Python爬虫 在线爬取当当网畅销书Top500的图书信息
本实例还有另外的离线爬虫实现,有兴趣可点击离线爬取当当网畅销书Top500的图书信息
爬虫说明
1.使用requests和Lxml库爬取,(用BS4也很简单,这里是为了练习Xpath的语法)
2.爬虫分类为两种,一种是离线爬虫,即先将所爬取的网页保存到本地,再从本地网页中爬取信息;第二种是本实例使用的在线爬虫,即在网站中一边打开网页一边进行爬取.
3.在线爬虫的优点是:步骤少,不用保存文件和其他麻烦步骤;爬取速度快,代码短
4.离线爬虫的缺点是:在代码编写过程中,需要进行反复的修改,每次运行都要重新爬取在线网页,浪费资源,爬取速度受网络响应影响大,过快的爬取有可能收受到网站的限制等.
爬虫介绍
本次爬虫爬取的网页为:
图书畅销榜-10月畅销书排行榜-当当畅销图书排行榜
爬取的信息包括图书的排名,书名,作者,好评率,购买页面以及ISBN
如图:
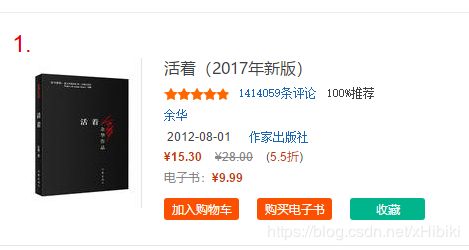
其中,ISBN需要在购买页面链接中继续爬取,找到ISBN

爬取之后的结果整理好存放到csv文件中.
最终成果如图:

爬虫代码
观察需要爬取的第一页和最后一页:
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-1
http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-25
发现只有最后一个数字改了,且每页显示20本图书,所以25*20=500,搞定.
这里自己了一个spider.py,里面写了一个小函数get_encoding()一个用于获取网站的编码格式
import requests
import re
def get_encoding(url, headers=None): # 一般每个网站自己的网页编码都是一致的,所以只需要搜索一次主页确定
'To get website\'s encoding from tag'#从标签中获取
res = requests.get(url, headers=headers)
charset = re.search("charset=(.*?)>", res.text)
if charset is not None:
blocked = ['\'', ' ', '\"', '/']
filter = [c for c in charset.group(1) if c not in blocked]
return ''.join(filter) # 修改res编码格式为源网页的格式,防止出现乱码
else:
return res.encoding # 没有找到编码格式,返回res的默认编码
在dangdang_best_selling_online.py中,代码如下:
import spider
import csv
import requests
import time
from lxml import etree
# 2018-10 前500的畅销书的书名 ,使用在线爬虫,思路和离线做了些修改
# 爬取25页书单页面,对每个书单页面保存详细页的页面(一一对应)
# 最后同时写入书单页的信息,每个列表保存一个信息和详细页的信息
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.79 Safari/537.36'
} # 设置headers
encoding = spider.get_encoding('http://www.dangdang.com', headers) # 获取主站编码
urls = ['http://bang.dangdang.com/books/bestsellers/01.00.00.00.00.00-month-2018-10-1-{}'.format(i) for i in
range(1, 26)]
# 在线爬虫的准备
detail_url = []
rank = []
site = []
name = []
star = []
author = []
ISBN = []
if __name__ == '__main__':
for i in range(24): # 0~24 ->1~25
res = requests.get(urls[i], headers)
res.encoding = encoding
selector = etree.HTML(res.text)
booklist = selector.xpath('//ul[@class="bang_list clearfix bang_list_mode"]/li')
book = [book for book in booklist]
for i in range(len(book)):
rank.append(book[i].xpath('div[1]/text()')[0]) # 排名
site.append(book[i].xpath('div[2]/a/@href')[0]) # 购买/详细页面
name.append(book[i].xpath('div[3]/a/text()')[0]) # 名字
star.append(book[i].xpath('div[4]/span/span/@style')) # 以星星宽度决定好评
author.append(book[i].xpath('div[5]/a/text()')) # 作者名
time.sleep(0.5)
for url in site:
res = requests.get(url, headers)
res.encoding = encoding
pattern = '//ul[@class="bang_list clearfix bang_list_mode"]/li/div[2]/a/@href'
ISBN.append(etree.HTML(res.text).xpath('//ul[@class="key clearfix"]/li[5]/text()')[0]) # 获取每一本书的详细页面
time.sleep(0.5)
执行的流程是:按循环顺序依次获取页面中的排名,名字,详细页面等,存放到列表中
爬取完25个页面后,在详细页面的列表中取出地址,继续进行爬取ISBN.
格式化输出和保存:
将分别保存有各个维度信息的列表进行格式化处理(清洗),最后按相同的次序写入到csv中
tmp = []
for s in star:
tmp.append(''.join([c for c in str(s) if c.isdigit() or c == '.']))
star = tmp
rank = [r.replace('.', '') for r in rank]
author = [' '.join(a) for a in author]
ISBN = [i.replace('国际标准书号ISBN:', '') + '\t' for i in ISBN]
output = open('d:/dangdang/result.csv', 'w', encoding=encoding, newline='') # 将信息导出到csv,设置newline=""去除写一行空一行的影响
writer = csv.writer(output) # csv writer
writer.writerow(('排名', '书名', '作者', '好评率', '购买页面', 'ISBN'))
for i in range(len(rank)):
writer.writerow((rank[i], name[i], author[i], star[i], site[i], ISBN[i])) # 保存到csv
不多赘述,有兴趣可以copy下来慢慢玩,最好就是打开畅销书的网页,然后对照审查元素慢慢研究lxml. 另外要注意的细节都以注释形式保存了.
写在最后
爬虫挺好玩的,所有的源代码和输出的csv文件都放在网盘里面了,还提供了离线的网页用于测试.
百度网盘
感兴趣就下载多多支持吧~
最终感谢没有限制我让我爬这么多网页的当当网的大力支持.
感谢提出要爬这个榜单数据用于工作的朱老板.