JVM---小白能看懂的内存分配和垃圾回收(有趣的图文教程)
插播一条:
为什么要了解这个,其实我之前也觉得是不是大公司故意提高门槛,故意找事。不就是一个ctrl+c,和一个ctrl+v么?实在不行百度和谷歌呗。事实上,今年到现在写这个东西的时候我发现越想往高处走,你的基础越得扎实。练武不练功到头一场空。而每个人都是会在3年为一个楷,会达到瓶颈。那么如何突破?是因为你的定位不一样了,你需要成为一名架构设计的人或者一个专家,当然 你需要更多的 money,这不就是原因么?你需要在内存泄露或者内存溢出的时候快速定位到问题,或者高并发的场景下,你是要吞吐量还是考虑性能响应时间,别人会 心里默默的说 真特么牛逼。这就够了。所以开始吧!如果还没想到为什么你要了解这个,那么就暂时先敲代码吧。以后再来看。
1、getting started
首先哪些是我们需要特别关注的:由于之前我们已经看过内存分配的场景,如果没看过则点击这里先简单了解下。
图又该出现了:

首先我们明确一点的是线程私有的有哪些?对,java栈和本地方法栈,程序计数器。那么他们的生命周期是随着线程的,线程死亡,则他们的栈内存被回收。那么共有的堆内存和方法区(1.8以下依然有,1.8+没有替代的叫做元空间),他们的内存根据不同的类导致需要的内存也是不一样的,动态的。所以垃圾收集器 garbage collection主要针对于他处理。
2、如何判定是否需要回收(根据对象的存活状态,是否有被引用)
可以1分钟的时间初步了解下,有个知识概念。1分钟入门JVM性能调优
1分钟入门里面讲到的


那么看完上面的几个算法,我提了几个问题,
第一根节点是哪些东西?
第二老提的引用有哪几种形式?
第三是现在jvm虚拟机默认的采用的垃圾回收算法每个代的使用情况?
如果会了跳过这里,不会的话,继续往下看。
根节点GC roots如下4个方面:
1、虚拟机栈(栈帧中的本地变量表)中引用的对象
2、方法区(元空间)中类静态属性引用的对象
3、常量引用的对象
4、本地方法栈中JNI(通俗说Native方法)引用的对象
引用类型:
强引用:强关联 Ha ha =new Ha();这种引用关系存在就不会被回收
软引用:二次收集的时候如果收集后内存还不够则OOM
弱引用:每次收集都有它
虚引用:作用只是在回收的时候得到一个系统通知
元空间或者方法区:
可以通过-XX:TraceClassLoading,-XX:TraceClassUnLoading,-verbose:class观察类的加载和卸载信息。
3、垃圾收集器
3.1.
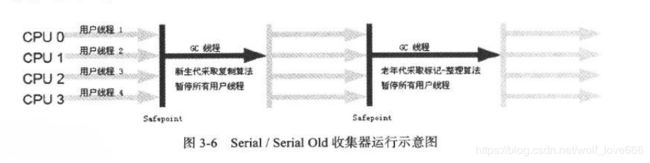
单线程最老的一代收集器,对于运行在Client模式下的虚拟机为了获得最高的单线程收集效率,是很好的选择。
3.2.

如果现在你使用的jdk版本低于8的话那么CMS唯一的搭档就是它,除了Serial老的垃圾收集器。
在多核的情况下它才会比Serial强,单核情况下由于线程交互的开销,不如Serial.
3.3.
吞吐量优先收集器Parallel Scavenge。-XX:+UseAdaptiveSizePolicy开关,添加以后自动适配新生代-Xmn、-XX:SurvivorRatio、-XX:PretenureSizeThreshold。这种方式叫做自适应调节策略GC Ergonomics。
3.4
Serial Old是Serial的老年代版本
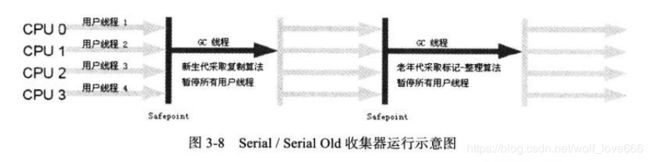
3.5
Parallel 吞吐量优先收集器

3.6
CMS收集器
B/S(重视服务的响应速度和时间)
CMS基于标记-清除算法实现,分为四个步骤
初始标记(CMS initial mark)-----会引发stw
并发标记(CMS concurrent mark)
重新标记(CMS remark)-----会引发stw
并发清除(CMS concurrent sweep)
对于初始标记,只是标记一下GC Roots能直接关联到的对象,速度很快。
并发标记就是GC Roots Tracing的过程
重新标记就是修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段停顿时间会比初始标记阶段长,比并发标记的时间短。

缺点如下:
1、CPU大于4还能忍个,低配置则无法忍受
CMS默认回收线程数(CPU数+3)/4,也就是当CPU在4个以上时,并发回收线程数占据了25%的CPU资源。并随着CPU的数量增加而下降。但是如果是低配的低于4个CPU,则CPU就会拿出一半的运算能力执行并发回收,这样用户程序的负载能力加上并发回收能力就占据了整个CPU.当然速度就会下降一半的,用户是接收不了的。
2、浮动垃圾导致二次full gc
为了避免Concurrent Mode Failure,以及Floating Garbage。一般会设置下CMS启动占用比例来提高触发条件。-XX:CMSInitiatingOccupancyFraction。jdk1.6中如果不更改,默认是92%。一般实际经验会设为65%左右。
3、碎片化严重
由于基于标记-清除算法,所以空间产生大量碎片。这样导致的是即使依然老年代有很大剩余空间,但是无法找到足够的空间给大对象导致Full gc。为了解决这个问题,CMS提供了内存压缩参数。-XX:UseCMSCompactAtFullCollection开关参数(默认开启的)但是这样就导致在合并内存压缩的时候无法并发进行,这样就会延长停顿时间。我们还可以使用-XX:CMSFullGCsBeforeCompaction。用来设置执行多少次不压缩的Fullgc,然后来一次压缩。(默认0,每次都压缩进行碎片整理)
3.7
G1收集器可以点击这里
G1的特点:
3.7.1并行与并发
3.7.2分代收集
3.7.3空间整合(基本不会产生内存空间碎片)
3.7.4可预测的停顿(可以通过设置最大的停顿时间来让GC回收尽量满足,但是这里说明一点,如果你的堆空间确实垃圾对象很多,那么他只能是尽量满足,满足不了也正常,这里不要出现,我设置了时间为什么没起作用的疑问。-XX:MaxGCPauseMillis)

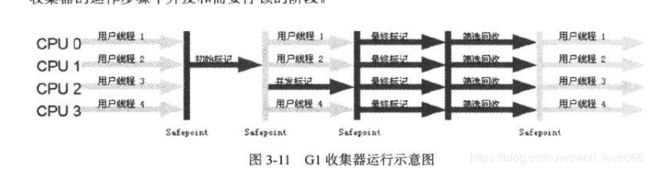
如下是G1收集器回收过程中的一次完整日志。
如果这里对于垃圾回收的几个关键词不太懂可以先了解下1分钟入门java内存调优


名词解析:Rset(记忆集)
全称是Remembered Set,是辅助GC过程的一种结构,典型的空间换时间工具,和Card Table有些类似。还有一种数据结构也是辅助GC的:Collection Set(CSet),它记录了GC要收集的Region集合,集合里的Region可以是任意年代的。在GC的时候,对于old->young和old->old的跨代对象引用,只要扫描对应的CSet中的RSet即可。
逻辑上说每个Region都有一个RSet,RSet记录了其他Region中的对象引用本Region中对象的关系,属于points-into结构(谁引用了我的对象)。而Card Table则是一种points-out(我引用了谁的对象)的结构,每个Card 覆盖一定范围的Heap(一般为512Bytes)。G1的RSet是在Card Table的基础上实现的:每个Region会记录下别的Region有指向自己的指针,并标记这些指针分别在哪些Card的范围内。 这个RSet其实是一个Hash Table,Key是别的Region的起始地址,Value是一个集合,里面的元素是Card Table的Index。如图是表示了RSet、Card和Region的关系

{Heap before GC invocations=48269 (full 0):
//垃圾回收 堆内存情况描述
garbage-first heap total 5267456K, used 4729987K [0x000000067e800000, 0x00000007c0000000, 0x00000007c0000000)
区域大小
region size 2048K, 1366 young (2797568K), 2 survivors (4096K)
//元空间1.8+都有,1.8以前叫做方法区PermSpace
Metaspace used 77790K, capacity 162832K, committed 162944K, reserved 1253376K
class space used 8458K, capacity 8727K, committed 8832K, reserved 1048576K
Gc关于年轻代收集暂停时间0.1703878 secs
2018-10-30T12:14:59.120+0800: 2922410.187: [GC pause (G1 Evacuation Pause) (young), 0.1703878 secs]
Gc工作器一共43个,并行时间花了69.7ms,下面是每一步骤的花费时间
第一步并行标记
[Parallel Time: 69.7 ms, GC Workers: 43]
//GC工作器启动43个最小的时间,平均时间,最大的时间,最大最小相差时间间隔
[GC Worker Start (ms): Min: 2922410187.2, Avg: 2922410198.3, Max: 2922410202.0, Diff: 14.8]
扫描Roots花费的时间,Sum表示total cpu time,下同
[Ext Root Scanning (ms): Min: 0.0, Avg: 0.4, Max: 9.8, Diff: 9.8, Sum: 18.0]
可以看上面的图描述,每个线程花费在更新Remembered Set上的时间。
[Update RS (ms): Min: 0.0, Avg: 0.1, Max: 2.0, Diff: 1.9, Sum: 4.1]
进行中的缓存buffers时间
[Processed Buffers: Min: 0, Avg: 8.4, Max: 165, Diff: 165, Sum: 362]
扫描CS中的region对应的RSet,因为RSet是points-into,所以这样实现避免了扫描old generadion region,但是会产生float garbage
[Scan RS (ms): Min: 0.1, Avg: 0.1, Max: 0.9, Diff: 0.9, Sum: 5.6]
扫描code root耗时。code root指的是经过JIT编译后的代码里,引用了heap中的对象。引用关系保存在RSet中。
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1]
拷贝活的对象到新region的耗时
[Object Copy (ms): Min: 0.0, Avg: 2.5, Max: 61.5, Diff: 61.5, Sum: 108.3]
线程结束,在结束前,它会检查其他线程是否还有未扫描完的引用,如果有,则"偷"过来,完成后再申请结束,这个时间是线程之前互相同步所花费的时间。
[Termination (ms): Min: 0.0, Avg: 55.2, Max: 59.3, Diff: 59.3, Sum: 2373.3]
其他GC工作器的耗费时间
[GC Worker Other (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 2.6]
每个线程工作器的总时间
[GC Worker Total (ms): Min: 54.7, Avg: 58.4, Max: 69.5, Diff: 14.8, Sum: 2512.0]
每个线程结束的时间。
[GC Worker End (ms): Min: 2922410256.6, Avg: 2922410256.7, Max: 2922410256.8, Diff: 0.2]
第二步用来将code root修正到正确的evacuate之后的对象位置所花费的时间
[Code Root Fixup: 0.3 ms]
第三步更新code root 引用的耗时,code root中的引用因为对象的evacuation而需要更新
[Code Root Migration: 0.1 ms]
第四步清除code root的耗时,code root中的引用已经失效,不再指向Region中的对象,所以需要被清除。
[Code Root Purge: 0.0 ms]
第五步清除card table的耗时。
[Clear CT: 0.6 ms]
其他耗费时间5.8ms,包括选择CSet,处理已用对象,引用入ReferenceQueues,释放CSet中的region到free list。
[Other: 99.6 ms]
选择CSet时间
[Choose CSet: 0.0 ms]
处理已用对象
[Ref Proc: 97.1 ms]
引用入ReferenceQueues
[Ref Enq: 0.1 ms]
重新安排 cards时间
[Redirty Cards: 0.0 ms]
释放CSet中的region到free list
[Free CSet: 1.5 ms]
新生代清空了,下次扩容到2728.0M
[Eden: 2728.0M(2728.0M)->0.0B(2728.0M) Survivors: 4096.0K->4096.0K Heap: 4619.1M(5144.0M)->1890.9M(5144.0M)]
堆GC回收之后的情况
Heap after GC invocations=48270 (full 0):
垃圾回收堆内存分配
garbage-first heap total 5267456K, used 1936257K [0x000000067e800000, 0x00000007c0000000, 0x00000007c0000000)
区域大小(young-eden年轻代,survivors-s0/s1,存活代)
region size 2048K, 2 young (4096K), 2 survivors (4096K)
元空间大小
Metaspace used 77790K, capacity 162832K, committed 162944K, reserved 1253376K
类空间
class space used 8458K, capacity 8727K, committed 8832K, reserved 1048576K
}
[Times: user=0.64 sys=0.01, real=0.18 secs]
这里引用美团技术团队的一个案例来完全说明下G1的垃圾回收的humongous allocation大对象回收的情况,因为目前我的应用没有产生那么大的对象。借用他们的一个案例如下:
global concurrent marking过程日志
66955.252: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: occupancy higher than threshold, occupancy: 1449132032 bytes, allocation request: 579608 bytes, threshold: 1449
551430 bytes (45.00 %), source: concurrent humongous allocation]
2014-12-10T11:13:09.532+0800: 66955.252: Application time: 2.5750418 seconds
66955.259: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation, reason: requested by GC cause, GC cause: G1 Humongous Allocation]
{Heap before GC invocations=1874 (full 4):
garbage-first heap total 3145728K, used 1281786K [0x0000000700000000, 0x00000007c0000000, 0x00000007c0000000)
region size 1024K, 171 young (175104K), 27 survivors (27648K)
Metaspace used 116681K, capacity 137645K, committed 137984K, reserved 1171456K
class space used 13082K, capacity 16290K, committed 16384K, reserved 1048576K
66955.259: [G1Ergonomics (Concurrent Cycles) initiate concurrent cycle, reason: concurrent cycle initiation requested]
2014-12-10T11:13:09.539+0800: 66955.259: [GC pause (G1 Humongous Allocation) (young) (initial-mark)
…….
2014-12-10T11:13:09.597+0800: 66955.317: [GC concurrent-root-region-scan-start]
2014-12-10T11:13:09.597+0800: 66955.318: Total time for which application threads were stopped: 0.0655753 seconds
2014-12-10T11:13:09.610+0800: 66955.330: Application time: 0.0127071 seconds
2014-12-10T11:13:09.614+0800: 66955.335: Total time for which application threads were stopped: 0.0043882 seconds
2014-12-10T11:13:09.625+0800: 66955.346: [GC concurrent-root-region-scan-end, 0.0281351 secs]
2014-12-10T11:13:09.625+0800: 66955.346: [GC concurrent-mark-start]
2014-12-10T11:13:09.645+0800: 66955.365: Application time: 0.0306801 seconds
2014-12-10T11:13:09.651+0800: 66955.371: Total time for which application threads were stopped: 0.0061326 seconds
2014-12-10T11:13:10.212+0800: 66955.933: [GC concurrent-mark-end, 0.5871129 secs]
2014-12-10T11:13:10.212+0800: 66955.933: Application time: 0.5613792 seconds
2014-12-10T11:13:10.215+0800: 66955.935: [GC remark 66955.936: [GC ref-proc, 0.0235275 secs], 0.0320865 secs]
[Times: user=0.05 sys=0.00, real=0.03 secs]
2014-12-10T11:13:10.247+0800: 66955.968: Total time for which application threads were stopped: 0.0350098 seconds
2014-12-10T11:13:10.248+0800: 66955.968: Application time: 0.0001691 seconds
2014-12-10T11:13:10.250+0800: 66955.970: [GC cleanup 1178M->632M(3072M), 0.0060632 secs]
[Times: user=0.02 sys=0.00, real=0.01 secs]
2014-12-10T11:13:10.256+0800: 66955.977: Total time for which application threads were stopped: 0.0088462 seconds
2014-12-10T11:13:10.257+0800: 66955.977: [GC concurrent-cleanup-start]
2014-12-10T11:13:10.259+0800: 66955.979: [GC concurrent-cleanup-end, 0.0024743 secs
在巨大对象分配之前,会检测到old generation 使用占比是否超过了 initiating heap occupancy percent(45%),因为
1449132032(used)+ 579608(allocation request:) > 1449551430(threshold),所以触发了本次global concurrent marking。对于具体执行过程,上面的表格已经详细讲解了。值得注意的是上文中所说的initial mark往往伴随着一次YGC,在日志中也有体现:GC pause (G1 Humongous Allocation) (young) (initial-mark)。
补充一点知识点----关于GC日志开头:

担保机制导致的HandlerPromotionFailure,在1.7以后也不使用了,而是采用了每次晋升到老年代的平均大小与剩余可用空间做比较,否则就full gc
