机器学习简述
一.机器学习介绍
1.什么是机器学习?
机器学习是人工智能的一个分支,它是研究计算机如何模拟或实现人类的学习行为,以及获取新的的数据重新组织已有的知识结构使之不断改善自身性能的一种方法,能够实现直接编程无法完成的功能。总结来说,机器学习是对能通过经验自动改进的计算机算法的研究。在具体介绍之前,我们看下人类是如何学习的:
人类在成长、生活过程中会经历很多事情,积累很多的历史与经验。人类会定期对这些经验进行归纳,从中提炼出规律。当人类遇到未知的问题或者需要对未来进行推测的时候,人类使用这些规律,对未知问题与未来进行推测,从而指导自己的生活和工作。
机器学习的思想与之类似,机器学习通过历史数据训练出模型对应于人类对经验进行归纳的过程,机器学习利用模型对新数据进行预测对应于人类利用总结的规律对新问题进行预测的过程。
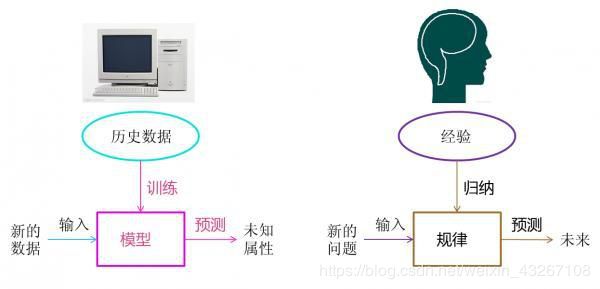
机器学习与人类学习的比较
2.发展历程
推理期
赋予机器逻辑推理的能力。
这一阶段于二十世纪五十年代出现到七十年代初,是人工智能发展的初期,五十年代中期基于神经网络的连接主义学习开始出现,代表性工作有感知机,自适应线性神经网络(Adaline);六七十年代,基于逻辑表示的符号主义学习开始发展,代表性工作有结构学习系统,基于逻辑的归纳学习系统,概念学习系统等。
知识期
使机器拥有知识。
到二十世纪七十年代中期,人们逐渐认识到仅具有逻辑推理远远无法实现人工智能,必须让机器拥有知识,这一阶段出现大量专家系统,在很多应用领域取得大量成果。
学习期
使机器能够学习。
二十世纪八十年代,专家系统面临瓶颈,由人总结知识再教给计算机是相当困难的,人们希望机器能够自己学习知识。这一阶段,以决策树和基于逻辑的学习为代表的符号主义学习和基于神经网络的连接主义学习是两大主流;
二十世纪九十年代中期,由于连接主义学习技术的局限性凸显后,人们把目光转向基于统计学习理论的统计学习技术,以支持向量机(SVM)为代表的统计学习开始登场并迅速成为主流;
二十一世纪初,由于计算机硬件计算能力等进一步提升和人类社会大量数据的产生,连接主义卷土重来,掀起深度学习的热潮,深度学习狭义来讲就是拥有很多层的神经网络,在语音,图像等应用中取得优越性能。
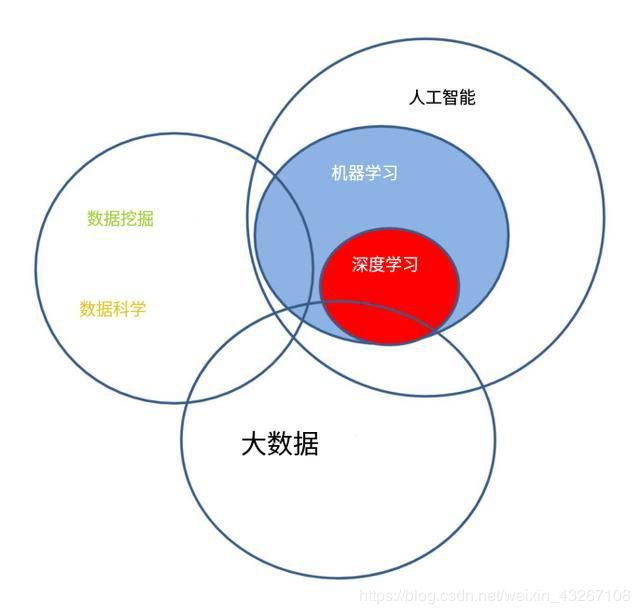
机器学习与其他领域关系
3.运用
机器学习和众多学科联系密切,在计算机视觉,语音识别,自然语言处理,数据挖掘等应用领域影响巨大,在许多交叉学科也提供了重要的技术支撑,例如生物信息学,天文学等科学研究领域,科学研究从传统的"理论+实验"逐渐转向"理论+实验+计算",数据分析效率的提升对促进科研发展的速度至关重要。
如今,机器学习与普通人的生活密切相关。在金融领域,利用机器学习技术对风险进行评估,帮助制定不同的投资策略;商业营销中利用机器学习技术对销售数据、客户信息进行分析,可以帮助商家优化库存降低成本,还能针对用户群进行精准营销;在天气预报、能源勘探、环境监测等方面,利用机器学习技术对卫星和传感器传回的数据进行分析,提高了预报和检测准确性;甚至影响到人类社会政治生活,2012美国大选期间,奥巴马麾下的机器学习团队对社交网络等选情数据源进行分析,判断总统候选人辩论后选民倒戈的情况,根据结果开发个性化宣传策略,有策略地进行拉票活动,既取得大量收获,又节省了竞选经费。

机器学习学科交叉应用
4.三要素
机器学习的过程可以总结为三个主要部分,分别为模型、策略和算法。
模型
模型就是用来描述客观世界的数学模型,它可以是条件概率分布P(Y|X),也可以是决策函数Y = f(X),具体作用就是用来描述我们已经观测到的数据,是从数据里抽象出来的。模型的假设空间包含了所有可能的条件概率分布或决策函数,首先要对模型进行假设,假设一旦确定,假设空间的规模就确定下来,我们可以把学习的过程看作一个在所有假设组成的空间中进行搜索的过程。
策略
有了模型的假设空间,我们就要考虑按照什么样的标准从中选择最优模型,策略就是从假设空间中选择最优模型的一个评价标准,策略可以分为损失函数(loss function)/代价函数(cost function)和风险函数(risk function)这两个概念;
• 损失函数:用于度量模型一次预测的好坏,以监督学习为例,损失函数就是比较预测值和真实值之间的差距,差距越小,就代表模型拟合越好。常用损失函数有:0-1损失函数,绝对值损失函数,log对数损失函数,平方损失函数,指数损失函数,Hinge损失函数,感知损失函数等;
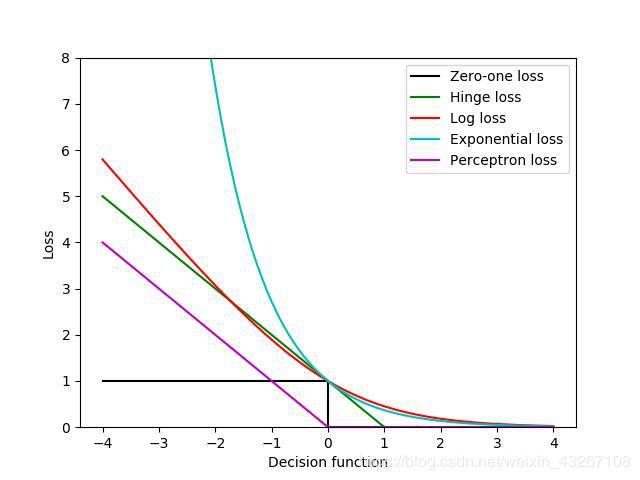
• 风险函数:平均意义下的模型预测的好坏,相当于损失函数的期望(期望风险)。风险函数可以细分为经验风险和结构风险;
经验风险:模型关于训练数据集的平均损失(样本趋近于无穷时, 经验风险趋近于期望风险);
结构风险:防止过拟合的策略, 模型越复杂, 结构风险越大,结构风险最小化等价于正则化。
算法
根据评价标准制定后的最终策略称为目标函数,算法就是对目标函数求解最佳参数组合的过程,目标就是找到或接近全局最优解,所以也叫做最优化算法,可以理解为调参(训练)的过程,参数确定后就能得到模型了。常见的优化算法有:梯度下降算法,随机梯度下降,牛顿法,拟牛顿法,启发式优化方法,最大期望算法(EM算法)等。
二.机器学习模型分类
1.监督学习
监督学习是从标记的训练数据学习一个模式,用于对新数据进行预测或分类。监督学习主要分为三类,分别为回归,分类,标注。
回归
回归是监督学习的一个重要问题,用于预测输入变量(自变量)和输出变量(因变量)之间的关系,回归模型表示从输入变量到输出变量之间映射的函数。所以回归问题等价于函数拟合:选择一条函数曲线使其拟合已知数据并能预测未知数据。常见回归模型有:线性回归,岭回归(L2正则化的线性回归),Lasso回归(L1正则化的线性回归),多项式回归(非线性回归),支持向量回归(SVR)等。常用于预测价格走势,分数等数值连续变化的场景。
分类
分类是监督学习的另一个重要问题,当输出变量Y取有限个离散值时,预测问题便成为分类问题。其主要目的是将不同类型的样本分隔开。常见分类模型有:逻辑斯谛回归,决策树,朴素贝叶斯,K近邻(KNN),最大熵模型,感知机,支持向量机(SVM),神经网络,集成模型里的梯度提升树(GBDT),Adaboost,随机森林(Random Forest)等。分类模型在众多领域有广泛应用,例如风险评估,文本分类,邮件过滤,图像识别等。
标注
标注问题是分类问题的一个推广,输入是一个观测序列,输出是一个标记序列或状态序列。标注模型的目的是对观测序列输出标记序列进行预测。常见标注模型有:隐马尔可夫模型(HMM),条件随机场(CRF)等。常用于自然语言处理,语音识别等。
2.无监督学习
无监督学习不需要进行人工标记数据,直接从无标记的数据样本里学习到数据的内在性质和规律。常用聚类的方式对数据规律进行提取。代表模型有:K均值算法(K-means)。由于标记数据的成本很高,现实中很多数据是没有标签的,这使得无监督学习有很广的应用场景,例如组织计算机集群,社交网络分析,市场划分,天文数据分析,推荐系统,搜索引擎等。
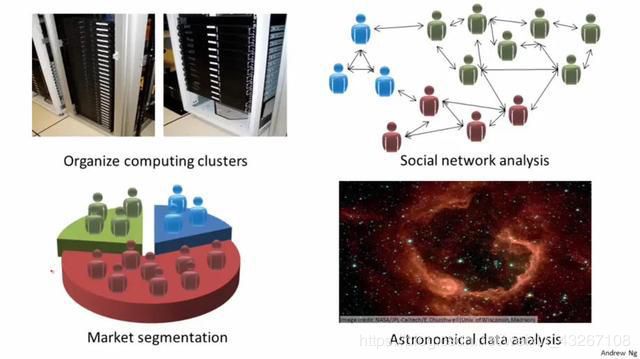
无监督学习应用场景
3.强化学习
强化学习是机器学习的一个重要分支,强化学习的主要任务就是通过在环境中不断地尝试,根据获得的反馈信息调整方案,最终生成一个较好的方案,机器根据这个方案便能知道在什么状态下应该执行什么动作,一个方案的优劣取决于长期执行这一方案后的累积奖赏。强化学习和监督学习类似,不同的是监督学习的训练样本是有标签的,且数据样本是人为给定的,强化学习没有标签,它是与环境进行交互然后通过环境给出的奖惩进行学习,数据会在交互过程中不断产生。常见模型:K-摇摆赌博机(K-armed bandit)。强化学习在许多领域都有研究,例如控制理论,经济学,博弈论等,在机器人控制,通讯,游戏等应用方面表现很好,像AlphaGo在围棋比赛上大放异彩,升级版的AlphaGo Zero只采用强化学习自我对弈,短时间内就超过了配合人类棋谱训练的Master,都给人带来深刻印象。随着研究的深入,强化学习将会发挥越来越大的作用。
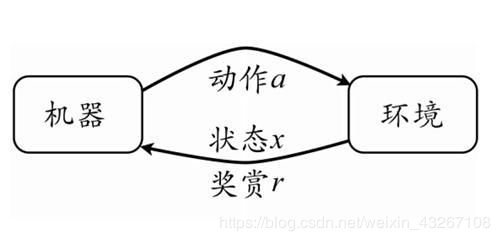
强化学习的过程
来自:http://www.sohu.com/a/280365385_99930730