python---布尔类型赋值,字符串,len(),转义、拼接、替换、文件操作
python—布尔类型赋值,字符串,len(),转义、拼接、替换、文件操作
#1、布尔类型
root@72132server:~# python
Python 2.7.3 (default, Mar 14 2014, 11:57:14)
[GCC 4.7.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> bool(1==1)
True
>>> a = bool(2==2)#使用参数求值
>>> a
True
>>>
#2、字符串认知与应用
python默认的文件编码都是ascii码
unicode 描述出大部分全世界语音
utf8是unicode的一种标准
#3、len使用技巧--注意
root@72132server:~# clear
root@72132server:~# python
Python 2.7.3 (default, Mar 14 2014, 11:57:14)
[GCC 4.7.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> a = '1234'
>>> len(a)
4
>>> b = '哈哈哈我是中国人'
>>> len(b)
24
>>> c = '哈'
>>> len(c)
3
>>> d = u'哈'
>>> len(d)
1
>>> e = '哈哈哈哈'
>>> f = e.decode('utf-8')
>>> print f
哈哈哈哈
>>> print len(f)
4
>>>
>>>
>>> h = '哼哼哈哈'
>>> h = '哼哼哈哈'.decode('utf-8')
>>> print len(h)
4
>>> len(h)
4
>>> j = '哈哈哈哈'
>>> len(j)
12
>>>
#4、转义字符让文本更好处理
#\要放到需要转义的字符前面
>>> print 'adbcd'
adbcd
>>> print 'aasff''
File "" , line 1
print 'aasff''
^
SyntaxError: EOL while scanning string literal
>>> print 'aasff'\'
File "" , line 1
print 'aasff'\'
^
SyntaxError: unexpected character after line continuation character
>>> print 'aasff\''
aasff'
>>> print 'asdf\n'
asdf
>>> print 'asdf\t'
asdf
>>> print 'asdf\f'
asdf
>>> print 'asdf\2t'
asdft
>>> print 'asdf\2n'
asdfn
>>>
#\要放到需要转义的字符前面
#5、字符串前面跟着的小尾巴到底是什么东西
#u是把后面的字符串转成unicode码
#r是把后面的字符串不进行转义,原样输出
>>>
>>> i = u'哈哈'
>>> i
u'\u54c8\u54c8'
>>> print '\n'
>>> print r'\n'
\n
>>>
#6、访问子字符串,序列来了,使用切片方式访问
成员是有序排列的,可以通过下标偏移量访问到它的一个或者多个成员
>>> l = 'asdfgh'
>>> l[2]
'd'
>>> l[0]
'a'
>>> l[-1]
'h'
>>> l[-2]
'g'
>>> l[2,4]
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: string indices must be integers, not tuple
>>> l[2:4]
'df'
>>> print l[0]
a
>>> print l[-2:3]
>>> print l[-2:-3]
>>> print l[-1:3]
>>> print l[-1]
h
>>> len(l)
6
>>> l[0:4]
'asdf'
>>> l[-1:4]
''
>>> l[-1:-3]
''
>>> l[0:-3]
'asd'
>>> l[0:-1]
'asdfg'
>>> l[0:]
'asdfgh'
>>> l[0:-4]
'as'
>>> l[:-1]
'asdfg'
>>> m = '123456789'
>>> m[3]
'4'
>>> m[5]
'6'
>>> m[6] - m[2]
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: unsupported operand type(s) for -: 'str' and 'str'
>>> n = m[6] - m[2]
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: unsupported operand type(s) for -: 'str' and 'str'
>>>
#使用N种方式取出字母d
>>> y = 'abcd'
>>> y[1]
'b'
>>> y[3]
'd'
>>> y[-1]
'd'
>>> y[-1:-2]
''
>>> y[-1:]
'd'
>>> y[3:]
'd'
>>>
#使用split分割进行显示
>>> s ='i am lilei!!'
>>> s[2:4]
'am'
>>> b = s.split(' ')[1]
>>> print b
am
>>> b = s.split(' ')[2]
>>> print b
lilei!!
>>>
#7、替换字符串,使用help进行帮助查看
>>> help('str')
>>> help('str')
>>>
| replace(...)
| S.replace(old, new[, count]) -> string
|
| Return a copy of string S with all occurrences of substring
| old replaced by new. If the optional argument count is
| given, only the first count occurrences are replaced.
>>> o = 'abcdefg'
>>> o.replace('c','xwbxwb')
'abxwbxwbdefg'
>>> print o #没有变化的字符串
abcdefg
>>> p = o.replace('c','xwbxwb')
>>> id(a)
3074941920L
>>> id(o)
3074987488L
>>> id(p)
3074934688L
>>>
>>> print p #新的字符串
abxwbxwbdefg
>>>
#8、字符串拼接
#8.1、超级丑陋方式,千万别用
>>>
>>> q = 'abcd'
>>> r = 'uvwxyz'
>>> print q+r
abcduvwxyz
>>> print 'rst'+'kiopq'
rstkiopq
>>>
#8.2、可选方案之字符串模版,使用%s占位符
>>> print 'my name is %s lilei.' %'hanmeimei'
my name is hanmeimei lilei.
>>>
>>> print 'my name is %d lilei.' %1
my name is 1 lilei.
>>> print 'my name is %d lilei.' %'ss'
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: %d format: a number is required, not str
>>> print 'my name is %d lilei.' %55555
my name is 55555 lilei.
>>>
>
>>> print 'my name is %s lilei %s.' % ('hanmeimei','20')
my name is hanmeimei lilei 20.
>>>
>>> z = 'jay'
>>> a = 'python'
>>> print 'my name is %s ,i love %s.' % ('z','a')
my name is z ,i love a.
>>> print 'my name is %s ,i love %s.' % (z,a)
my name is jay ,i love python.
>>>
%s表示是占位符
#8.3、优秀的拼接方案,推荐使用最完美的方式
>>> u = 'a'
>>> v = 'bcdef'
>>> w = '123456'
>>> "".join(u,v,w)
Traceback (most recent call last):
File "" , line 1, in <module>
TypeError: join() takes exactly one argument (3 given)
>>> ",".join([u,v,w])#使用List方式进行拼接
'a,bcdef,123456'
>>> "".join([u,v,w])
'abcdef123456'
>>>
#9、读写文件操作
r read(读)
w write(写)
a append(在尾行添加)
>>> open('/root/python/oldtext.txt','w')
'/root/python/oldtext.txt', mode 'w' at 0xb746e860>
>>> x =open('/root/python/oldtext.txt','w')
>>> x.write('my name is da xue sheng!!')
>>> x.close()
>>> x = open('/root/python/oldtext.txt','r')
>>> help (x)
>>> print x.readline()
my name is da xue sheng!!
>>> print x.readline()
>>> print x.readline()
>>> print x.read(1000)
>>> x.seek(0)#把读取游标设置到初始位置
>>> print x.read(1000)
my name is da xue sheng!!
>>>
综合练习题:
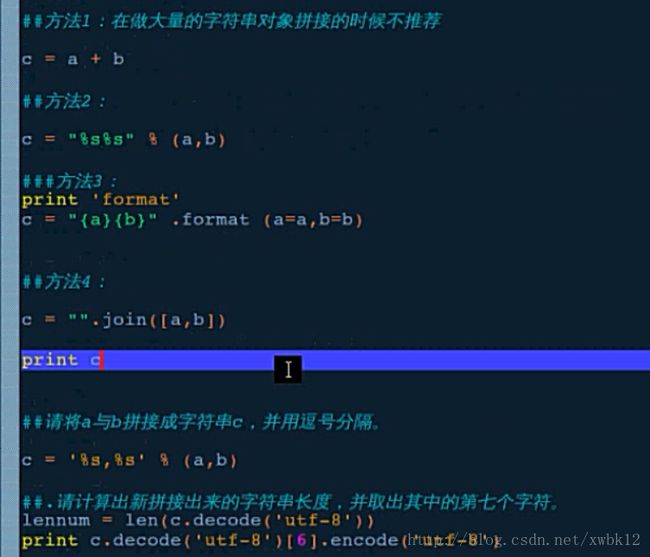
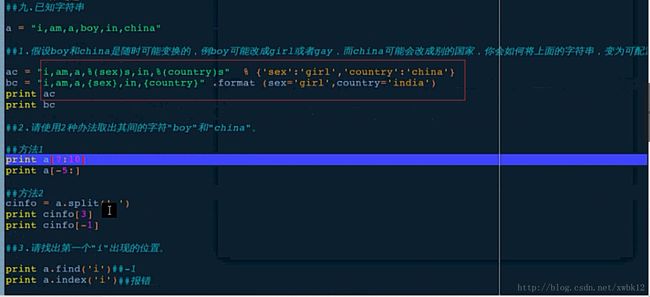

a.find()、a.index()、a.rfind()查找语句使用
a.find()与a.index()区别:
a.find()未找到的字符直接返回-1
a.index()未找到的字符报错
root@kali:~/python/laowangpy# python
Python 2.7.3 (default, Mar 14 2014, 11:57:14)
[GCC 4.7.2] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import string
>>> help(string)
>>> a = 'i am boy from china'
>>> a.find('i')
0
>>> a.find('i')
0
>>> a.index('i')
0
>>> a.find('i',a.find('china'))
16
>>> a.rfind('i')
16
>>> a.count(' ')
4
>>> a.find('m')
3
>>> a.find('j')
-1
>>> a.index('m')
3
>>> a.index('j')
Traceback (most recent call last):
File "" , line 1, in
ValueError: substring not found
>>>
root@kali:~/python/laowangpy# ls
geshihua.py hello.py _project test1.txt test2.txt test_uncode.py
root@kali:~/python/laowangpy# cat test_uncode.py
3#!/usr/bin/python
3#—- coding:utf-8 —-
f = open(“/root/python/laowangpy/test1.txt”,’r’)
content = f.read()
dcontent = content.decode(“utf-8”)#转载成unicode编码
print “–#1、输出内容–”
print content
print “–#2、计算该文件的原始长度–”
print len(content)
print “–#3、请除去该文本的换行符号–”
print content.replace(‘\n’,”)
print “–#4、请替换其中的字符‘2012’为‘2013’–”
print content.replace(‘2012’,’2013’)
print “–#5、请取出最中间的长度为5的字串–”
print dcontent[len(dcontent)/2:len(dcontent)/2+5].encode(“utf-8”)
print “–#6、请取出最后两个字符–”
print dcontent[-2:].encode(“utf-8”)
print “–#7、请从字符串的最初开始,截断该字符串,使其长度为11–”
print dcontent[0:10].encode(“utf-8”)
print “–8、请将#4题中的字符串保存为test2.py文本–”
rinfo = content.replace(‘2012’,’2013’)
print rinfo
f1 = open(‘/root/python/laowangpy/test2.txt’,’w’)
f1.write(rinfo)
f1.close()
root@kali:~/python/laowangpy#
运行情况:
root@kali:~/python/laowangpy# python test_uncode.py
–#1、输出内容–
2012来了。
2012不是世界末日。
2012欢乐多。
–#2、计算该文件的原始长度–
57
–#3、请除去该文本的换行符号–
2012来了。2012不是世界末日。2012欢乐多。
–#4、请替换其中的字符‘2012’为‘2013’–
2013来了。
2013不是世界末日。
2013欢乐多。
–#5、请取出最中间的长度为5的字串–
世界末日。
–#6、请取出最后两个字符–
。
–#7、请从字符串的最初开始,截断该字符串,使其长度为11–
2012来了。
20
–8、请将#4题中的字符串保存为test2.py文本–
2013来了。
2013不是世界末日。
2013欢乐多。
root@kali:~/python/laowangpy# cat test2.txt
2013来了。
2013不是世界末日。
2013欢乐多。