scrapy爬虫之模拟登录豆瓣
##简介
在之前的博文python爬虫之模拟登陆csdn使用urllib、urllib2、cookielib及BeautifulSoup等基本模块实现了csdn的模拟登录,本文通过scrapy模拟登录豆瓣,来深入了解下scrapy。
豆瓣登录需要输入图片验证码,我们的程序暂时不支持自动识别验证码,需要将图片下载到本地并打开以进行人工识别输入到程序中。
##分析豆瓣登录
1.分析豆瓣登录页的样式https://accounts.douban.com/login
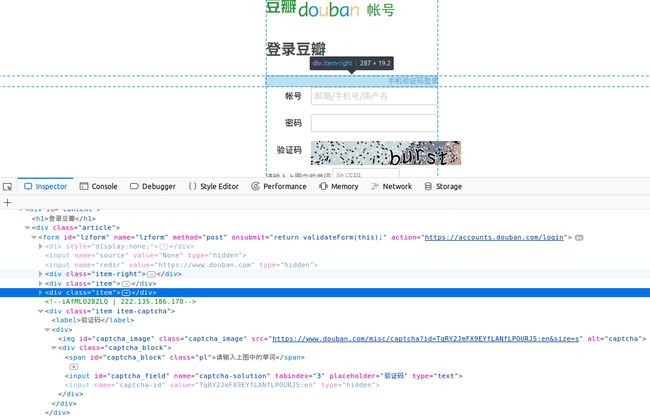
从上图可以看出:
(1).表单的action地址为
https://accounts.douban.com/login
(2).验证码图片的地址为
https://www.douban.com/misc/captcha?id=TqRY2JmFX9EYfLANfLPOURJ5:en&size=s
(3).captcha-id值
2.分析豆瓣登录页的form表单登录
通过登录页我们登录一次,查看post的数据

因此我们需要通过scrapy提取以下来填充表单:
captcha-id:图片验证码id
captcha-solution:图片验证码,我们通过查看图片手动输入验证码
其他如form_email等固定信息我们可以提前填入表单。
##实现
1.建立爬虫
source activate scrapy
#使用PIL打开图片验证码,以便我们识别手动输入
conda install PIL
pip install Pillow
scrapy genspider douban_login douban.com
2.编写爬虫
vim douban/spider/douban_login.py
# -*- coding: utf-8 -*-
import scrapy
import urllib
from PIL import Image
class DoubanLoginSpider(scrapy.Spider):
name = 'douban_login'
allowed_domains = ['douban.com']
# start_urls = ['http://www.douban.com/']
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0"}
def start_requests(self):
'''
重写start_requests,请求登录页面
'''
return [scrapy.FormRequest("https://accounts.douban.com/login", headers=self.headers, meta={"cookiejar":1}, callback=self.parse_before_login)]
def parse_before_login(self, response):
'''
登录表单填充,查看验证码
'''
print("登录前表单填充")
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
captcha_image_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
if captcha_image_url is None:
print("登录时无验证码")
formdata = {
"source": "index_nav",
"form_email": "[email protected]",
#请填写你的密码
"form_password": "********",
}
else:
print("登录时有验证码")
save_image_path = "/home/yanggd/python/scrapy/douban/douban/spiders/captcha.jpeg"
#将图片验证码下载到本地
urllib.urlretrieve(captcha_image_url, save_image_path)
#打开图片,以便我们识别图中验证码
try:
im = Image.open('captcha.jpeg')
im.show()
except:
pass
#手动输入验证码
captcha_solution = raw_input('根据打开的图片输入验证码:')
formdata = {
"source": "None",
"redir": "https://www.douban.com",
"form_email": "[email protected]",
#此处请填写密码
"form_password": "********",
"captcha-solution": captcha_solution,
"captcha-id": captcha_id,
"login": "登录",
}
print("登录中")
#提交表单
return scrapy.FormRequest.from_response(response, meta={"cookiejar":response.meta["cookiejar"]}, headers=self.headers, formdata=formdata, callback=self.parse_after_login)
def parse_after_login(self, response):
'''
验证登录是否成功
'''
account = response.xpath('//a[@class="bn-more"]/span/text()').extract_first()
if account is None:
print("登录失败")
else:
print(u"登录成功,当前账户为 %s" %account)
注意:请将代码中的登陆账号密码改成你自己的。
3.运行爬虫
#运行爬虫
scrapy crawl douban_login
运行过程中,爬虫会保存图片到本地并自动打开图片,方便我们识别验证码并手动输入:
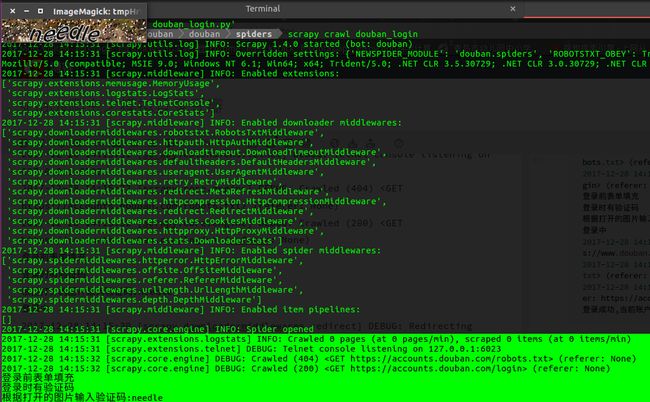
爬虫运行的调试信息主要如下:
#打印部分输出日志,主要是供我们调试使用
2017-12-28 14:15:31 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2017-12-28 14:15:31 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2017-12-28 14:15:32 [scrapy.core.engine] DEBUG: Crawled (404) (referer: None)
2017-12-28 14:15:32 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
登录前表单填充
登录时有验证码
根据打开的图片输入验证码:needle
登录中
2017-12-28 14:15:39 [scrapy.downloadermiddlewares.redirect] DEBUG: Redirecting (302) to from
2017-12-28 14:15:39 [scrapy.core.engine] DEBUG: Crawled (200) (referer: None)
2017-12-28 14:15:40 [scrapy.core.engine] DEBUG: Crawled (200) (referer: https://accounts.douban.com/login)
登录成功,当前账户为 三页的帐号
最后打印的信息为"登录成功,当前账户为 三页的帐号",显示出我们的豆瓣账号名称,说明scrapy模拟登录豆瓣是成功的。
##问题处理
在实现模拟登录过程中,碰到过几个问题在次也和大家分享下:
1.设置scrapy的user_agent
在博文scrapy爬虫之《琅琊榜2》话题title收集及词云展示我们是在settings中设置,本文是在爬虫中通过以下设置:
headers = {"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0"}
2.scrapy 导入PIL报错如下:
>>> import PIL
Traceback (most recent call last):
File "", line 1, in
File "/home/yanggd/miniconda2/envs/scrapy/lib/python2.7/site-packages/PIL/__init__.py", line 14, in
from . import version
ImportError: cannot import name version
#解决方案:
pip install Pillow
3.scrapy提示以下错误
DEBUG:Filtered offsite request to 'accounts.douban.com':
原因:start_requests中的 url的域名不能和文件中自己配置的allowed_domains不一致,否则会被过滤掉。我之前的设置为:
allowed_domains = ['www.douban.com']
而提交表单请求的url为"https://accounts.douban.com/login",因此出现问题。
解决办法可以通过停用过滤功能,添加"dont_filter=True",如下所示:
return scrapy.FormRequest.from_response(response, meta={"cookiejar":response.meta["cookiejar"]}, headers=self.headers, formdata=formdata, callback=self.parse_after_login, dont_filter=True)
或者
与allowed_domains设置一致,如:
allowed_domains = ['douban.com']
如果你对博文感兴趣,请关注我的公众号“木讷大叔爱运维”,与你分享运维路上的点滴。
