【基于深度学习的脑电图识别】综述篇(三)模型分析:Deep learning-based electroencephalography analysis: a systematic review
Deep learning-based electroencephalography analysis: a systematic review
- 架构分类:
- 统计数据:
- EGG 特异性设计:
- 训练模型:
- 训练过程:
- 正则化:
- 优化器:
- 超参数搜索:
- 检验模型:
- 报告结果:
- 参考基准:
- 性能指标:
- 验证过程:
- 主体处理:
- 统计测试:
- 对比结果:
- 可复现性:
这一部分主要回答以下几个问题:
- 最常用的架构是什么?
- 这些年来发生了什么变化?
- 架构的选择是否与输入特性有关?
- 在DL-EEG中使用的网络有多深?
架构分类:
本文主要将架构分为以下几类:
- CNNs:Convolutional Neural Networks,卷积神经网络;
- RNNs:Recurrent Neural Networks,循环神经网络;
- AEs:autoencoder,自编码器;
- RBMs:Restricted Boltzmann Machines ,玻尔兹曼机;
- DBNs:Deep Belief Networks,深度信念网络;
- GANs:Generative Adversarial Nets,生成对抗网络;
- FCs:Fully Connected Networks,全连接网络;
- CNN+RNN:卷积循环网络;
- Others:其他方法;
统计数据:
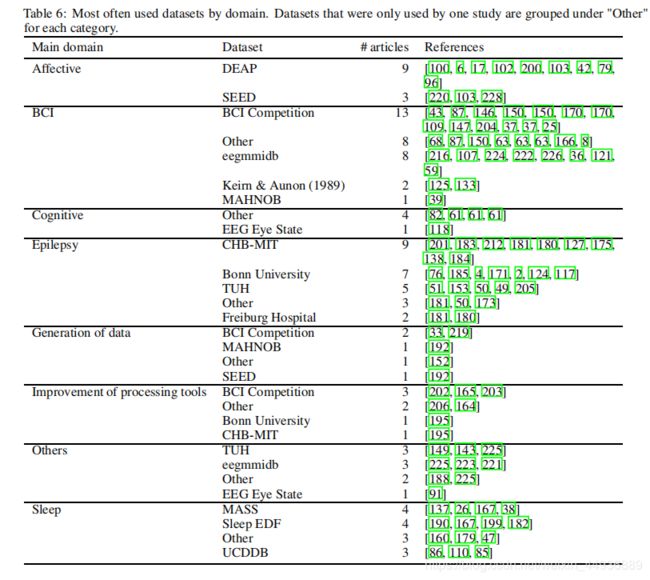
架构占比:
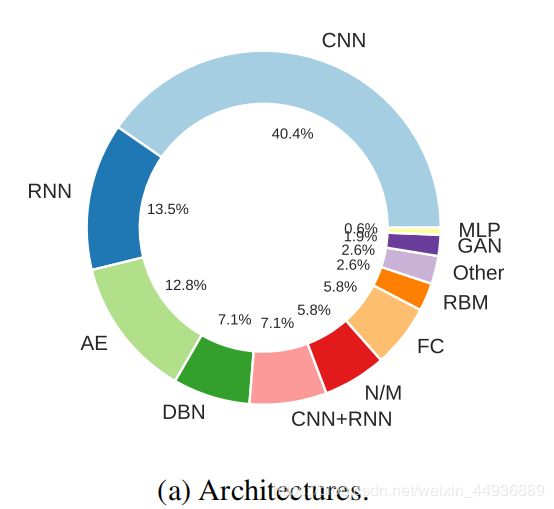
年份分布:
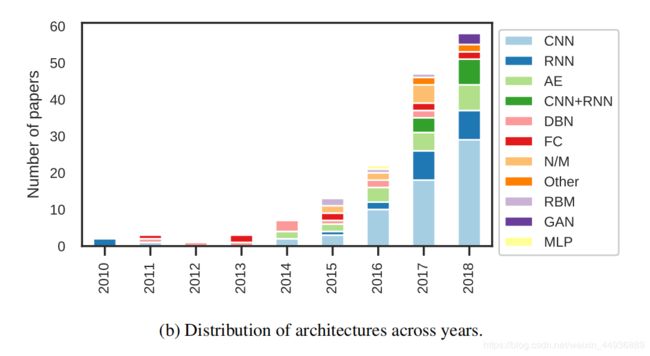
输入数据分布:
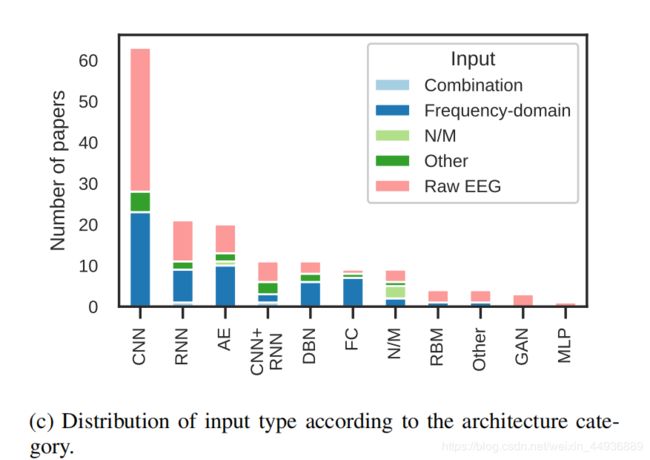
层数分布:
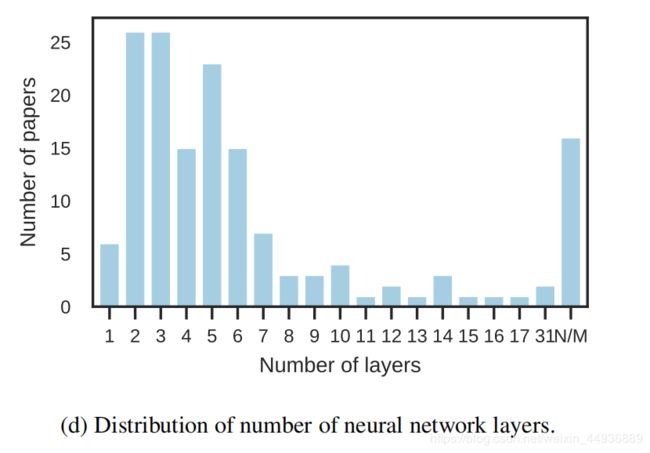
作者发现,较浅的网络往往有较好的性能;
EGG 特异性设计:
特定的架构选择可能使模型能够模拟提取脑电图特征的过程,还可以专门设计一个体系结构,将特定的属性强加于所学习的表示;
以脑电图信号为例,在网络的早期阶段,人们可能会对迫使模型分别处理时间和空间信息感兴趣;
在一些研究中,一 维卷积被用于在层次结构的这一点上独立地处理时间或空间信息;
其他研究将递归神经网络和卷积神经网络相结合,作为分离时空内容的替代方法;
在需要从脑电图数据中获取长期依赖关系的情况下,也应用了递归模型;
训练模型:
由于不同的方法和超参数的选择对神经网络的性能有很大的影响,因此对文献中提出的模型的训练细节非常重要;
使用预训练的模型、正则化和超参数搜索策略是本文关注的重点;
训练过程:
将深度神经网络应用于脑电图处理的优点之一,是可以同时训练特征提取器和执行下游任务(如分类或回归)的模型;
然而,在一些综述的研究中,这两个任务是分开执行的:
- 使用 RBMs、DBNs 或 AEs 以无监督的方式进行特征学习;
- 在训练这些模型以提供适当的脑电图输入信号后,将这些新特征作为目标任务的输入,即通常的分类;
在其他情况下,预训练的模型用于针对特定的脑电图任务进行微调,目的是提供更好的初始化或正则化效果;
统计如下:

正则化:
本文 将正则化定义为神经网络函数集上的任何约束,目的是提高鲁棒性;
神经网络正则化的主要目标是控制其复杂度,以获得更好的泛化性能,这可以通过减少分类问题时的测试误差;
神经网络的正则化方法有多种,其中最常见的有权值衰减(L2和L1正则化)、提前停止(Early Stopping)、dropout 和 标签平滑(label smoothing);
统计数据如下:

优化器:
47% 的研究没有报告应用的优化器,30%使用Adam,17%使用随机梯度下降(注意小批量情况也视为SGD),6%的论文使用了不同的优化器,如 RMSprop,Adagrad,Adadelta;
一个有趣发现是Adam的使用稳步增加,从2017年到2018年,使用 Adam 的研究比例从 31.9% 上升到 52.6%;
统计数据如下:

超参数搜索:
从实用的角度来看,调整学习算法的超参数通常会占用训练期间的大量时间;
常用的方法有网格搜索和贝叶斯优化:
- 网格搜索包括确定要调优的每个参数的值范围,选择这个范围内的值,并对模型进行评估,通常在考虑所有组合的验证集中进行评估;网格搜索的优点之一是它的高度并行性,因为每组超参数是相互独立的。
- 贝叶斯优化则定义了超参数空间上的后验分布,并根据与期望后验对应的超参数集模型所获得的性能迭代更新其值;
统计结果表明近80%的文献未提及超参数搜索策略的使用,需要强调的是,在这些文章中,尚不清楚有多少文章根本没有进行任何调优,有多少文章只是没有考虑在本文中包含这些信息;
21% 的文献手动做了一些寻找合适超参数的试验,而另一些人则采用网格搜索和一些其他策略,如贝叶斯方法;
检验模型:
在选定的研究中,27%报告了对他们的模型的检查,有两项研究更侧重于 DL 和 EEG 背景下的模型检查问题;
下表列出了多个研究检查模型时使用的不同技术:
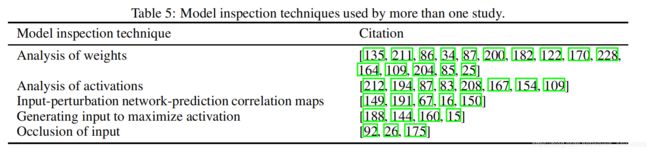
最常见的模型检验技术包括对训练过的模型的权重进行分析,这通常要求只关注第一层的权重,因为它们对输入数据的解释很简单;
-
权重的绝对值代表模型使用相应输入维度的强度——因此,较高的值可以解释为特征重要性的粗略度量,然而,对于更深的层次,神经网络的层次性意味着很难理解什么是权重;
-
模型激活的分析被用于多个研究,这种检查方法通常包括通过多个示例可视化训练模型的激活,从而推断网络的不同部分如何对已知输入做出反应;
在[149]中引入的输入-扰动网络-预测相关图(input- ation network-prediction correlation map)技术通过试图确定输入和模型决策之间的因果关系,进一步推动了这一思想;
为此,首先在时域或频域对输入进行扰动,改变其振幅或相位特性,然后输入到网络中;
-
遮挡敏感性技术使用了类似的思想,通过这种思想,可以分析当输入的不同部分被遮挡时网络的决策;
-
一些研究使用基于反向传播的技术来生成最大限度激活特定单元的输入映射,这些映射可以用来推断特定神经元的作用,或它们的输入类型都很敏感;
-
其他的技术包括 Deeplift, saliency maps, 输入-特性单元-输出相关映射(input- ation network-prediction correlation map),retrieval of closest examples,分析转换层的性能(analysis of performance with transferred layers),分析最活跃的输入窗口(analysis of most-activating input windows),分析生成的输出(analysis of generated outputs),去除滤波器(ablation of fifilters);
报告结果:
在这篇综述中要回答的一个主要问题是:“在EEG上,DL 是否比传统方法有更好的表现?”
然而,回答这个问题并不简单,因为基准数据集、基线模型、性能指标和报告方法在不同的研究中都有很大的不同;
相反,DL 的其他应用领域,如计算机视觉和NLP,则受益于标准化的数据集和评估标准;
因此,为了提供尽可能令人满意的答案,本文采取了双管齐下的方法:
- 首先回顾了这些研究是如何通过可直接量化的项目来报告结果的,包括
1)在每个研究中用作比较的基线类型
2)性能指标
3)验证过程
4)统计测试的使用 - 其次,基于这些观点,本文集中研究报告的准确性与基线模型的比较,并分析了大多数审查研究的报告性能。;
参考基准:
在典型的脑电图分类任务中,最先进的方法通常涉及传统的处理系统,包括特征提取和浅层/经典的机器学习模型;
考虑到这一点,67.9% 的研究选择了至少一个传统处理系统作为基线模型;
另外一些研究将它们的性能与基于 DL 的方法进行比较,以强调通过使用不同的体系结构或培训方法获得的增量改进:34.0%的研究因此将至少一个基于 DL 的模型作为基线模型;
而 21.1%的研究没有报告基线比较,这使得不可能评估他们提出的方法在性能方面的附加价值;
统计数据如下:

性能指标:
针对EEG分类的研究采用的性能指标类型如图所示:
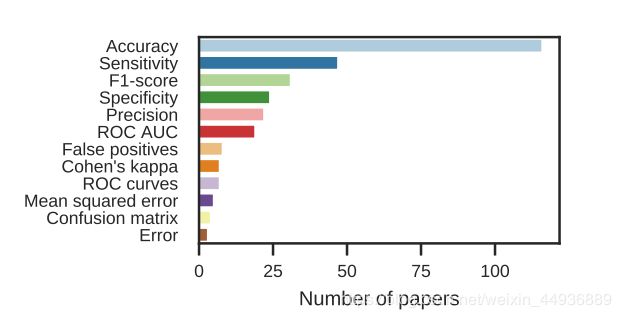
大多数研究使用来自混淆矩阵的指标,如准确性、敏感性、f1-score、ROC AUC和精度;
实际上,这些研究通常使用分类任务来评估模型性能,尽管它们的主要目的不同;
在其他情况下,使用特定于研究目的的性能指标,如生成数据,例如,the inception score、the Fréchet inception distance,以及自定义指标;
验证过程:
在评估一个机器学习模型时,度量它的泛化性能是很重要的;
通常的做法是将可用的数据分成一个训练集和一个测试集,而当超参数需要调优时,测试集上的性能不能再作为对模型泛化性能的无偏评估,因此,对训练集进行划分,得到第三个集,称为“验证集”,用来选择最佳的超参数配置,让测试集以无偏的方式评估最佳模型的性能;
然而,当可用的数据量很小时,将数据划分为不同的集合并仅使用子集进行训练会严重破坏数据密集型模型的性能,在这些情况下使用一种称为“交叉验证”的过程,其中数据被分解成不同的分区,然后这些分区将依次用作培训数据或验证数据;
所选研究中使用的交叉验证技术如图所示:
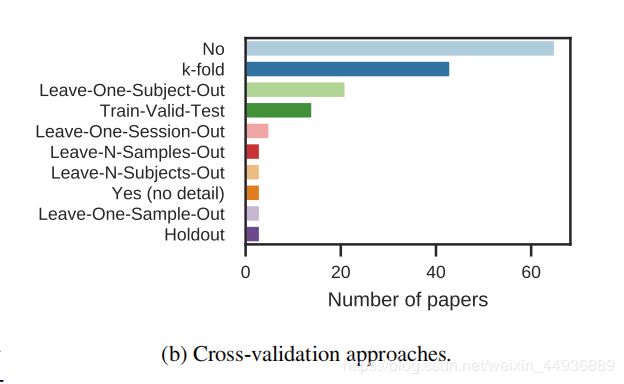
60%的研究没有使用任何形式的交叉验证;
在一项研究中中,作者建议在梯度下降步骤中进行 “ 热重启(warm restart)”,以消除对验证集的需要;
主体处理:
由于模型需要考虑的数据可变性较小,因此对单个受试者的数据进行训练和使用的受试者内部模型通常会带来更高的性能;
然而,这意味着模型所训练的数据来自于一个单一的对象,因此通常只包含少量的记录;
Leave-N-Subject-Out 过程使用不同的受试者进行训练和测试,可能会导致较低的性能,但适用于现实场景,其中模型必须用于没有培训数据的受试者;
相反,对来自所有受试者的组合数据使用 k-fold 交叉验证通常意味着在训练集和测试集中都可以看到相同的受试者;
在入选的研究中,25% 的研究只关注主体内分类(即同一个人),61%的研究只关注主体间分类,8.3% 的研究同时关注两者,4%的研究未提及;
统计如下:
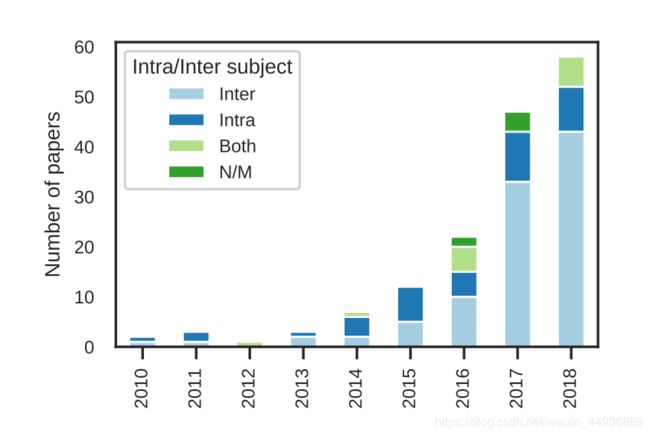 结果如下:
结果如下:
-
在[184]中,作者比较了他们的模型在主体内和主体间的任务,尽管前者提供的训练数据比后者少,但结果却更好;
-
在[62]中,作者比较了不同的 DL 模型,发现交叉主体(37个)模型的表现总是比主体内模型差;
-
在[127]中,针对多个主体进行训练,然后对特定主体的数据进行微调的混合系统获得了最佳性能;
-
在[175]中,作者将深度神经网络与最先进的传统方法进行了比较,结果表明深度神经网络的泛化效果更好,尽管深度神经网络在主体内分类方面的表现仍然高于主体间分类;
统计测试:
19.9% 的研究使用了统计测试来比较他们的模型与基线模型的性能,其中最常使用的测试是Wilcoxon符号秩次测试(Wilcoxon signed-rank tests),其次是ANOVAs;
对比结果:
为了使比较更有意义,本文关注研究的特定子集,即关注那些将准确性作为任务绩效的直接衡量指标的研究,而这包括了绝大多数的研究;
其次,本文只报告将他们的模型与传统基线进行比较的研究,而仅将结果与其他 DL 方法进行比较的研究不包括在此比较中;
最后,在报告准确性差异时,本文关注的是每个任务的最佳建议模型和最佳基线模型之间的差异;
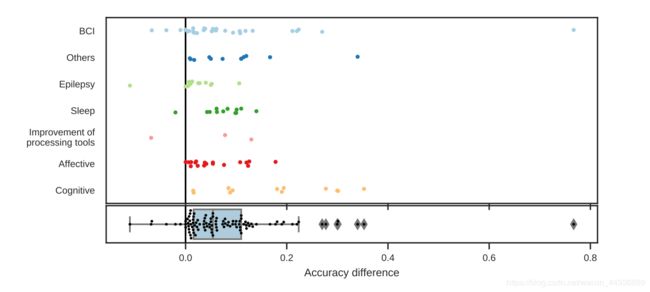
上图显示了每个提出的模型与每个研究领域对应的基线之间的准确性差异;
DL 的精度中值为5.4%,四分位范围为9.4%,只有4个值为负值,这意味着所提出的 DL 方法的性能低于基线;
准确性的最佳提高是由[161]获得的,他们的方法导致在 RSVP 分类任务中获得了76.7%的准确性;

可复现性:
在这里评估的是两个指标:数据的可用性和代码的可用性;



在临床实验中,缺乏标记的数据,而不是数据的数量,被明确指出是一个障碍;