初窥数据分析之51job网职位分析项目
前言:和以往大家爬取数据分析职位不同,我这项目爬取的是软件测试的职位(我对象想去做软件测试这块,所以,咳咳),不过不影响大家学习,对scrapy的代码简单修改一下主要链接就可以爬取其他职位的数据了。
爬数据要好久,我爬取了近一万条数据三四个小时吧,看完之后若是有对我这代码感兴趣,想练手学习数据分析的同学,可以留言 “源码” ,我发源码和数据给大家,供大家学习。
目录
- 一、项目简单介绍
- (一)数据收集
- (二)数据清洗
- (三)数据分析可视化
- 二、可视化结果
- (一)工资概观
- (二)各个城市的工资水准
- (三)招聘的公司类型及规模占比
- (四)平均工资与公司类型的关系
- (五)平均工资与公司规模的关系
- (六)招聘要求的学历占比,及学历与工资的关系
- (七)招聘要求的工作经验占比,及工作经验与工资的关系
- (八)招聘公司所在城市(工作城市)的地图
- (九)工作职责/需求词云图
一、项目简单介绍
目标网页:51job职位
对目标网页的软件测试职位进行爬取分析。
使用到的主要技术:
- scrapy(数据收集)
- pandas(数据清洗分析)
- pyecharts(数据可视化)
(一)数据收集
使用scrapy爬虫对51job网职位,如下详情页里的信息进行了爬取(有点儿出路,不过信息的位置是一样的)。

Item代码
import scrapy
class Job51Item(scrapy.Item):
job_name = scrapy.Field() # 工作名称
job_area = scrapy.Field() # 工作区域
experience_requirements = scrapy.Field() # 经验要求
education = scrapy.Field() # 学历
total_recruitment = scrapy.Field() # 招人总数
release_date = scrapy.Field() # 发布日期
salary = scrapy.Field() # 薪资
welfare = scrapy.Field() # 福利
work_requirements = scrapy.Field() # 工作要求
company_name = scrapy.Field() # 公司名
company_url = scrapy.Field() # 公司url
company_type = scrapy.Field() # 公司性质
company_size = scrapy.Field() # 公司规模
company_field = scrapy.Field() # 公司领域
spider代码
# -*- coding: utf-8 -*-
import scrapy
from job51.items import Job51Item
class JobtestSpider(scrapy.Spider):
name = 'JobTest'
# allowed_domains = ['search.51job.com']
##################
#
#
# 要爬取别的职位的就改这个start_urls就好
#
#
##################
start_urls = ['https://search.51job.com/list/000000,000000,0000,00,9,99,' \
'%25E8%25BD%25AF%25E4%25BB%25B6%25E6%25B5%258B%25E8%25AF%2595,2,' \
'{}.html'.format(i) for i in range(1, 301)
]
def info_parse(self, response):
print(response.url)
Item = Job51Item()
try:
Item['job_name'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/h1/@title').extract_first()
data = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/p[2]/@title').extract_first().split('|')
Item['job_area'] = data[0]
Item['experience_requirements'] = data[1]
Item['education'] = data[2]
Item['total_recruitment'] = data[3]
Item['release_date'] = data[4]
Item['salary'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/strong/text()').extract_first()
Item['welfare'] = response.xpath('/html/body/div[3]/div[2]/div[2]/div/div[1]/div/div/span/text()').extract()
work_req = response.xpath('/html/body/div[3]/div[2]/div[3]/div[1]/div')
Item['work_requirements'] = work_req[0].xpath('string(.)').extract()[0]
Item['company_name'] = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[1]/a/p/@title').extract_first()
Item['company_url'] = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[1]/a/@href').extract_first()
Item['company_type'] = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[1]/@title').extract_first()
Item['company_size'] = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[2]/@title').extract_first()
Item['company_field'] = response.xpath('/html/body/div[3]/div[2]/div[4]/div[1]/div[2]/p[3]/@title').extract()
yield Item
except:
pass
def parse(self, response):
link_url = response.xpath('//*[@id="resultList"]/div[@class="el"]/p/span/a/@href').extract()
for url in link_url:
yield scrapy.Request(url=url, callback=self.info_parse)
直接使用scrapy自带的管道对数据存储为csv文件,在终端输入以下指令即可。
scrapy crawl JobTest -o job.csv
(二)数据清洗
用padnas对数据进行清洗处理,我这里直接放截图了,见谅。
1、空值的处理
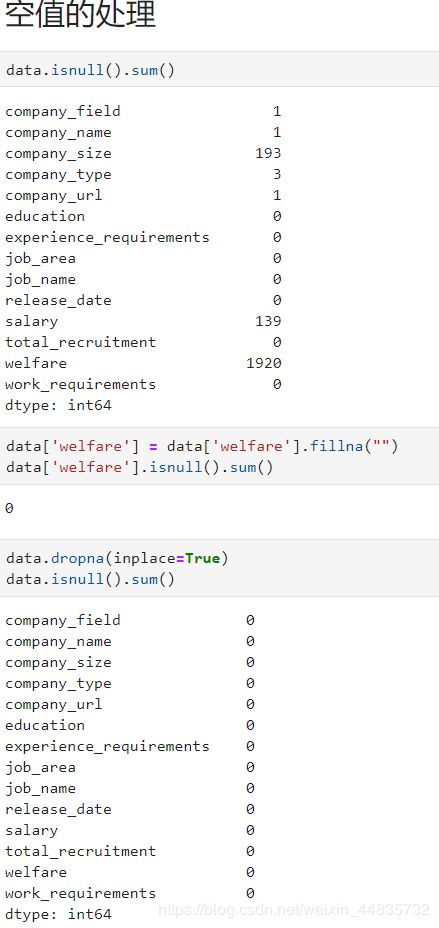
2、很多公司地址都是这样的,我就取他前面的那部分。


3、工资单位的处理
工资的单位真是五花八门,统一处理成(千/月)

4、其他处理
在最后观察整体数据时,发现有少量数据的位置是错的,比如在学历这栏出现了“招几人”的信息。
判断是如下栏的数据,在HR发布的时候少写了什么,导致了错位,我们直接删除这一行数据。


(三)数据分析可视化
利用pycharts对清洗完的数据进行可视化,该部分没啥代码好讲,主要是对【pycharts官方文档】的学习理解。直接看下一部分:可视化结果。
二、可视化结果
对数据的收集处理都是过程,最后这可视化结果才是给人决策的,这些图表对我们未来的一些行为有所帮助,我们对某一方面也加深了理解,使得我们行为决策的正确性更高。
重提一下,这是对软件测试职位的分析。下面我对每个图都啰嗦一下,眼界浅薄,不喜勿喷,可视化的图仅供参考,
(一)工资概观

对最高、最低、平均工资都做了个盒须图。看平均工资的,它的上下限差距还是蛮大的,最高近九千,最低两千五,好的好坏的坏。拿正常点说,就它的平均值有七千五说,我这也没上班也不能说它很高或很低或什么的,听朋友说七千五在整体看来不能算低,it行业里一般水准。
(二)各个城市的工资水准
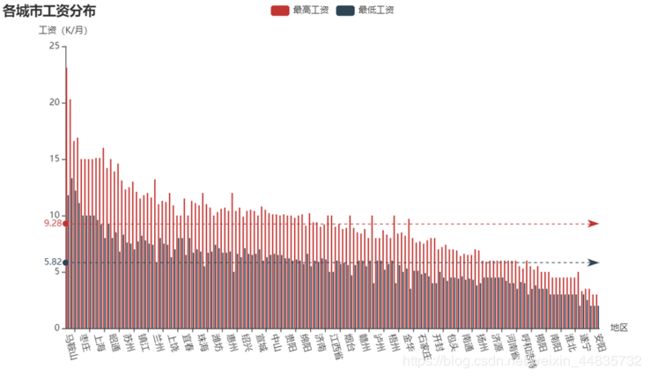
这是对每个城市的工资做了个比较,按平均值从大到小排序,然后做了最高工资和最低工资的平均线,做这个图意思是想可以更好的选择以后工作发展的城市。
对上图的补充
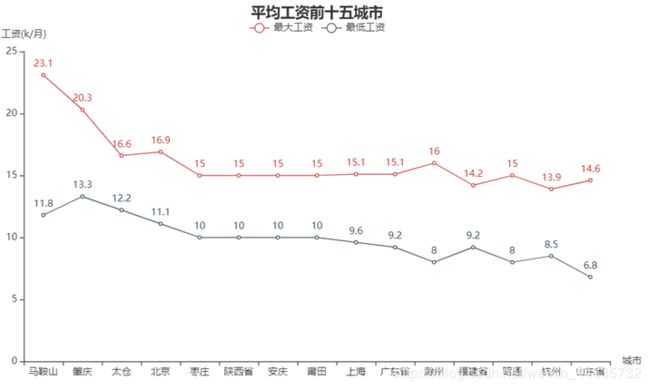
(三)招聘的公司类型及规模占比
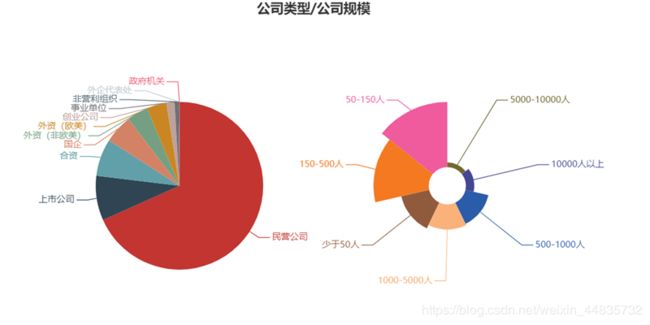
招聘的公司可以看出是以50-150人规模的民营公司为主,中小公司多些。
(四)平均工资与公司类型的关系
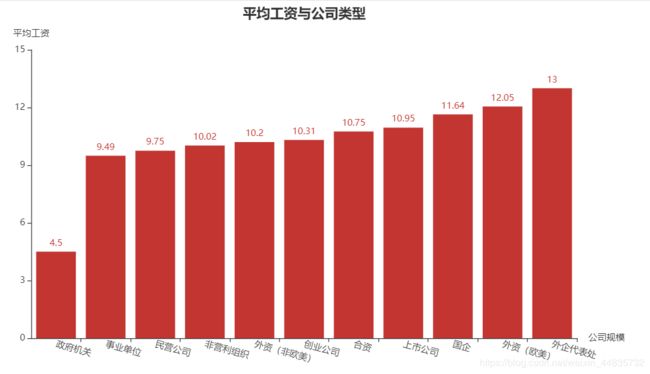
这里外企、外资这工资给的要高一些,然而这个政府机关,不知道为啥工资实在是低了些,连倒数第二的事业单位的一半都没有,不过想来是铁饭碗,待遇好些。
(五)平均工资与公司规模的关系

不用看图,经验来想也应该清楚,公司越大工资越高,然怪人人都想去大厂工作。
(六)招聘要求的学历占比,及学历与工资的关系

对本科生的需求量最大,平均工资也排在一个中间的位置,工资最高的是博士,好待这么高学历,不过对博士的需求比较少。
(七)招聘要求的工作经验占比,及工作经验与工资的关系

按经验来想,工作经验越多,工资越高,对三到四年工作经验的需求最大了,这个时候的程序员不算小白也不算大神专家,对于公司而言可能最为划算了吧,所以需求量特别大。
(八)招聘公司所在城市(工作城市)的地图
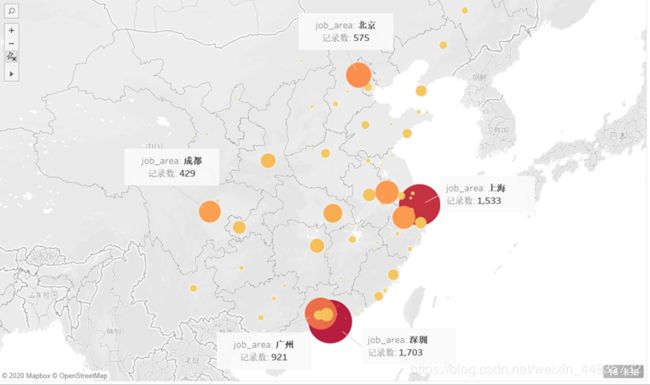
这是公司所在城市的地图,我用pyecharts无法显示城市的地图(其他的可以),这图我用tableau做的,使用BI工具确实方便好多好多。公司最多的是上海,其次是深圳、广州,对于软件测试的朋友可以结合之前的“各个城市的工资水准”去这些地方找工作,不过这里标出的城市都是大城市,工资也不会低的,关键是要找到好公司了。
(九)工作职责/需求词云图

啊哈,有没有对词云形状眼熟的,这是哪吒的,哈哈哈。这里有个槽点,我爬取的时候没对工作职责和需求进行分开爬取,导致这里有点混乱,添加自定义的停用词表好费事。为啥软件测试的最多的是沟通能力,测试会和开发干架吗,所以要多沟通,我想分析开发职位它也是多沟通,都要多沟通呀,多交流学习。
好啦,到此告一段落,大家能给刚入门数据分析的我点个赞支持一下嘛,(我想点赞转发收藏,三连,哈哈哈哈,大家开心就好)。
最后祝大家,学习无烦恼,代码无bug,测试一遍过,头顶不掉发。
