基于社交网络的情绪化分析I
基于社交网络的情绪化分析I
By 白熊花田(http://blog.csdn.net/whiterbear) 转载需注明出处,谢谢。
之前说要进行微博的数据抓取并进行相关的分析,这里就是了。
题目来源
这是我的毕设题目,题目来源:汪顺平博客。在开始毕设时,我联系过这位博主,当时他是已经下载完数据准备分析了,后面一直没有联系了,参考了他数据下载的代码。我从三月末开始毕设,六月初结束,共两个月多点时间。这里将按数据的下载,数据处理,数据的情感分析的顺序来简要记录下我的毕设。
意义
使用数据分析的方法,从数学的角度去研究在社交网络上人们表达情绪的倾向。
数据的采集
这一部分是前期的重点,没有数据如何进行数据分析?
数据对象的选择
数据对象的选择,人人网已经没落,而且非好友无法访问,放弃;微信朋友圈也是无法访问非好友的数据,它是私密性的,放弃;新浪微博,公开访问,网上教程众多,选择。在确定数据对象为新浪微博后,选择了学校这个群体。这个群体有着很多优势:
- 大学学生多半都使用微博
- 大学学生的微博多半不是广告
基于此,我选择了五所高校,分别是大连理工大学,清华大学,北京大学,南京大学,华东政法大学,这五所学校南北有别,文理也有差异。
数据采集的思路和流程
数据采集的思路是,先手动给定几个一个学校入口的微博账号,通过这些微博账号下载他们的关注列表,之后下载关注列表里的该学校的微博用户的关注列表,以此循环,最后如果数据足够了,则停止下载,转而下载另一个学校的数据。
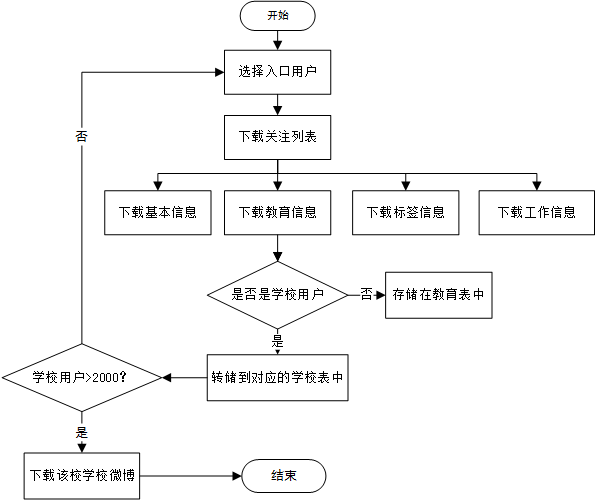
数据采集的流程是:第一步,选择入口用户id并存储到对应的学校表中。第二步,下载学校表中用户的关注列表,获取到的用户存储在用户表中。第三步,下载用户表中用户的教育信息,如果是刚刚五个学校的则存储到对应的学校表中。第四步,判断对应的学校表的用户数是否大于等于2000,如果不满足,则重复2到4。第五步,下载对应学校微博用户表里面用户的微博,并存储在对应的学校微博表中。
流程图为:
实现
使用给定cookie值的新浪微博访问方式(详细请参照:填入cookie登录微博),访问新浪微博手机页面下载数据。
个人基本信息界面:
http://weibo.cn/1873***652/info微博界面:
http://weibo.cn/u/1873***652?page=1关注列表界面:
http://weibo.cn/1873***652/follow
最好不要试图通过爬虫抓取PC端的微博数据,PC端界面数据量比较庞大,而且数据分析处理也比较麻烦。一般知道了以上几个界面,而又做过爬虫的话,应该都知道怎么抓取数据了,要注意的是,使用这种cookie值的方式,在抓取一段时间后会失效,微博会短时间内的封号,这时需要多获取几个同学的微博号,使用一些时间函数进行伪随机访问。
使用的模块或技术有:beautifulsoup,re,requests,ConfigParser,threading等。
我用了五六个同学的微博账号,用时两个星期,最终的数据采集的结果为:5个学校*每个学校2000个用户*每个用户30条微博约等于25万条微博。
#总流程的伪码实现
while True:
entrance_weiboids = 从数据库中随机选择20条微博ID作为入口用户
# 下载入口ID的关注列表
followers = download_followers(entrance_weiboids)
# 下载被关注用户的基本信息
download_followers_profile(followers)
# 下载被关注用户的教育信息
download_followers_education(followers)
# 下载被关注用户的工作信息
download_followers_company(followers)
# 下载被关注用户的标签信息
download_followers_taginfo(followers)
# 从数据库中将教育信息为选定学校的转移到对应的学校信息表中
convey_followers_to_school()
# 如果学校用户大于2000人了,退出循环
if get_school_users() > 2000:
break
#下载这2000个人的微博
download_weibo()
总结
不过早的设计
在进行数据库设计时,我在不是很了解整体数据特征的时候,设计了整个的数据库表,而到随着数据采集的深入,很多的表的字段觉得多余了,同样也有很多的字段需要修改,这样的操作都是非常复杂的。所有后面,不得不重新建立了一个数据库重新进行数据表的设计。得到的教训是,在不了解数据之间的逻辑时,先不要急着追求大而全的设计,因为总有很多因素是当时设计时所考虑不到的,所以可以先设计出比较简单的,能够有效解决当前问题的方案,这样后期即使想添加修改也比较方便。
抓取问题的核心
在进行数据抓取时,我先是希望将获取的所有的数据都保存起来,比如微博用户的工作信息,标签信息,基本信息(性取向,性别,简介,地址,达人等等)。我希望能够有一个完整庞大的程序可以完美下载到所有的数据,然后还能智能地判断哪个cookie失效了等等。后来发现构建这样的程序只是个童话。所需要的只是微博数据而已,最后我只使用了获取关注列表模块,获取教育信息模块,已经获取原创无图微博模块。发现删减后,整个程序的思路变得清晰了。所以,在解决问题时,先关注问题的核心,想办法简化问题,解决主要问题。如果一件事你觉得太复杂,你可能没有弄明白它,如果你设计了复杂的设计,你极有可能半途而废。
联系方式
如果你想要微博数据,或者想要包含中间处理pickle数据的代码,可以发邮件给我。