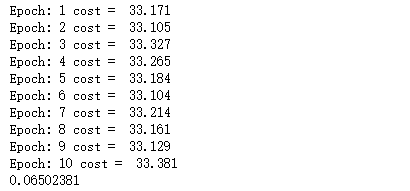TensorFlow入门,简单实现全连接神经网络----Kaggle经典数据集Digit Recognizer
本文源代码与数据集链接:https://github.com/wait1ess/kaggle-10-most-popular-dataset
(1)导入所需要的库,利用pandas导入CSV训练数据集以及测试集,对数据进行预处理
import numpy as np
import pandas as pd
import warnings
import tensorflow as tf
warnings.filterwarnings('ignore')
dpath='D:/kaggle-10-most-popular-dataset/3-Digit Recognizer//'
train=pd.read_csv(dpath+'train.csv')
test=pd.read_csv(dpath+'test.csv')
train.head(5) # 训练集前五行数据 5 rows × 785 columns 第一列为label
test.head(5) # 测试集前五行数据 5 rows × 784 columns
print(np.shape(train))
print(np.shape(test))
Ytrain=np.array(train.copy()['label']) # 提取lebal
np.shape(Ytrain)
Ytrain.reshape(42000,-1) # 直接提取为rank1array,需要对其进行重塑
Xtrain=np.array(train.drop(['label'],axis=1)) # 提取特征
np.shape(Xtrain)
(2)定义超参数和占位符tf.placeholder,占位符是TensorFlow对象,用于输入输出数据的格式,允许传入指定类型和形状的数据并以来计算图的计算结果;占位符需要输入三个参数:数据类型,数据大小以及占位符名称;占位符需要通过会话tf.Session的feed_dict参数获取数据
#超参数
learning_rate=0.05
epochs=10
batch_size=100
#placeholder
#输入图片为28 x 28像素=784
x=tf.placeholder(tf.float32,[None,784]) #None代表任意值,特别对应tensor数目
#输出为0-9的one-hot编码
y=tf.placeholder(tf.float32,[None,10])
(3)定义变量tf.variable,变量是机器学习中的模型参数,TensorFlow通过维护(调整)这些变量的状态来优化模型
#定义参数w和b
#hidden layer
w1=tf.Variable(tf.random_normal([784,300],stddev=0.03),name='w1')
b1=tf.random_normal([300],name='b1')
#output layer
w2=tf.Variable(tf.random_normal([300,10],stddev=0.03),name='w2')
b2=tf.random_normal([10],name='b2')
(4)声明操作(神经网络中的矩阵运算,激活等)
#构造隐层网络
#hidden layer
hidden_out=tf.add(tf.matmul(x,w1),b1) #相当于矩阵乘法 z=w1x+b1
hidden_out=tf.nn.relu(hidden_out) #h=relu(z)
#构造输出(预测值),实现激活函数(位于tf.nn库)
y_=tf.nn.softmax(tf.add(tf.matmul(hidden_out,w2),b2)) #相当于矩阵乘法 u=w2h+b2
#定义loss 损失函数
#多分类label,损失设定为交叉熵
#分为两步:
#1.对n个标签计算交叉熵
#2.对m个样本取平均
y_clipped=tf.clip_by_value(y_,1e-10,0.999999)#压缩预测值y_在0-1之间,小于min的使其等于min,大于max的使其等于max
cross_entropy=-tf.reduce_mean(tf.reduce_sum(y*tf.log(y_clipped)+(1-y)*tf.log(1-y_clipped),axis=1)) #计算交叉熵(损失函数)
#定义优化器
#创建优化器,确定优化目标
optimizer=tf.train.GradientDescentOptimizer(learning_rate=learning_rate).minimize(cross_entropy) #优化算法为梯度下降
#创建准确率节点
#correct_prediction为一个m x 1的tensor,tensor的值为True/False表示是否预测正确
#tf.argmax(vector, 1):返回的是vector中的最大值的索引号,如果vector是一个向量,那就返回一个值,如果是一个矩阵,那就返回一个向量,这个向量的每一个维度都是相对应矩阵行的最大值元素的索引号
correct_prediction=tf.equal(tf.argmax(y,axis=1),tf.argmax(y_,axis=1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
(5)全局变量初始化
注:如果你希望某个变量不要被训练,那可以放在这个集合里:tf.GraphKeys.LOCAL_VARIABLES
init_op=tf.global_variables_initializer()
(6)多分类label的One-Hot
def convert_to_one_hot(y, C):
return np.eye(C)[y.reshape(-1)].T
Ytrain=convert_to_one_hot(Ytrain,10)
(7)批量梯度下降
def next_batch(train_data, train_target, batch_size):
index = [ i for i in range(0,len(train_target)) ]
np.random.shuffle(index);
batch_data = [];
batch_target = [];
for i in range(0,batch_size):
batch_data.append(train_data[index[i]]);
batch_target.append(train_target[index[i]])
return batch_data, batch_target
(8)创建会话tf.Session,一个tf.Session对象封装了Operation执行对象的环境,并对Tensor对象进行计算
#创建session
with tf.Session() as sess:
# 变量初始化
sess.run(init_op)
total_batch = int(len(Ytrain) / batch_size)
for epoch in range(epochs):
avg_cost = 0
for i in range(total_batch):
batch_x, batch_y =next_batch(Xtrain,Ytrain,batch_size=batch_size)
_,c=sess.run([optimizer, cross_entropy], feed_dict={x: batch_x, y: batch_y})
avg_cost += c / total_batch
print("Epoch:", (epoch + 1), "cost = ", "{:.3f}".format(avg_cost))
print(sess.run(accuracy, feed_dict={x: Xtrain, y: Ytrain}))
最终运行结果如下: