个环节需要在线下将写好的UDF编写好的程序打成Jar包,在命令行当中通过“add jar”的方式把其传入到指定的项目中作为一个资源。而通过createfunction命令可以命名一个自定义函数并于上传的主函数进行关联,这样就真正地建立了这样的一个函数。之后在测试或者使用的时候通过调用刚才创建的UDF进行使用。这样就是通过odpscmd实现UDF的完整创建。
场景4:运行数据查询/数据加工作业MR
对于MR作业而言,首先需要在编译环境中编写并打包MR程序,打包完成之后将其作为一个资源注册到项目之中,在odpscmd里面执行“add jar”,之后在命令行里面运行MR作业,之后就可以获得相应的结果。

五、容易碰到的问题
接下来为大家总结了几个常见的问题。首先是动态参数的传入,因为odpscmd是一种命令行的方式,那么大家通过shell调用的比较多,这时候就涉及到如何将一些动态的参数调入进去,其实可以通过shell的方式变相地将一些动态信息传递进来。还有一个常见的问题就是“手工执行odpscmd命令正常,通过shell脚本调用时报错”,此时就需要检查shell脚本下有没有设置JAVA的环境变量。

总结
本文主要通过一个简单而又完整的例子具体地描述了借助MaxCompute客户端进行数据加工处理的流程。同时,也为大家介绍了MaxCompute客户端工具所具有的功能,其不仅仅能够实现建表、查数据,还能够实现很多的管理工作。此外,还给大家很多指引性的知识,希望大家能够通过本次分享更好地了解MaxCompute客户端的使用方式。
作者:午夜漫步者