“Keras 四步法”快速搭建神经网络模型
Keras 为支持快速实验而生,能够将我们的一些想法和方案迅速转换为结果, 是一个高层神经网络 API,由纯 Python 编写而成,以 TensorFlow和Theano 为后端。
Keras 有以下一些特点:
- 简易和快速的模型设计;
- 极简,对用户友好;
- 支持CNN和RNN,或二者的结合;
- 无缝CPU和GPU切换;
- 高度模块化:模型可理解为一个层的序列或数据的运算图,完全可配置的模块可以用最少的代价自由组合在一起。网络层、损失函数、优化器、初始化策略、激活函数、正则化方法 都是独立的模块,我们可以使用它们来构建自己的模型;
- 易扩展性:添加新模块超级容易,只需要仿照现有的模块编写新的类或函数即可;
- 与Python协作,适用的Python版本有:Python 2.7 - 3.6。
我在前面的文章介绍过 Anaconda 软件概述和Anaconda下的Jupyter NoteBook安装及使用,
可以快速构建Keras 运行环境:Anaconda + Jupyter Notebook + Keras(Using TensorFlow as Backend)。
在 Anaconda 软件中先选择 Environments,再选择 / 创建一个自己的环境(一般默认为 base(root) ),搜索“ Keras ”,选中自己所要的Keras,点击“ Apply ”进行安装。
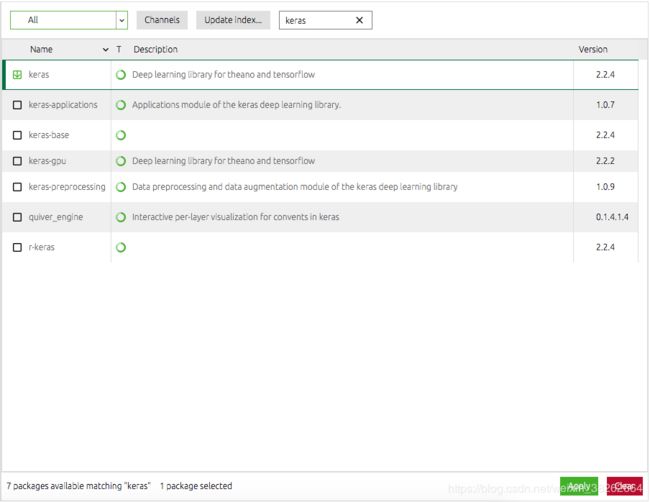 Keras搜索与安装
Keras搜索与安装
然后按照Anaconda下的Jupyter NoteBook安装及使用中介绍的启动 Jupyter NoteBook 并创建一个 Python 3 文件,就可以开始快速搭建 Keras 神经网络模型。
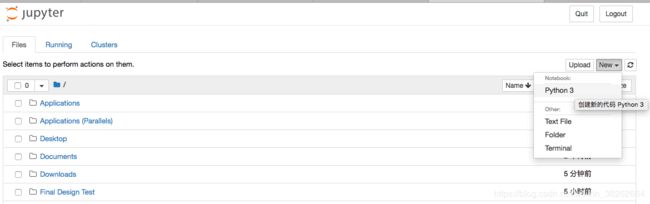 创建Python 3文件
创建Python 3文件
在进行搭建模型前,得事先准备好数据:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
# 导入 iris 数据集
iris = datasets.load_iris()
X = iris.data
Y = iris.target
# 处理二分类问题,所以只针对 Y = 0,1的行,然后从这些行中取 X 的前两列
x = X[Y<2,:2]
print(x.shape)
y = Y[Y<2]
print(y.shape)
# 将数据分为:训练集、测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.8, random_state = 6)
利用 Keras 搭建神经网络模型非常快速和高效,其模型实现的核心流程可以用四个步骤来概括,具体如下:
1、搭建网络结构(add):
调用 Keras 神经网络的各个模块来组件我们的模型架构,通过 “ add 方法”来叠加。这一步是最需要仔细考虑的地方,关乎我们神经网络的复杂性和高效性。
首先进行将 Sequential 实例为 model,
from keras.models import Sequential
model = Sequential() # 类的实例化
然后从 Keras 的 layers 模块中导入 Dense 全连接层,
构造一个包含两个全连接层(一个用 relu 激活函数,另一个用 softmax 激活函数)的网络模型。
# 可以看作为前向传播:Forward Propagation(FP)
from keras.layers import Dense
model.add(Dense(units = 100, activation = 'relu', input_dim = 2)) # relu 激活函数,输入数目100,维度2
model.add(Dense(units = 2, activation = 'softmax')) # softmax 激活函数2、将搭建好模型进行编译(compile):
# 超参数:在算法运行前需要设定的参数(通过领域知识、经验数值、实验搜索来寻找好的超参数)
# 模型参数:算法 / 模型运行过程中所学习到的参数
# 得到正确率之后,想要进一步的提升在测试集上的正确率,我们就需要对模型进行调参。
# 可供选择超参数有不少,作用不尽相同,可根据自己设计所需进行选择以达到期待效果
# 损失函数 loss:categorical_crossentropy(交叉熵);优化器 optimizer:sgd(随机梯度下降);评价指标 metrics:accuracy(准确度)
model.compile(loss = 'sparse_categorical_crossentropy',
optimizer = 'sgd',
metrics = ['accuracy'])
另外,可以进一步配置优化器,配置学习率等,如下所示:
# 可以看作为反向传播:Backpropagation(BP)
# 可以进一步配置优化器
# 损失函数 loss:categorical_crossentropy(交叉熵)
# Stochastic Gradient Descent(SGD):随机梯度下降
# Learning Rate(lr):学习率
model.compile(loss = keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.SGD(lr = 0.01, momentum = 0.9, nesterov = True))
3、对训练数据进行拟合训练(fit):
# 输入“训练集”数据,训练轮数 epochs:5,批训练的数据个数 batch_size:32,可以批量迭代训练数据
# 训练轮数增多,整体运行时间增加
# 每轮喂入量越多,计算量越大,耗时长。刚开始训练可以选择5-15之间进行喂入,根据结果进行修改,但不建议过大
# 修改模型建议:自己多尝试修改下 batch_size 值
model.fit(x_train, y_train, epochs = 5, batch_size = 32)
4、对训练好的模型进行评估(evaluate):
# 输入“测试集”数据,批训练的数据个数 batch_size:128
loss_and_metrics = model.evaluate(x_test, y_test, batch_size = 128)
print(loss_and_metrics) # 显示 loss 值和精确度值
运行结果:
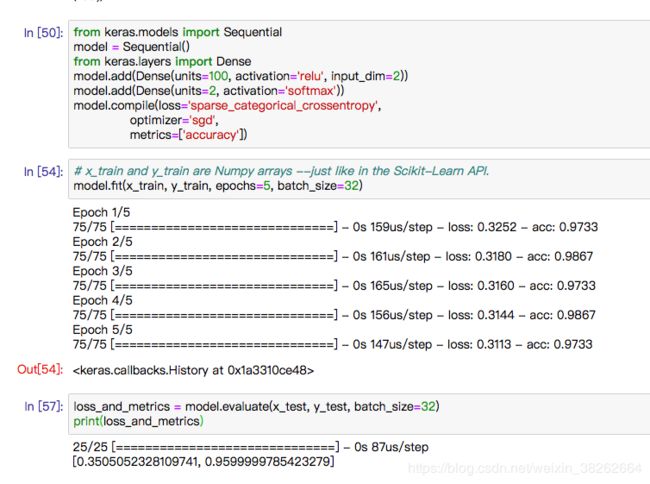 运行结果
运行结果
这样我们就用 Keras 将神经网络模型快速搭建完成了,之后我们可以对模型进行调整和优化,比如:修改超参数,选择不同的损失函数,修改学习率lr,换用其他激活函数等等。
因此,创建新模块的便利性使得Keras更适合于先进的研究工作。