聚类分析实验(一)数据预处理
咚咚咙咚锵,总算,我做完了实验,可以开始写…博客了o( ̄▽ ̄)o,现在进入正题,要实验验证聚类分析算法,第一步就是(^_~)获取数据
数据搜集
在进行正式的实验前,需要获取数据,我是用的是博主共享的开源数据25个常用的深度学习开源数据集从blogger.com收集到的19,320名博主的博客,其中博主的信息包括博主的ID、性别、年龄、行业及星座。
当然如果各位对于爬虫感兴趣,也可以抓取网站上的用户信息,切记:非商业用途,倒卖个人信息是…犯法的(跑题了( ̄▽ ̄)")
数据“预处理”
数据预处理可以理解为讲脏数据经过处理,得到干净可用的数据,目前进行的事实上还是获取可用数据的过程~
- 获取文件名
点击xml文档,就可以直接跳转,里面存储的是关于博主发的博客信息,而事实上,我们只需要对博主的身份信息进行提取,恰好数据的标题就是我们需要的内容。
import os #os模块是操作系统的接口,常常实现对大量文件和大量路径做操作
import xlwt
path = r"F:\blogs/" #请输入文件路径(结尾加上/):
# 获取该目录下所有文件,存入列表中
f = os.listdir(path)
#创建excel表格
ex = xlwt.Workbook()
sheet1 = ex.add_sheet('blogs', cell_overwrite_ok=True)
row0 = ["ID", "gender", "age", "job", "constellation"]
n = 0
for i in f:
sheet1.write(n, 0, f[n])
n += 1
ex.save('D:\pycharm\me.txt')
代码运行之后,就会生成一个名为me的txt文件

- 写入excel
文本文件比较不容易操作,那么我们要将文本文件写入excel,同时这里发现ID和文件后缀名xml都可以不要。
import xlwt
txtname = 'D:\pycharm\me.txt'
excelname = 'blogs.xls'
fopen = open(txtname, 'r')
lines = fopen.readlines()
file = xlwt.Workbook(encoding='utf-8', style_compression=0)
# 新建一个sheet
sheet = file.add_sheet('data')
i = 0
for line in lines:
line = line.strip('\n')
line = line.split('.', 6)
id = line[0]
gender = line[1]
age = line[2]
job = line[3]
constellation = line[4]
#sheet.write(i, 0, id)
sheet.write(i, 0, gender)
sheet.write(i, 1, age)
sheet.write(i, 2, job)
sheet.write(i, 3, constellation)
i = i + 1
file.save(excelname)
处理之后,就生成了一个excel
- 文本转数值
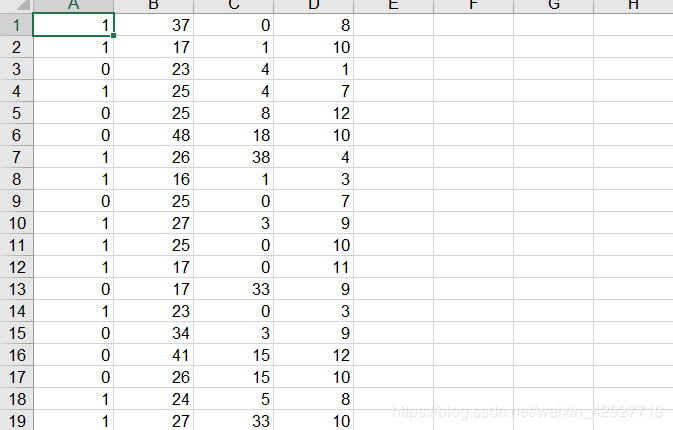
基于文本的聚类分析也有,但一般还是基于数值型数据,所以这个阶段我们要将性别、职业、星座转换成数值,我为了防止自己记错,所以做了一个对照表。

我将职业按照从业人数排序并编号(可能对数据有一定影响,如果大家有更好的办法欢迎留言!<( ̄︶ ̄)↗[GO!])

然后得到了一个这样的矩阵19320*4维的矩阵
好啦,实验的第一步就先到这里!