推荐算法3—基于用户的协同过滤算法
基于邻域的算法是推荐系统中最基本的算法,该算法分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法。
1 基础算法
在一个在线个性化推荐系统中,当一个用户A需要个性化推荐时,可以先找到和他有相似兴趣的其他用户,然后把那些用户喜欢的、而用户A没有听说过的物品推荐给A。这种方法称为基于用户的协同过滤算法。
给定用户u和用户v,令N(u)表示用户u曾经有过正反馈的物品集合,令N(v)为用户v曾经有过正反馈的物品集合。那么,我们可以通过如下的Jaccard公式简单地计算u和v的兴趣相似度,或者通过余弦相似度计算:
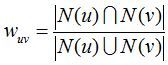
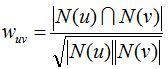
但这种方法的时间复杂度是O(|U|*|U|),这在用户数很大时非常耗时。事实上,很多用户相互之间并没有对同样的物品产生过行为,即很多时候 N(u)与N(v)的交集为0。我们可以首先计算出 N(u)与 N(v)交集不为0的用户对(u,v),然后再对这种情况除以分母。
为此,可以首先建立物品到用户的倒排表,对于每个物品都保存对该物品产生过行为的用户列表。令稀疏矩阵C[u][v]= N(u)交N(v) 。那么,假设用户u和用户v同时属于倒排表中K个物品对应的用户列表,就有C[u][v]=K。从而,可以扫描倒排表中每个物品对应的用户列表,将用户列表中的两两用户对应的C[u][v]加1,最终就可以得到所有用户之间不为0的C[u][v]。
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W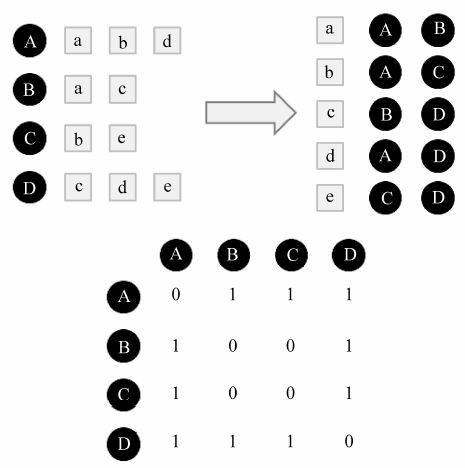
得到用户之间的兴趣相似度后,UserCF算法会给用户推荐和他兴趣最相似的K个用户喜欢的物品。如下的公式度量了UserCF算法中用户u对物品i的感兴趣程度:
![]()
其中,S(u, K)包含和用户u兴趣最接近的K个用户,N(i)是对物品i有过行为的用户集合,wuv是用户u和用户v的兴趣相似度,rvi代表用户v对物品i的兴趣,因为使用的是单一行为的隐反馈数据,所以所有的rvi=1。
如下代码实现了上面的UserCF推荐算法:
def Recommend(user, train, W):
rank = dict()
interacted_items = train[user]
for v, wuv in sorted(W[u].items, key=itemgetter(1), reverse=True)[0:K]:
for i, rvi in train[v].items:
if i in interacted_items:
#we should filter items user interacted before
continue
rank[i] += wuv * rvi
return rank下面是MovieLens数据集中UserCF算法在不同K参数下的性能
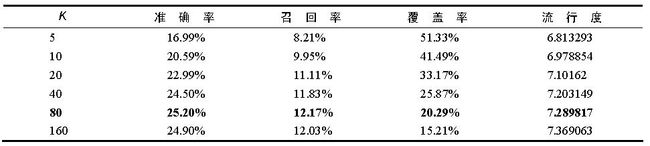
准确率和召回率:可以看到,推荐系统的精度指标(准确率和召回率)并不和参数K成线性关系。在MovieLens数据集中,选择K=80左右会获得比较高的准确率和召回率。因此选择合适的K对于获得高的推荐系统精度比较重要。当然,推荐结果的精度对K也不是特别敏感,只要选在一定的区域内,就可以获得不错的精度。
流行度:可以看到,在3个数据集上K越大则UserCF推荐结果就越热门。这是因为K决定了UserCF在给你做推荐时参考多少和你兴趣相似的其他用户的兴趣,那么如果K越大,参考的人越多,结果就越来越趋近于全局热门的物品。
覆盖率:可以看到,在3个数据集上,K越大则UserCF推荐结果的覆盖率越低。覆盖率的降低是因为流行度的增加,随着流行度增加,UserCF越来越倾向于推荐热门的物品,从而对长尾物品的推荐越来越少,因此造成了覆盖率的降低。
2 用户相似度计算的改进
两个用户对冷门物品采取过同样的行为更能说明他们兴趣的相似度。
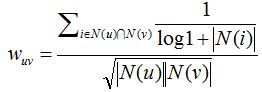
可以看到,该公式通过1/(log1+N(i))惩罚了用户u和用户v共同兴趣列表中热门物品对他们相似度的影响。
所以代码变为
def UserSimilarity(train):
# build inverse table for item_users
item_users = dict()
for u, items in train.items():
for i in items.keys():
if i not in item_users:
item_users[i] = set()
item_users[i].add(u)
#calculate co-rated items between users
C = dict()
N = dict()
for i, users in item_users.items():
for u in users:
N[u] += 1
for v in users:
if u == v:
continue
C[u][v] += 1 / math.log(1 + len(users))
#calculate finial similarity matrix W
W = dict()
for u, related_users in C.items():
for v, cuv in related_users.items():
W[u][v] = cuv / math.sqrt(N[u] * N[v])
return W