面向对象设计Twitter
开篇
大家不要太兴奋,这篇文章只是解决Leetcode上的335题design Twitter,并不是从前端、后端、数据库等各种繁琐的层次来设计Twitter,能力不够而且工程量确实很大,所以我们今天就简单说一下这道题目和类似Twitter这种社交平台的基本算法。
设计Twitter
首先我们先列举以下我们需要实现的几个API:
class Twitter
{
//user发表一套tweet动态
void postTweet(int userId,int tweetId){}
//返回该user关注的人(包括他自己)最近的动态id
//最多10条,而且这些动态必须按从新到旧的时间线顺序排序
vector<int>getNewsFeed(int userId){}
//follewer关注follwee,如果Id不存在则新建
void follow(int followerId,int followeeId){}
//follewer取关followee,如果Id不存在则什么都不做
void unfollowed(int followerId,int followeeId){}
};举个例子,方便大家理解API的具体用法:
Twitter twitter = new Twitter();
twitter.postTweet(1,5);//用户1发送了一条推文5
twitter.getNewsFeed(1);//return 5,因为是自己关注自己
twiitter.follow(1,2);//用户1关注了用户2
twitter.postTweet(2,6);//用户2发送了一个新推文(id=6)
twitter.getNewsFeed(1);//return [6,5]
//因为用户1关注了自己和用户2,所以返回他们的最近推文
//而且6必须在5之前,因为6是最近发送的
twitter.unfollow(1,2);//用户1取消关注了用户2
twitter.getNewsFeed(1);//return [5]这个场景我们在现实生活中也见过,无论你在微博还是朋友圈,如果你关注了他,或者你没有屏蔽他,那么他发的微博或者朋友圈就是被你看到,除非他把你屏蔽了…
通过上面的距离我们可以看到,这几个API中最核心的功能应该是getsNewFeed,其他的几乎放到一种数据结构中,然后依次遍历输出即可。但是getNewsFeed这个API不同,每个人的关注列表都是动态变化的,而且需要在时间上有序,怎么办呢?
这里就涉及到了算法:如果我们把每个用户各自的推文存储在链表里,每个链表节点存储文章id和一个时间戳time(记录发帖时间以便方便比较),而且这个链表是按照time有序的,那么如果某个用户关注了k个用户,我们就可以用合并k个有序链表的算法合并出有序的推文列表,正确地getNewsFeed了。
这是一个典型的面向对象设计的题目,我们一点点开始造轮子。
面向对象的Twitter设计
首先我们需要一个User类,储存user信息,还需要一个Tweet类,储存推文信息,并且要作为链表的结点。所以我们先搭建一下整体的框架:
#include 之所以要把Tweet和User类放到Twitter类里面,是因为Tweet类必须要用到一个全局时间戳timestamp,而User类又需要用到Tweet类记录用户发送的推文,所以它们都作为内部类。
Tweet类的实现
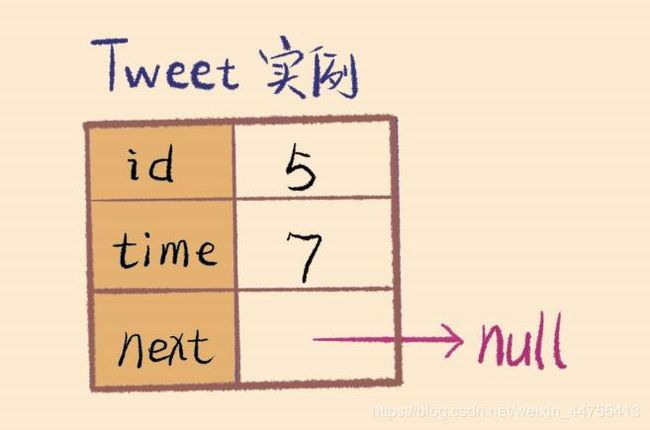
Tweet类很容易实现:每个Tweet实例需要记录自己的tweetId和发表时间time,而且作为链表结点,要有一个指向下一个节点的next指针
class Tweet
{
private:
int id;
int time;
Tweet next;
public:
Tweet(int id,int time)
{
this.id = id;
this.time = time;
this.next = NULL;
}
};
User类的实现
我们根据实际场景想一想,一个用户需要存储的信息有userId,关注列表以及该用户发过的推文列表。其中关注列表应该用集合(Hash set)这种数据结构来存,因为不能重复,而且需要快速查找;推文列表应该由链表这种数据结构存储,以便于进行有序合并的操作。
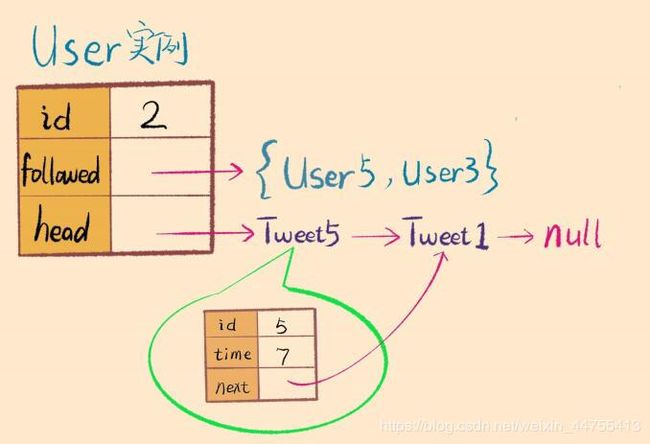 除此之外,根据面向对象的设计原则,关注、取关和发文应该是User的行为,况且关注列表和推文列表也存储在User类中,所以我们也应该给User类添加follow和unfollow以及post的方法:
除此之外,根据面向对象的设计原则,关注、取关和发文应该是User的行为,况且关注列表和推文列表也存储在User类中,所以我们也应该给User类添加follow和unfollow以及post的方法:
class User
{
private:
int id;
public:
//关注列表
set<int>followed;
//用户发表的推文链表头节点
Tweet head;
User(int userId)
{
set<int>followed;
this.id = userId;
this.head = NULL;
//关注一下自己
follow(id);
}
void follow(int userId)
{
followed.add(userId);
}
void unfollow(int userId)
{
//不可以取关自己
if(userId!=this.id)
followed.remove(userId);
}
void post(int tweetId)
{
Tweet twt = new Tweet(tweetId,timestamp);
timestamp++;
//将新建的推文插入链表头
//越靠前的推文time值越大
twt.next = head;
head = twt;
}
};OK啦,所有的类和API我们都已经声明好了,下面就是配合功能去设计算法了,实现Twitter类的所有API。我们重点来看getNewsFeed这个API。
大家一定还记得优先队列这种数据结构,我们可以随意插入合法的数据,在队列中这些数据会按照某种顺序自动排序,可能是从小到大也可能是从大到小(取决于底层是大顶堆还是小顶堆)。我们就可以利用这个数据结构来实现我们的核心API——getNewsFeed。注意我们把优先队列设为按照time属性从大到小降序排列,因为time越大意味着时间越近,应该排在前面。下面附上完整代码:
#include 总结
本文运用简单的面向对象的技巧和合并k个有序链表的算法设计了一套简化的时间线功能,这个功能其实广泛地运用在许多社交应用中。
我们先合理地设计出 User 和 Tweet 两个类,然后基于这个设计之上运⽤算 法解决了最重要的⼀个功能。可⻅实际应⽤中的算法并不是孤⽴存在的,需 要和其他知识混合运⽤,才能发挥实际价值。
当然,实际应⽤中的社交 App 数据量是巨⼤的,考虑到数据库的读写性 能,我们的设计可能承受不住流量压⼒,还是有些太简化了。⽽且实际的应 ⽤都是⼀个极其庞⼤的⼯程,⽐如下图,是 Twitter 这样的社交⽹站⼤致的系统结构:
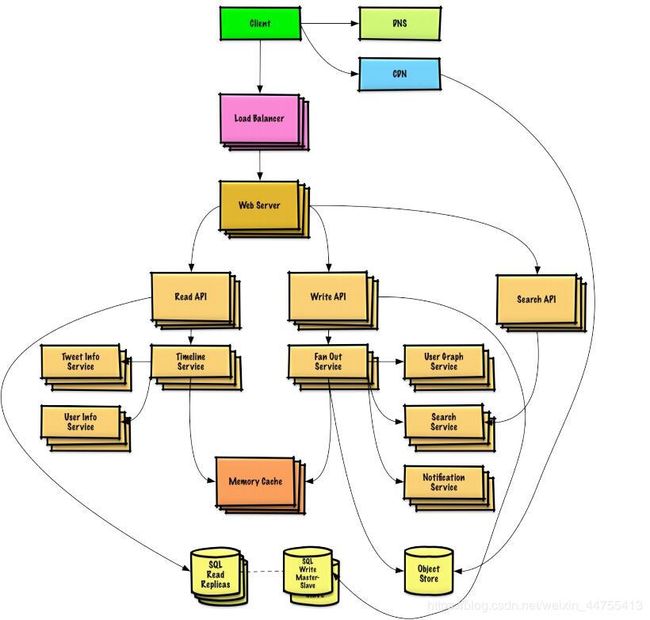
我们解决的问题应该只能算是TimelIne Service模块的一小部分,功能越多,系统的复杂性可能是指数级增长的,所以合理的顶层设计十分重要,其作用是远超一个算法的。