一维卷积神经网络应用于电信号分类
维卷积神经网络,可以用来做一维的数据分析,以家用电器的识别分类作为背景。使用excel画出的简单的图形如下,横坐标为用电器开启后的秒数,纵坐标为某一秒的有功功率,由上至下分别为空调(Air Conditioner),冰箱(Refrigerator),烤炉(Stove):
!
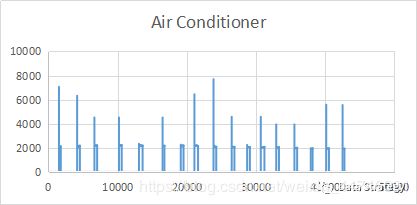
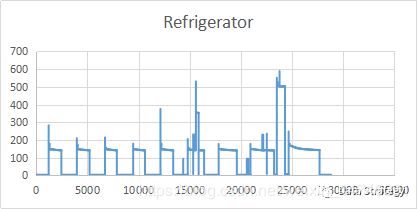
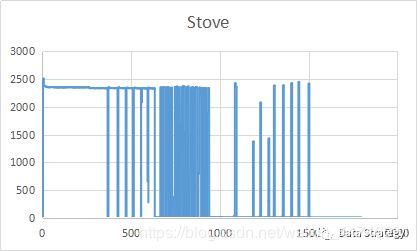
从上面三个图可以看出不同的用电器在工作时会以自己特有的方式工作。从而形成不同的特征峰及平台。接下来使用到的数据一共有9类用电器,包括上面这三种,但是我这边的训练集仅有每分钟一个数据的训练集,如果有朋友有大量的一秒一个数据的dataset,可以分享一下哈,感恩。
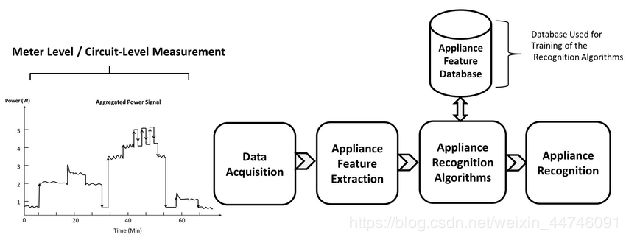
一维卷积神经网络应用于电信号的分类的大致逻辑如下图:
!
对比于其它维度的卷积神经网络,其卷积运算过程(ConV),池化过程(pooling)和全连接等可以理解为下图:
!
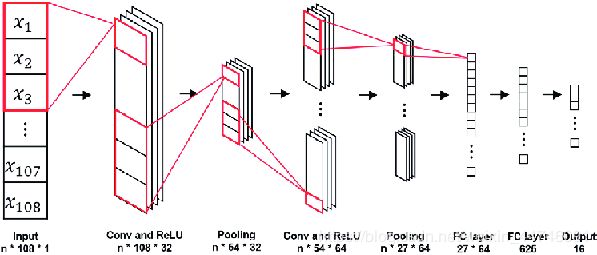
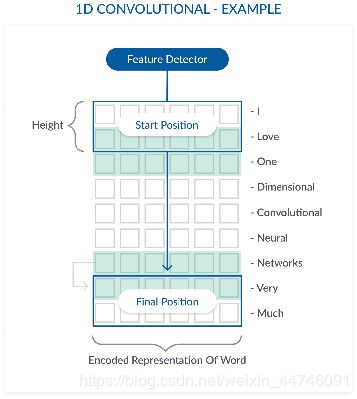
具体的一维卷积运算过程如下图,蓝色框框就是我们的卷积核,也就是特征提取的detector,箭头方向即为我们卷积核的移动方向,因为是一维的,所以它只有一个方向上移动,而不像多维那样,往复:
!
一、导入包和数据:
import os
import csv
import keras
import pandas as pd
import numpy as np
from sklearn.metrics import classification_report
from sklearn.preprocessing import LabelEncoder,StandardScaler
from sklearn.model_selection import StratifiedShuffleSplit
from keras.models import Sequential
from keras.layers import Dense, Activation, Flatten, Convolution1D, Dropout
from keras.optimizers import SGD
from keras.utils import np_utils
import time
from datetime import datetime
from sklearn.datasets import make_blobs #generate isotropic Gaussian blobs for clusteringpath=r'E:\ilm\train_data'
files=os.listdir(path)
column_names=[]
train=pd.DataFrame()
for item in files:
data_frame=pd.read_csv('E:/ilm/train_data/'+item)
data_frame['mins']=range(len(data_frame))
data_frame=data_frame.drop(['Unnamed: 0'],axis=1)
data_frame=pd.pivot_table(data_frame,columns=['mins'])
train=train.append(data_frame)
train=train.reset_index()
train=train.rename(columns={'index':'types'})!
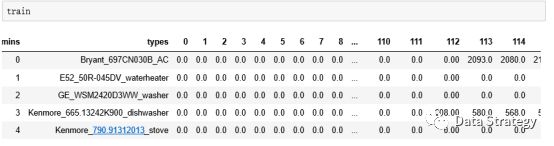
从上图可以看到我们的表格分为两部分,一部分是label标签部分,变量名为types。另一部分是数值 value 部分,所用到的训练集均为两个小时的测量数据,一分钟一个数据,那么就一共有120个数据,从0到119一共120个变量。
二、LabelEncoder打标签
把数据导入进来,并处理好了之后,开始给他们编码label encoder()
label_encoder = LabelEncoder().fit(train.types)
labels = label_encoder.transform(train.types)
classes = list(label_encoder.classes_)
train = train.drop(['types'], axis=1) LabelEncoder的用法
Encode target labels with value between 0 and n_classes-1。把标签贴上从0到n-1的数字, n为种类的数量。在这里为用电器的种类,在train的训练集里面,我们总共有9种用电器,所以这里label的code是0-8,一共9位。Labelencoder().fit(self,y) : fit label encoder, 将标签(types)和编码(code)一一对应起来。
transform(self,y): transform labels to normalized encoding. 把标签改成编码(code)。
其实上面fit和transform两部分可以用fit_transform function一步到位的。
三、零均值化和归一化
处理完label部分,接下来处理value部分。
scaler = StandardScaler().fit(train.values)
scaled_train = scaler.transform(train.values) Standardscaler的用法sklearn.preprocessing.StandardScaler(copy=True,with_mean=True,with_std = True)
Standardize features by removing mean and scaling to unit variance. 这个过程就是上上一个章节讲到的zero-centered(零均值化)和normalization(归一化)的过程,如下图:
!
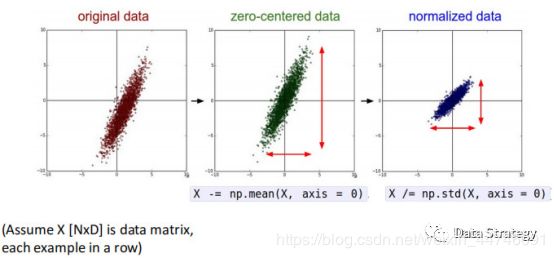
StandardScaler().fit(self,X[,y]): compute the mean and std to be used for later scaling. 计算均值及标准差用以备用。
Transform(self,X[,copy]): perform standardization by centering and scaling. 零均值化和归一化使之标准化。这里的fit和transform这两部分也可以只用一个function来解决,使用fit_transform(self,X[,y])就行了。
四、把数据集随机拆分成训练/测试集
接下来把所有的数据分成train和test两部分,train部分用来训练模型,test部分用来检验模型的精确度。
sss = StratifiedShuffleSplit(n_splits=10,test_size=16, random_state=0) #
for train_index, valid_index in sss.split(scaled_train, labels):
#print("Train: ",train_index,"Test: ",valid_index)
X_train, X_valid = scaled_train[train_index], scaled_train[valid_index]
y_train, y_valid = labels[train_index], labels[valid_index] StratifiedShuffleSplit的用法
sklearn.model_selection.StratifiedShuffleSplit(n_splits=10, test_size=None, train_size=None, random_state=None)
n_splits: Number of re-shuffling & splitting iterationstest_size(float, int, None, optional):如果是介于0到1之间的浮点型,那么这个值就是用来做测试的数据量占总的数据量的一个百分比;如果是一个整数,那么这个值就是测试样品的数量;如果没有设置参数,那么测试的将会是所有数据;如果test_size这个参数没有设置,与此同时train_size也没有设置,那么这个值就会自动设置为0.1。
train_size(float, int, or None, default is None): 顾名思义,其功能与test_size用法相似。
Random_state: If int, random_state is the seed used by the random number generator; if RandomState instance, random_state is the random number generator; if None, the random number generator is the RandomState instance used by np.random.
Random_state这个参数的设置与否决定了你产生的随机数的真假,当设置了这个参数时,产生的就是Pseudo-random number, 可以使你的结果重现,当没有设置这个参数时产生的就是真的随机数。下面我们把分别运行没有random_state这个参数两次和有这个参数两次,可以看到如下图的结果:
!
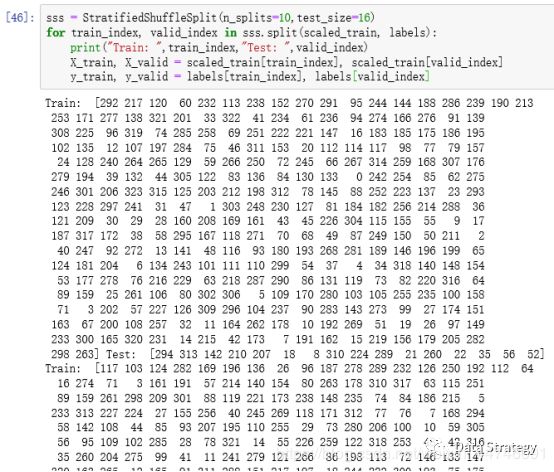
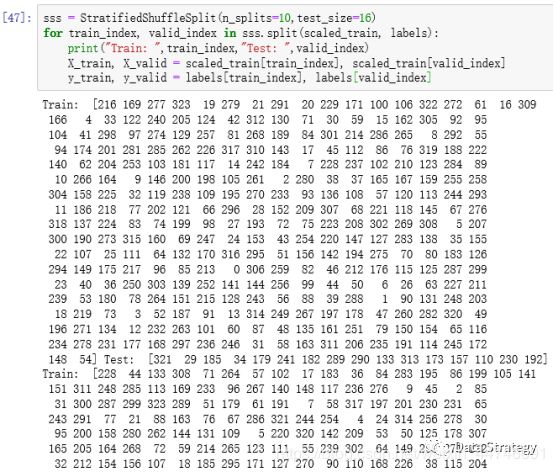
上面两图中,相同的代码,所产生的随机数完全不一样,为真的随机数,完全随机将训练集和测试集分开。下面两个图中是加了参数的,分别运行两次后,两次的随机数是完全一模一样的,即为假的随机,所以在两次split中的training data set 和test data set的index是一样的(train dataframe中的每一行对应一个index)。
!


上面就把train和test分好了,参数中设置的test_size=16,那么我们就用16个来test,其余的全部用来train, 通过print(train_index,valid_index) 列出来的index也可以看到我们用来test的data set里面有16组,这里我们一组就是一行,一行有一个label 和120个数据,y_train就是对应的用来train的那组数据的label,y_valid,就是用来test的那组数的label。
五、设置模型参数和reshape数据集
把训练/测试数据集分好后,接下来设置一些模型的参数和reshape数据集以符合模型需要:
nb_features = 120# number of features per features type (shape, texture, margin)
nb_class = len(classes) #nb_class=9 nb_features 每个特征类型的特征数,因为我这边是一维的,仅有一个功率的特征,长度都为120分钟,一分钟一个数据,一共两个小时,那么就是120个数据,所以这里我设置这个数值为120。对于有些多维的,如应用在图像识别里面,举个例子,给判别一片树叶的种类,树叶可以有不同的形状,纹理,边缘(锯齿),那么这就有三个特征,而每个特征如果用60个数值表示,那么这个number of features per features type就等于60。
而nb_class就是label的种类了,这边训练集中有9个种类,所以nb_class=9,或者直接读取之前Labelencoder时classes的长度。
为了符合keras中设定的维度,我们需要把我们的train data 进行reshape,所以这里我们先创建一个零矩阵,增加一个维度到3维(增加之前的train dataframe可以看作一个二维的数组,只有行和列),然后再用copy的方法,把数值复制进去。这里我们的电信号只有一个特征,所以第三个维度为1。如果是上面讲的树叶那个例子,因为判断树叶种类有三种特征(形状、纹理、边缘)那么第三个维度数值可以改为3,然后,X_train_r里面第三个维度的值就分别是0,1,2,每个所取得宽度都是60,因为每个特征有60个数值。在reshape validation data时跟reshape train data时情况是一样的。
# reshape train data
X_train_r = np.zeros((len(X_train), nb_features, 1))
X_train_r[:, :, 0] = X_train[:, :nb_features]
# reshape validation data
X_valid_r = np.zeros((len(X_valid), nb_features, 1))
X_valid_r[:, :, 0] = X_valid[:, :nb_features]接着需要把标签矩阵转换成binary矩阵。
y_train = np_utils.to_categorical(y_train, nb_class)
y_valid = np_utils.to_categorical(y_valid, nb_class) to_categorical的用法
to_categorical(y,num_classes=None,dtype=’float32’)
y: class vector to be converted into a matrix(integers from 0 to num_classes).
num_classes: total number of classes.
在这个分类模型中,因为之前编码的那0-8的数字,一共9位数,并没有代表着实际上的数学含义,而只是一个标签代表了该电信号所属的用电器种类,所以需要把该矩阵从class vector 转变为binary class 的matrix,最终输出的是一个 binary matrix。那么在这个例子中的具体情况就是一列变成了9列,里面的数值就是0或1,比如某一行属于这9个标签中的一个,那么对应的这行的矩阵在这个标签下的值就是1,其余值就是零,但是在其他的模型中有些情况是同时有多个标签的。个人觉得其实就是一个dummy variable,你觉得呢。如果只是二分类就不会有这么复杂了,如果不分类,那就是类似于数学中的线性拟合了。这个转变大致就是下图这样的过程。
!

数据和参数差不多已经设置完毕,下面开始建立模型了。
六、建立模型
# Keras model with one Convolution1D layer
# unfortunately more number of covnolutional layers, filters and filters length don't give better accuracy
model = Sequential()model.add(Convolution1D(nb_filter=4, filter_length=3, input_shape=(nb_features, 1)))
# nb_filter:Number of convolution kernels to use(dimensionality of the output)
# filter_length: The extension (spatial or temporal) of each filter.model.add(Activation('relu'))
model.add(Flatten()) #建立平坦层
model.add(Dropout(0.2)) #丢掉一些神经元和神经网络model.add(Dense(648, activation='relu')) #全连接层定义model.add(Dense(324, activation='relu')) #全连接层定义model.add(Dense(nb_class))
model.add(Activation('softmax')) Sequential API是建立keras models的方法之一,简单方便,可以一层层地建模,但是不能分享层或者有多元地输入或者输出。另外,functional API 可以允许你创建更灵活的模型,可以使层链接上一层或下一层,事实上也可以链接到任何一层,正因为如此,functional API 可以可以创建复杂的网络,例如siamese networks 和residual networks。Siamese networks 是一种孪生神经网络,可以衡量两个输入的相似程度,即可以有多个输入。这里就不再拓展了,有兴趣的可以自己看一下。
number of filter设置的数量越多,在model.fit的时候运算量就越大,但是运算量越大,不一定你的模型就越精确,比如我刚开始设置的值是512,后来还试过12和4,发现12和4他们测试的准确性都差不多,所以就没有必要设到512,具体还是需要多测试一些参数,然后找到合适的。
sgd = SGD(lr=0.01, nesterov=True, decay=1e-6, momentum=0.9)
model.compile(loss='categorical_crossentropy',optimizer=sgd,metrics=['accuracy'])nb_epoch = 50
model.fit(X_train_r, y_train, nb_epoch=nb_epoch, validation_data=(X_valid_r, y_valid))# 我把, batch_size=32删掉了
# 往返(顺逆)一次一个epoch,每次都做一个split,分成两部分,一部分用来training(training data),
# 另一部分用来评估(validation data),
# it trains the model on training data and validate the model on validation data by checking its loss and accuracy. sgd = SGD(lr=0.01, nesterov=True, decay=1e-6, momentum=0.9)
设置SGD(Stochastic gradient descent optimizer,随机梯度下降)的参数:
Lr: learning rate, float>=0.
学习速率控制模型对于预测值和实际值的差值的调整速度,过小会导致长时间的训练,小的学习速率learning rate需要更多的训练次数(training epoch), 大的学习速率因为更快的调整改变速度,所需要的training epoch就会更少,那么对应设置的epoch参数也会更小;学习速率太快会引起模型过快收敛,过小则会造成stuck。
Nesterov: boolean, whether to apply nesterov momentum.
Momentum: float>=0. Parameter that accelerates SGD in the relevant direction and dampens oscillations. 在某些方向上加速梯度下降,并且对震动产生阻尼。
Momentum 和 Nesterov Momenturm 可以加速训练并且提升收敛度,同时momentum 还可以避免跌入到局部最小。decay: decay rate which is greater than zero and iteration is the current update number. 这个decay是应用在learning rate这个参数上的,就是将学习速率衰减,因为在最开始的时候我们需要较高的学习速率,而在接近global minimum(or maximum)的时候需要的学习速率较小,所以就存在一个learning rate变化的过程,那么调节这个变化的参数我们用decay(衰减系数)来设置,learning rate decay也有很多种方式,比如分段常数衰减,反时限衰减和多项式衰减等。
与SGD相关的数学问题,可以参阅下面的链接:
https://dominikschmidt.xyz/nesterov-momentum/
compile(optimizer, loss=None, metrics=None, loss_weights=None, sample_weight_mode=None, weighted_metrics=None, target_tensors=None)
compile: configures the model for training.
optimizer: 最小化和最大化目标函数,中文有人叫优化器。loss: loss function. 损失函数。
这篇文章举的例子是一个多分类问题,所以用categorical_crossentropy, binary_crossentropy 为二分类交叉熵损失,softmax 使用的即为交叉熵损失函数。
nb_epoch: number of epoch,一个来回叫一个epoch,这里把模型训练50次的意思,训练过多会出现过拟合,过少可能欠拟合。不过也可以用early stopping 来防止过拟合,callbacks 中的 EarlyStopping 是在每一个epoch结束时,计算validation data的accuracy, 当accuracy 不再提高时就停止训练。
Model.fit(x=None,y=None,batch_size=None,epochs=1,callbacks=None,validation_data=None…)Model.fit() 就是拟合过程,其他参数上面已经解释过了,那么我们来看看batch_size。
Batch_size: number of samples per gradient update. 自定义的是32,如果你用的是symbolic tensors, generators 或者 sequence instance,那么就不需要设置这个bathes_size 参数,因为他们会自己产生,所以我这里没有设置batch_size的值。
七、做分类预测下面用训练好的模型做一个预测:
#predict
compare_data=pd.read_csv(r'E:\nilm_mini_bs\nilm_mini_bs\data\separate_2020-04-14 16-30-17.csv')
compare_data['mins']=range(len(compare_data))
test=pd.pivot_table(compare_data,columns=['mins'])
test_r = np.zeros((len(test), 120, 1))
test_r[:, :, 0] = test.values[:, :120]
# there are two types of classification predictions: class predictions and probability predictions.
test_y=model.predict_classes(test_r)
test_y_prob=model.predict_proba(test_r) predict_classes(self, x, batch_size=32, verbose=1)对输入的数据进行分类判断。得到的test_y结果如下。
!

predict_proba(self,X) 返回的是一个类似于刚刚binary matrix的矩阵。
!
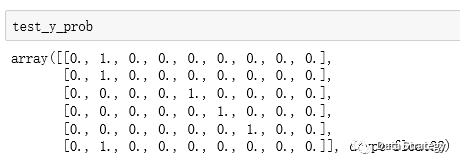
因为之前测试的时候也是一组只有一个标签,那么在这个标签下的概率是完整的1,如果它同时有多个标签,那么就会有多个标签分别对应的一个概率,那么得到的矩阵也就不是非0即1了,如果是多个标签那种情况的话,那还需要在整行中寻找概率最大的那个值对应的标签。也可以用下面这种方式来处理:
label_encoder.inverse_transform(test_y) inverse_transform(self,y) Transform labels back to original encoding. 将encoded之后的数值转化为原来的类型名字。然后把test_y的预测分类结果所对应的types找出来了。
!

!
后台回复“一维卷积神经网络应用于电信号分类”(建议复制)即可以获得训练数据集的压缩包了。
