Kafka Confluent 简介
简介
基本模块
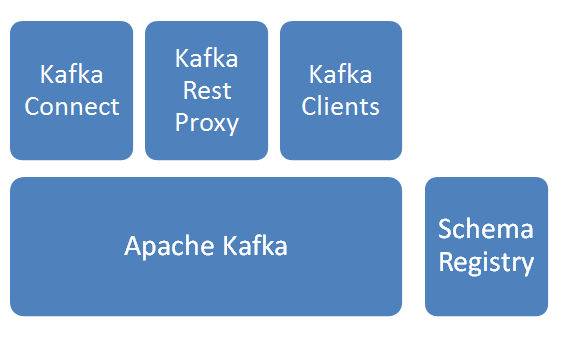
Apache Kafka
消息分发组件,数据采集后先入Kafka。Schema Registry
Schema管理服务,消息出入kafka、入hdfs时,给数据做序列化/反序列化处理。Kafka Connect
提供kafka到其他存储的管道服务,此次焦点是从kafka到hdfs,并建立相关HIVE表。Kafka Rest Proxy
提供kafka的Rest API服务。Kafka Clients
提供Client编程所需SDK。
说明:以上服务除Apache kafka由Linkedin始创并开源,其他组件皆由Confluent公司开发并开源。上图解决方案由confluent提供。
基本逻辑步骤
- 数据通过Kafka Rest/Kafka Client写入Kafka;
- kafka Connect任务作为consumer从kafka订阅数据;
- kafka Connect任务建立HIVE表和hdfs文件的映射关系;
- kafka connect任务收到数据后,以指定格式,写入指定hdfs目录;
实操:
1. 启动服务
启动kafka 服务
- 修改配置
/*
1.修改192.168.103.44、192.168.103.45、192.168.103.46三台服务器上配置
2.配置文件中broker.id值分别修改为0、1、2
*/
cd /home/ubuntu/confluent-2.0.0
vi etc/kafka/server.properties- 命令行启动
cd /home/ubuntu/confluent-2.0.0
nohup bin/kafka-server-start etc/kafka/server.properties &- 服务说明
kafka服务无Leader概念,服务访问端口为9092
启动Schema Register服务
- 命令行启动
//wonderwoman集群环境,只在woderwoman上启动了服务
cd /home/ubuntu/confluent-2.0.0
nohup bin/schema-registry-start etc/schema-registry/schema-registry.properties &- 服务说明
Schema Register服务端口为8081
启动Kafka Rest API服务
- 修改配置
// 修改schema服务器地址和zookeeper服务器地址
cd /home/ubuntu/confluent-2.0.0
vi etc/kafka-rest/kafka-rest.properties- 命令行启动
//wonderwoman集群环境,只在woderwoman上启动了服务
cd /home/ubuntu/confluent-2.0.0
nohup bin/kafka-rest-start ./etc/kafka-rest/kafka-rest.properties &- 服务说明
Schema Register服务端口为8082
启动Kafka connect服务
- 修改配置
/*
修改如下配置项:
1.bootstrap.servers, 所有kafka broker的地址
2.group.id 标志connect集群,集群内配一致
3.key.converter.schema.registry.url,schema服务地址
4.value.converter.schema.registry.url,schema服务地址
*/
cd /home/ubuntu/confluent-2.0.0/
vi etc/schema-registry/connect-avro-distributed.properties- 命令行启动
//启动分布式connect,在zookeeper集群内所有机器上启动
cd /home/ubuntu/confluent-2.0.0/
nohup bin/connect-distributed etc/schema-registry/connect-avro-distributed.properties > /tmp/1.log
2. 创建schema
- Rest API方式
- 准备shema的定义文件,例如myschema.json
- 注册topic和schema,返回schema的ID
curl -X POST -i -H "Content-Type: application/vnd.schemaregistry.v1+json" --data @myschema.json http://localhost:8081/subjects/20160427/versions
- Kafka Client方式
详见 Kafka Client提供的接口,支持java/c/c++等语言
3. 创建Topic
创建的topic名称为xianzhen,3个分区,每分区数据存两份
- 命令行方式
cd /home/ubuntu/confluent-2.0.0/
./bin/kafka-topics --create --topic xianzhen --partitions 3 --replication-factor 2 --zookeeper 192.168.103.44:2181Rest API方式
略,后续补充Kafka Client方式
详见 Kafka Client提供的接口,支持java/c/c++等语言
4. 创建Connector
分布式只支持以REST API的方式提交Connector作业
- Rest API方式
- 创建配置文件
vi confluentHive-connector.json
{
"name": "hive-final",
"config": {
"connector.class": "io.confluent.connect.hdfs.HdfsSinkConnector",
"tasks.max": "6",
"topics": "confluentHive",
"hdfs.url": "hdfs://ns1",
"hadoop.conf.dir": "/home/ubuntu/hadoop-2.7.1/etc/hadoop",
"hadoop.home": "/home/ubuntu/hadoop-2.7.1",
"flush.size": "100",
"rotate.interval.ms": "1000",
"hive.integration":true,
"hive.metastore.uris":"thrift://192.168.103.44:9083",
"schema.compatibility":"BACKWARD",
"hive.home":"/home/ubuntu/apache-hive-1.2.1-bin",
"hive.conf.dir":"/home/ubuntu/spark-1.6.1/conf"
}
}- 部分配置说明
| 配置项 | 说明 |
|---|---|
| name | Connector名称,会对应kafka consumer Group的名称 |
| connector.class | Connector实现类,连接hdfs时,配置见例 |
| tasks.max | 最大任务数量,对应于处理的线程数量,不是越多就越快,受kafka分区数限制 |
| topics | 订阅的kafka topic名称,也对应于最终HIVE的表名 |
| hdfs.url | hdfs的地址,和hadoop的core-site.xml中配置对应上 |
| hadoop.home | hadoop的目录 |
| hadoop.conf.dir | hadoop的配置目录 |
| hive.integration | 是否写入HIVE表 |
| hive.metastore.uris | hive Metastore服务地址 |
| hive.home | HIVE目录 |
| hive.conf.dir | HIVE的配置目录 |
- 提交Connector
curl -X POST -H "Content-Type: application/json" --data @confluent-connector.json http://192.168.103.44:8083/connectors5. 数据写入kafka
写入数据时,应带上schema,或者已创建schema的ID
REST API方式
curl -X POST -H "Content-Type: application/vnd.kafka.avro.v1+json" --data '{"value_schema_id":27, "records": [{"value": {"sip":"1.1.1.1", "dip":"1.1.1.2", "smac":"111", "dmac":"112"}}]}' http://192.168.103.44:8082/topics/confluentHiveKafka Client方式
详见 Kafka Client提供的接口,支持java/c/c++等语言