x86-64上的栈帧布局
原作者:Eli Bendersky
http://eli.thegreenplace.net/2011/09/06/stack-frame-layout-on-x86-64
几个月前,我写了一篇名为Wherethe top oft he stack is on x86的文章,目的在于澄清有关x86架构上栈使用的一些误解。这篇文章包括了一幅展示了一个典型函数调用栈帧布局的有用的图形。在本文我将调查x86架构新锐的64位版本,x64[1]的栈帧布局。关注点将在Linux及其他遵循正式的SystemV AMD64 ABI(从这里可以得到)的操作系统。Windows使用了有些不同的ABI,在最后我会简短地提到它。
我不打算在这里详细模式x64完整的调用惯例。对此,你应该确实通读AMD64ABI。
大量的寄存器
X86仅有8个通用寄存器可用(eax,ebx,ecx,edx,ebp,esp,esi,edi)。X64将它们扩展为64位(前缀r而不是e),并增加了另外8个(r8,r9,r10,r11,r12,r13,r14,r15)。因为某些x86寄存器有特殊隐含意义,并不能真正通用(最明显的ebp与esp),实际的增加比看起来要更多。
我在一篇关注栈帧的文章里提及这是有原因的。相对大量的可用寄存器影响了ABI某些重要的设计决策,比如在寄存器中传递许多实参,因此使得栈不像以前那么有用[2]。
实参传递
这里我准备有意简化讨论,关注整数/指针实参[3]。根据ABI,一个函数的头6个整数或指针实参在寄存器中传递。第一个放在rdi,第二个在rsi,第三个在rdx,然后rcx,r8以及r9。仅第七及以后的实参在栈上传递。
栈帧
记住上面所说,让我们看一下这个C函数的栈帧看起来像什么:
longmyfunc(long a, long b, long c, long d,
long e, long f, long g, long h)
{
long xx = a * b * c * d *e * f * g * h;
long yy = a + b + c + d +e + f + g + h;
long zz = utilfunc(xx, yy,xx % yy);
return zz + 20;
}
[1] 这个架构有许多名字。溯源自AMD,称为AMD64,后来由Intel实现,称为IA-32e,然后是EM64T,最后Intel 64。它也被称为x86-64。不过我喜欢x64这个名字——它好且短。
[2] X86有指定在寄存器中传递某些实参的调用惯例。最知名的可能是fastcall。不幸的是,在平台间它不一致。
[3] ABI也定义了通过xmm寄存器传递浮点实参。这个想法与整数非常类似,不过,恕我直言,在文章里包含浮点实参将使它没有必要地复杂化了。
这是栈帧:
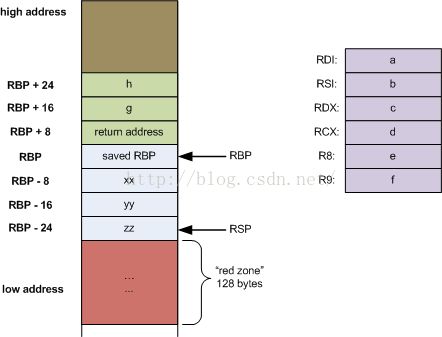
因此前6个实参通过寄存器传递。但除此之外,这与x86上发生的看上去没有太大不同[1],除了奇怪的“红区”。那是什么?
红区
首先我从AMD64 ABI摘取了正式的定义:
由%rsp指向位置以外128字节的区域被视为保留的,不应该被信号或中断处理句柄改写。因此,函数可以将这个区域用于无需跨越函数调用的临时数据。特别的,叶子函数可以将这个区域用作它们整个栈帧,而不是在prologue与epilogue中调整栈指针。这个区域称为红区。
简单地说,红区是一个优化。代码可以假定rsp以下128个字节不会被信号或中断处理句柄破坏,因此可以用于临时数据,无需显式地移动栈指针。最后一句是这个优化所在——递减rsp并保存它是在对数据使用红区时,可以被节省的两条指令。
不过,记住红区将被函数调用破坏,因此它通常在叶子函数(不调用其他函数的函数)中最有用。
回忆一下上面的例子代码中myfunc如何调用另一个名为utilfunc的函数。这是有意这样做的,使得myfunc非叶子,因此阻止编译器应用红区优化。看一下utilfunc的代码:
longutilfunc(long a, long b, long c)
{
long xx = a + 2;
long yy = b + 3;
long zz = c + 4;
long sum = xx + yy + zz;
return xx * yy * zz + sum;
}
这确实是一个叶子函数。让我们看一下在使用gcc编译时栈帧看起来像什么:
[1] 这里我撒了一点谎。 任何名副其实的编译器(当然包括gcc)也将对局部变量使用寄存器,特别是在寄存器丰富的x64上。但如果局部变量很多(或者它们很大,像数组或结构体),它们将栈上进行。
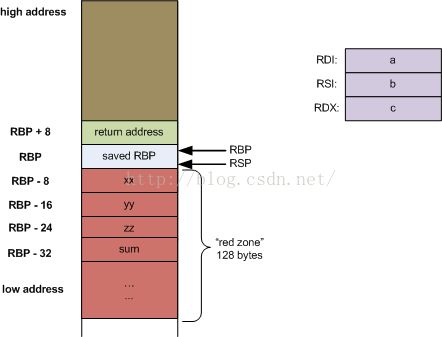
因为utilfunc仅有3个实参,调用它不要求栈使用,因为所有的实参都适用寄存器。另外,因为它是一个叶子函数,gcc选择对其所有局部变量使用红区。这样,无需减少rsp(随后恢复)来为这些数据分配空间。
保留基地址指针
基地址指针rbp(以及x86上它的前身ebp),作为一个函数执行期间栈帧起始的一个稳定“锚点”,对手动反汇编代码以及调试都十分便利[1]。
不过,不久前,注意到编译器生成的代码不是真正地需要它(编译器很容易追踪rsp的偏移),DWARF调试格式提供了无需基地址指针访问栈帧的方式(CFI)。
这是为什么某些编译器开始对进取的优化忽略基地址指针,因此缩短了函数的prologue与epilogue,并提供了多一个通用寄存器(记得吗,在只有有限GPR的x86上这相当有用)。
Gcc在x86上缺省保留基地址指针,但允许以-fomit-frame-pointer编译选项进行优化。到底有多推荐使用这个选项是一个有争议的问题——如果有兴趣你可以google一下。
不管怎么说,AMD64 ABI引入的另一个“革新”是使得基地址指针显式可选,规定:
作为栈帧一个帧指针的%rbp的便利使用,可以通过使用%rsp(栈指针)索引栈帧来避免。这个技术在prologue与epilogue中节省了两条指令,并使得另一个通用寄存器(%rbp)可用。
Gcc坚持这个建议,在以优化编译上,在x64上缺省忽略帧指针。通过提供-fno-omit-frame-pointer选项,给出了保留它的一个选择。 为了清晰起见,上面显示的栈帧的生成没有忽略帧指针。
Windows x64 ABI
在x64上Windows实现自己与ADM64ABI稍有不同的版本。我将只是简单地讨论Windowsx64 ABI,谈论它的栈帧与AMD64的如何不同。以下是主要的差别:
1. 仅4个整数/指针实参在寄存器中传递(rcx,rdx,r8,r9)。
2. 没有红区的概念。事实上,这个ABI明确声明rsp以下区域被视为volatile,使用是不安全的。操作系统、调试器或中断处理句柄可能改写这个区域。
3. 作为替代,由调用者在每个栈帧中提供了一个“寄存器参数区”[2]。在调用一个函数时,在返回地址之前,在栈上最后分配的是用于至少4个寄存器(每个8字节)的空间。这个区域对被调用者可用,而无需显式地分配它。这对可变参数函数以及调试(提供参数已知的位置,与此同时寄存器可能重用于其他目的)是有用的。尽管这个区域最初的设想是用作溅出在寄存器中传递的4个参数,现在编译器也为其他优化目的而使用它(例如,如果函数的局部变量需要少于32字节的栈空间,可以使用这个区域,而无需触碰rsp)。
在Windows x64 ABI中进行的另一个重要的改变是调用惯例的清理。不再有cdecl/stdcall/fastcall/thiscall/register/safecall这些疯狂的存在——只有一个“x64调用惯例”。为此欢呼!
关于此及Windows x64 ABI其他方面的更多信息,下面是一些好的链接:
· 关于x64软件约定的官方的MSDN页面——组织良好的资料,个人认为比AMD64ABI文档更容易理解。
- Everything You Need To Know To Start Programming 64-Bit Windows Systems——提供一个良好概览的MSDN文章。
- The history of calling conventions, part 5: amd64—— 高产的Windows编程布道者Raymond Chen的一个文章。
- Why does Windows64 use a different calling convention from all other OSes on x86-64?——这个值得一问的问题的一个有趣的讨论。
- Challenges of Debugging Optimized x64 code——关于在编译器生成的x64代码的“可调试性” (且其缺乏性)。
[1] 因为在一个函数里,rbp总是指向前一个栈帧,它形成了栈帧的一种链表,在任何时候调试器可以用来访问栈执行追踪(在core dump中也一样)。
[2]有时也称为“” called "home space" sometimes.