JDK+Hadoop安装配置、集群模式搭建
1.VMWare 12安装激活和CentOS7安装
https://jingyan.baidu.com/article/6079ad0ec6275928ff86dbb7.html
3.SecureCRT安装
https://jingyan.baidu.com/article/c1a3101ea80badde656deb83.html
5.JDK+Hadoop安装配置
JDK+Hadoop安装配置、集群模式搭建
以下操作在SecureCRT里面完成
1.关闭防火墙
firewall-cmd --state 显示防火墙状态running/not running
systemctl stop firewalld 临时关闭防火墙,每次开机重新开启防火墙
systemctl disable firewalld 禁止防火墙服务。
2.传输JDK和HADOOP压缩包
SecureCRT 【File】→【Connect SFTP Session】开启sftp操作
put jdk-8u121-linux-x64.tar.gz
put hadoop-2.7.3.tar.gz
传输文件从本地当前路径(Windows)到当前路径(Linux)


3.解压JDK、HADOOP
tar -zxvf jdk-8u121-linux-x64.tar.gz -C /opt/module 解压安装
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/module 解压安装
4.配置JDK并生效
vi /etc/profile文件添加:
export JAVA_HOME=/opt/module/jdk1.8.0_121
export PATH= J A V A H O M E / b i n : JAVA_HOME/bin: JAVAHOME/bin:PATH
Esc :wq!保存并退出。不需要配置CLASSPATH。
source /etc/profile配置生效
javac检验是否成功
或者在/.bashrc文件里添加JAVA_HOME,可以对不同用户设置不同配置权限。
5.配置HADOOP并生效
vi /etc/profile文件添加:
export HADOOP_HOME=/opt/module/hadoop-2.7.3
export PATH= H A D O O P H O M E / b i n : HADOOP_HOME/bin: HADOOPHOME/bin:HADOOP_HOME/sbin:$PATH
Esc :wq!保存并退出。
source /etc/profile配置生效
hadoop检验是否成功
5.本地模式配置
hadoop -env.sh
vi /opt/module/hadoop-2.7.3/etc/hadoop/hadoop-env.sh文件修改
显示行号 Esc :set number 取消行号Esc :set nonumber
修改第25行export JAVA_HOME=/opt/module/jdk1.8.0_121
Esc :wq!保存并退出
本地模式没有HDFS和Yarn,配置JDK后MapReduce能够运行java程序。
6.运行自带程序wordcount
cd /opt/module/hadoop-2.7.3/share/hadoop/mapreduce 转入wordcount所在路径
touch in.txt 创建In.txt文件
vi in.txt 输入要统计词频的文字(这里不知道怎么弄,所以没弄)
hadoop jar hadoop-mapreduce-examples-2.7.3.jar wordcount in.txt output/
运行wordcount,output目录必须不存在,程序运行之后自动创建。
Hadoop伪分布式模式配置
只有一台虚拟机bigdata128,4个配置文件:
- core-site.xml
先创建临时文件夹:sudo mkdir -p /opt/module/hadoop-2.7.3/tmp
1、vi ${HADOOP_HOME}/etc/hadoop/core-site.xml
打开文件后,光标移到< /configuration>这对标签下,
按 i 然后复制下面相应的红字内容,然后esc :wq!保存退出
- hdfs-site.xml
vi ${HADOOP_HOME}/etc/hadoop/hdfs-site.xml
- mapred-site.xml
1、vi ${HADOOP_HOME}/etc/hadoop/mapred-site.xml
(该配置文件不存在,先复制)cp mapred-site.xml.template mapred-site.xml这些可以不管)
2、打开后文件是空的,复制下面内容到里面即可 (内容过多,复制后有可能内容会不全,记得检查一下)
vi ${HADOOP_HOME}/etc/hadoop/yarn-site.xml
添加配置如下:
回到管理员下 cd ~ 然后启动:
启动: start-all.sh

我也不知道yes还是no,所以就选了yes
![]()
接着就是要输管理员密码
进入dfs
![]()
JPS命令查看是否已经启动成功,有结果就是启动成功了。
下面这个图是老师的,我的跟她的有些地方不同。(我的差了一个SecondaryNameNode)执行这句后再查就有了
${HADOOP_HOME}/sbin/hadoop-daemon.sh start secondarynamenode

Hadoop完全分布式模式配置
关闭虚拟机和软件,找到虚拟机所在文件夹
并复制虚拟机文件夹在当前目录下 名字可改可不改 改了原来的虚拟机就不可用需要重新打开
打开vm,主页选择打开虚拟机(如果上面改名字的时候没有改原来虚拟机文件夹的名字的话就可以直接打开原来的虚拟机)
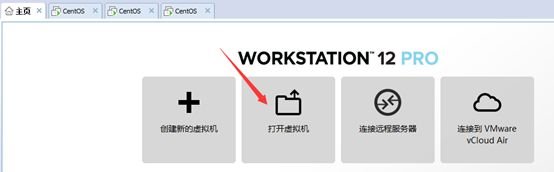
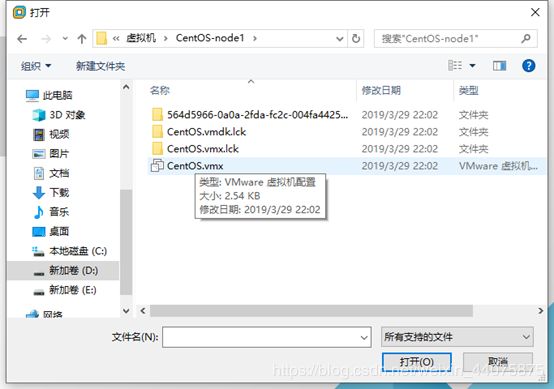
在弹出窗口找到复制的虚拟机的文件夹,选择.vwx文件并打开(注:如果原来那个虚拟机的文件夹改了名字,在打开这个虚拟机时选择我移动了虚拟机)另外两个选择我已复制该虚拟机
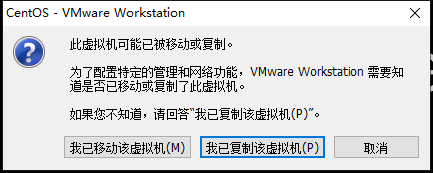
打开三个虚拟机
更改主机名:第二台虚拟机更改为bigdata129第三台为bigdata130
hostnamectl set-hostname bigdata129
hostnamectl --pretty
hostnamectl –static
reboot –f 重启就改好了

打开CRT
像前一个一样新建两个连接,ip默认是在原虚拟机ip最后加1,如果连接不上可以在虚拟机上查看 ip addr
在crt选择原虚拟机(128那台)进行下面的操作

共3个虚拟机,前述伪分布式的bigdata128作为master,克隆另外两个虚拟机slaves:
输入 vi slaves 修改配置文件
![]()
配置hosts文件
bigdata129、bigdata131,克隆机自带安装JDK、Hadoop及配置文件。
3个虚拟机都修改slaves,添加两个子节点:
vi /opt/module/hadoop-2.7.3/etc/hadoop slaves
bigdata128
bigdata129
bigdata131
上面划线的操作我的会出错(是不能保存吧),所以我没做
vi /etc/hosts
3个虚拟机都修改\etc\hosts,注释已有内容,添加集群3个虚拟机的ip及对应主机名:(每个人的IP不同,注意修改 截图是我的 )
192.168.163.128 bigdata128
192.168.163.129 bigdata129
192.168.163.131 bigdata131

3个虚拟机各自修改\etc\hostname,添加各自的主机名bigdata128或者bigdata129或者bigdata131。
重启全部虚拟机,主机名生效。这里上面已经做过了,划线这里可以不管
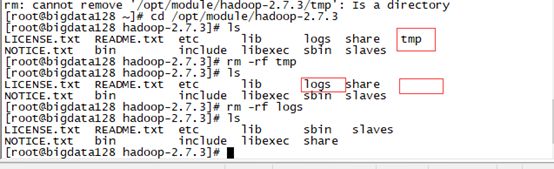
3个虚拟机都删除\opt\module\hadoop-2.7.3\d的tmp、logs目录:
rm –rf \opt\module\hadoop-2.7.3\tmp rm –rf \opt\module\hadoop-2.7.3\logs
(若无法删除,先进入hadoop目录 cd /opt/module/hadoop-2.7.3 然后再删除 rm –rf tmp 复制有可能出错建议手打)
Logs也一样 三台虚拟机都删除
格式化master: hdfs namenode -format
启动master: start-all.sh

启动正常jps显示3台主机如上如下

启动正常创建目录如下
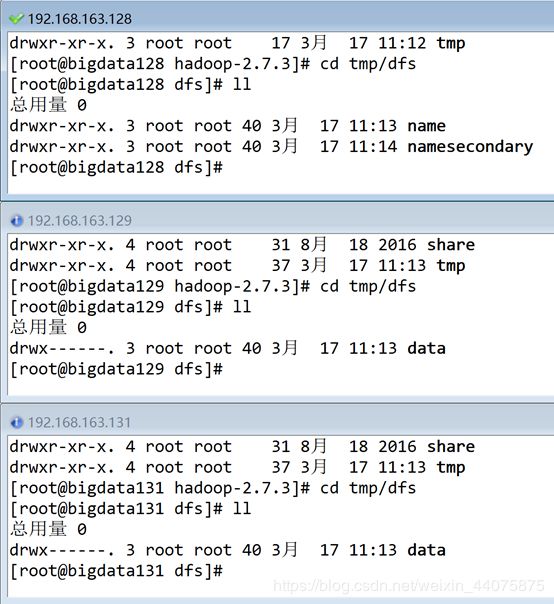
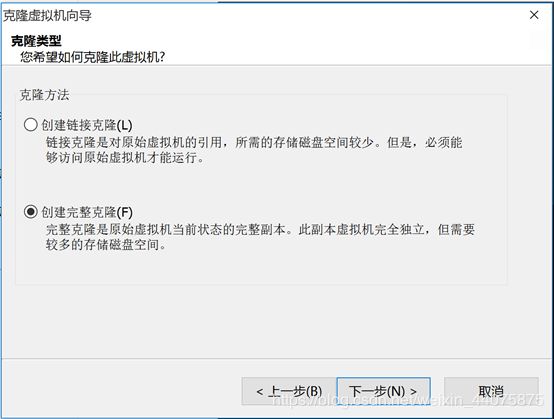
6.克隆虚拟机
先关闭被克隆虚拟机,【虚拟机(M)】→【管理(M)】→【克隆©】