数据竞赛—二手车价格预测—Task5 模型融合
内容

什么是 stacking
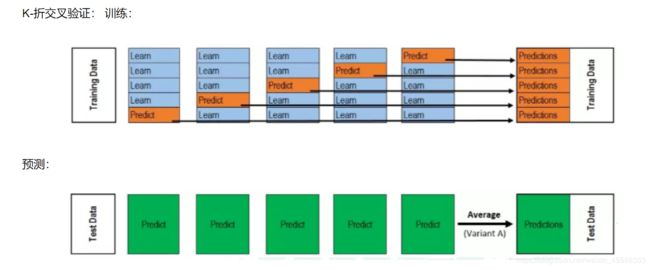
简单来说 stacking 就是当用初始训练数据学习出若干个基学习器后,将这几个学习器的预测结果作为新的训练集,来学习一个新的学习器
将个体学习器结合在一起的时候使用的方法叫做结合策略。对于分类问题,我们可以使用投票法来选择输出最多的类。对于回归问题,我们可以将分类器输出的结果求平均值。上面说的投票法和平均法都是很有效的结合策略,还有一种结合策略是使用另外一个机器学习算法来将个体机器学习器的结果结合在一起,这个方法就是Stacking。在stacking方法中,我们把个体学习器叫做初级学习器,用于结合的学习器叫做次级学习器或元学习器(meta-learner),次级学习器用于训练的数据叫做次级训练集。次级训练集是在训练集上用初级学习器得到的
k折交叉验证
回归\分类概率-融合
1、简单加权平均,结果直接融合:
sklearn.metrics中的评估方法介绍(accuracy_score, recall_score, roc_curve, roc_auc_score, confusion_matrix)
在理解赛题的时候特意介绍过这几个函数的用法、以及意义。
## 定义结果的加权平均函数
def Weighted_method(test_pre1,test_pre2,test_pre3,w=[1/3,1/3,1/3]):
Weighted_result = w[0]*pd.Series(test_pre1)+w[1]*pd.Series(test_pre2)+w[2]*pd.Series(test_pre3)
return Weighted_result
w = [0.3,0.4,0.3] # 定义比重权值
Weighted_pre = Weighted_method(test_pre1,test_pre2,test_pre3,w)
print('Weighted_pre MAE:',metrics.mean_absolute_error(y_test_true, Weighted_pre))
还有一些特殊的形式,比如mean平均,median平均
Stacking融合(回归)
def Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,test_pre1,test_pre2,test_pre3,model_L2= linear_model.LinearRegression()):
model_L2.fit(pd.concat([pd.Series(train_reg1),pd.Series(train_reg2),pd.Series(train_reg3)],axis=1).values,y_train_true)
Stacking_result = model_L2.predict(pd.concat([pd.Series(test_pre1),pd.Series(test_pre2),pd.Series(test_pre3)],axis=1).values)
return Stacking_result
model_L2= linear_model.LinearRegression()
Stacking_pre = Stacking_method(train_reg1,train_reg2,train_reg3,y_train_true,
test_pre1,test_pre2,test_pre3,model_L2)
print('Stacking_pre MAE:',metrics.mean_absolute_error(y_test_true, Stacking_pre))
可以发现模型结果相对于之前有进一步的提升,这是我们需要注意的一点是,对于第二层Stacking的模型不宜选取的过于复杂,这样会导致模型在训练集上过拟合,从而使得在测试集上并不能达到很好的效果
Voting投票机制
Voting即投票机制,分为软投票和硬投票两种,其原理采用少数服从多数的思想
sklearn的datasets使用:
sklearn.datasets模块主要提供了一些导入、在线下载及本地生成数据集的方法,可以通过dir或help命令查看,目前主要有三种形式

1本地加载数据集
数据集文件在sklearn安装目录下datasets\data文件下,如果有兴趣可进入模块目录查看
2、远程加载数据集
比较大的数据集,主要用于测试解决实际问题,支持在线下载,下载下来的数据,默认保存在~/scikit_learn_data文件夹下,可以通过设置环境变量SCIKIT_LEARN_DATA修改路径,datasets.get_data_home()获取下载路径。
3、构造数据集
下面以make_regression()函数为例:
make_regression(n_samples=100, n_features=100, n_informative=10, n_targets=1, bias=0.0, effective_rank=None, tail_strength=0.5, noise=0.0, shuffle=True, coef=False, random_state=None)

XGBClassifier函数
xgboost模块的XGBClassifier函数



RandomForestClassifier
参数
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion='gini', max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=’auto’, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, bootstrap=True, oob_score=False, n_jobs=1, random_state=None, verbose=0, warm_start=False, class_weight=None)
详解





硬投票:对多个模型直接进行投票,不区分模型结果的相对重要度,最终投票数最多的类为最终被预测的类
VotingClassifier
![]()
调用VotingClassifier上的fit方法将拟合存储在类属性self.estimators中的原始估计器的克隆。估计器可以使用set_params设置为’drop’
![]()
如果“硬”,则使用预测类标签进行多数规则投票。否则,如果“软”,则基于预测概率之和的argmax来预测类标签,这是推荐用于经过良好校准的分类器集合的。
软投票:和硬投票原理相同,增加了设置权重的功能,可以为不同模型设置不同权重,进而区别模型不同的重要度
eclf = VotingClassifier(estimators=[('xgb', clf1), ('rf', clf2), ('svc', clf3)], voting='soft', weights=[2, 1, 1])
clf1.fit(x_train, y_train)
分类的Stacking\Blending融合
stacking是一种分层模型集成框架。以两层为例,第一层由多个基学习器组成,其输入为原始训练集,第二层的模型则是以第一层基学习器的输出作为训练集进行再训练,从而得到完整的stacking模型, stacking两层模型都使用了全部的训练数据
LogisticRegression(solver='lbfgs')

RandomForestClassifier
![]()
要并行运行的作业数。拟合、预测、决策路径和应用都是在树上并行的。无表示1,除非在joblib.parallel_后端上下文中。-1表示使用所有处理器。
![]()
The function to measure the quality of a split. Supported criteria are “gini” for the Gini impurity and “entropy” for the information gain.
测量分割质量的函数。支持的标准是基尼杂质的“基尼”和信息增益的“熵”。注意:此参数是树特定的。
GradientBoostingClassifier
![]()
用于拟合单个基础学习者的样本分数。如果小于1.0,则会导致随机梯度增强。子样本与参数n_估计量相互作用。选择小于1.0的子样本会导致方差减少和偏差增加。
StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同。
参数:


KNeighborsClassifier
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, weights=’uniform’, algorithm=’auto’, leaf_size=30, p=2, metric=’minkowski’, metric_params=None, n_jobs=1, **kwargs)

StackingClassifier
StackingClassifier(classifiers,meta_classifier,use_probas = False,average_probas = False,verbose = 0)

GridSpec:
先是通过gridspec.GridSpec()创建区域,参数5,5的意思就是每行五个,每列五个,最后就是一个5×5的画布,相比于add_subplot(),使用网格布局的话可以更加灵活的控制占用多少空间
itertools.product
itertools.product(*iterables[, repeat])
笛卡尔积创建一个迭代器,生成表示item1,item2等中的项目的笛卡尔积的元组
repeat是一个关键字参数,指定重复生成序列的次数
product(range(2), repeat=3) --> 000 001 010 011 100 101 110 111
plot_decision_regions
plot_decision_regions(X, y, clf, feature_index=None, filler_feature_values=None, filler_feature_ranges=None, ax=None, X_highlight=None, res=None, legend=1, hide_spines=True, markers='s^oxv<>', colors='#1f77b4,#ff7f0e,#3ca02c,#d62728,#9467bd,#8c564b,#e377c2,#7f7f7f,#bcbd22,#17becf', scatter_kwargs=None, contourf_kwargs=None, scatter_highlight_kwargs=None)

其他方法
将特征放进模型中预测,并将预测结果变换并作为新的特征加入原有特征中再经过模型预测结果 (Stacking变化)(可以反复预测多次将结果加入最后的特征中
def Ensemble_add_feature(train,test,target,clfs):
# n_flods = 5
# skf = list(StratifiedKFold(y, n_folds=n_flods))
train_ = np.zeros((train.shape[0],len(clfs*2)))
test_ = np.zeros((test.shape[0],len(clfs*2)))
for j,clf in enumerate(clfs):
'''依次训练各个单模型'''
# print(j, clf)
'''使用第1个部分作为预测,第2部分来训练模型,获得其预测的输出作为第2部分的新特征。'''
# X_train, y_train, X_test, y_test = X[train], y[train], X[test], y[test]
clf.fit(train,target)
y_train = clf.predict(train)
y_test = clf.predict(test)
## 新特征生成
train_[:,j*2] = y_train**2
test_[:,j*2] = y_test**2
train_[:, j+1] = np.exp(y_train)
test_[:, j+1] = np.exp(y_test)
# print("val auc Score: %f" % r2_score(y_predict, dataset_d2[:, j]))
print('Method ',j)
train_ = pd.DataFrame(train_)
test_ = pd.DataFrame(test_)
return train_,test_
colsample_bytree
colsample_bytree是构造每棵树时列的子样本比率。每个树构造一次子采样。
一般比赛中效果最为显著的两种方法
xgb,lbg
print('predict XGB...')
model_xgb = build_model_xgb(x_train,y_train)
val_xgb = model_xgb.predict(x_val)
subA_xgb = model_xgb.predict(X_test)
print('predict lgb...')
model_lgb = build_model_lgb(x_train,y_train)
val_lgb = model_lgb.predict(x_val)
subA_lgb = model_lgb.predict(X_test)
q