【爬虫】scrapy爬取股票历史数据并保存成CSV文档
这个爬虫是接着上个爬虫做的,先送上传送门:https://blog.csdn.net/yao09605/article/details/94596341
我们的目标网址是
http://quotes.money.163.com/trade/lsjysj_股票代码.html
股票代码的来源就是上个爬虫存到mongodb里面的股票列表
先在terminal中新建项目:
scrapy startproject stock_history
同样将项目在pycharm中打开,

首先编辑stock_history_spider.py
第一步,初始化的时候连接上MONGODB,并取出列表。
class StockHistorySpider(scrapy.Spider):
collection = 'stock_list'
name = 'stock_history_spider'
headers = {
'Referer': 'http://quotes.money.163.com/',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'
}
def __init__(self):
scrapy.Spider.__init__(self) # 必须显式调用父类的init
self.log(sys.getdefaultencoding())
self.current_stock_code = ''
self.mongo_url = MONGO_URI
self.mongo_db = MONGO_DB
self.client = MongoClient(self.mongo_url)
self.db = self.client[self.mongo_db]
self.stock_list = self.db[self.collection].find({}, {'stock_id': 1, '_id': 0})
# 取出股票列表
{'stock_id': 1, '_id': 0} #表示只取‘stock_id'这一列,‘_id'默认显示的,需要手动置为0
下面拼接地址,请求第一个页面:
页面如下:

代码如下:
def start_requests(self):
# 根据股票代码拼接URL打开页面
# this is for test
# url = 'http://quotes.money.163.com/trade/lsjysj_601398.html'
# self.current_stock_code = '601398'
# yield scrapy.Request(url=url, headers=self.headers, callback=self.parse)
for stock_code in list(self.stock_list):
# self.log(stock_code.get('stock_id'))
self.current_stock_code = str(stock_code.get('stock_id'))
url = 'http://quotes.money.163.com/trade/lsjysj_{}.html'.format(self.current_stock_code)
yield scrapy.Request(url=url, headers=self.headers, callback=self.parse)
可以发现我们获取到默认的开始日期和结束日期之后就可以点击下载,下载对应的csv文件
在开发者模式下切到network页签,点击下载,就可以看到这里有个文件,出现,右键复制地址,这个就是下载文件的时候需要请求的地址。

下面我们获取开始结束日期,并且拼接下载文件的地址
def parse(self, response):
# 解析response中的开始日期和结束日期
text = response.text
soup = bs(text, 'lxml')
start_time = soup.find('input', {'name': 'date_start_type'}).get('value').replace('-', '') # 获取起始时间
# self.log('start_time % s' % start_time)
end_time = soup.find('input', {'name': 'date_end_type'}).get('value').replace('-', '') # 获取结束时间
# self.log('end_time %s' % end_time)
time.sleep(random.choice([1, 2]))
# self.log('start link')
# self.log('stock_code %s' % self.current_stock_code)
file_item = StockHistoryFileItem()
if len(self.current_stock_code) > 0:
stock_code_a = str(self.current_stock_code)
# 由于东方财富网上获取的代码一部分为基金,无法获取数据,故将基金剔除掉。
# 沪市股票以6,9开头,深市以0,2,3开头,但是部分基金也是2开头,201/202/203/204这些也是基金
# 另外获取data的网址股票代码 沪市前加0, 深市前加1
if int(stock_code_a[0]) in [0, 2, 3, 6, 9]:
if int(stock_code_a[0]) in [6, 9]:
new_stock_code = '0' + stock_code_a
if int(stock_code_a[0]) in [0, 2, 3]:
if not int(stock_code_a[0:3]) in [201, 202, 203, 204]:
new_stock_code = '1' + stock_code_a
logging.debug('new_stock_code = %s' % new_stock_code)
download_url = "http://quotes.money.163.com/service/chddata.html?code={}&start={}&end={}&fields=TCLOSE;HIGH;LOW;TOPEN;LCLOSE;CHG;PCHG;TURNOVER;VOTURNOVER;VATURNOVER;TCAP;MCAP".format(new_stock_code, start_time, end_time)
file_item['file_urls'] = [download_url]
yield file_item
下载文件使用scrapy自带的filepipeline
首先修改settings.py如下:
MONGO_URI = '127.0.0.1:27017' # mongodb的设置
MONGO_DB = 'stock' # 数据库
# 下载中间件
ITEM_PIPELINES={
'scrapy.pipelines.images.ImagesPipeline': 1,
'stock_history.pipelines.SelfDefineFilePipline': 2,
}
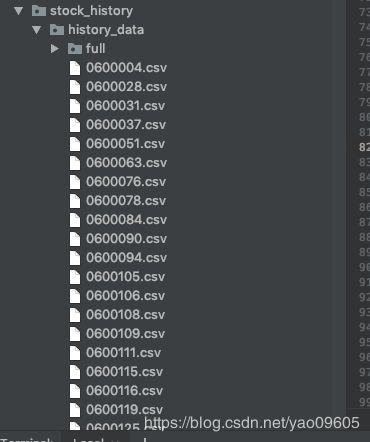
FILES_STORE = 'stock_history/history_data'
在items.py中添加如下代码:
import scrapy
class StockHistoryFileItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
file_urls = scrapy.Field()
files = scrapy.Field()
file_urls 用于作为下载地址的队列
files是下载文件进入的队列
名字不能改变
默认的下载文件的名字是一个HASH值,想要自定义下载的文件名,需要重新定义file_pathself, request, response=None, info=None)这个函数,return值就是文件名
我们在pipelines.py中添加如下代码:
from scrapy.pipelines.files import FilesPipeline
class SelfDefineFilePipline(FilesPipeline):
"""
继承FilesPipeline,更改其存储文件的方式
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def file_path(self, request, response=None, info=None):
str_temp = str(request.url)
name = str_temp[54:61]
name = name + '.csv'
return name
然后在terminal中 (报错no module 的话见上一个项目)
scrapy crawl stock_history_spider
然后保持网络畅通就可以去喝茶了。
等你过半小时回来你的文件夹中就躺着你要的文件了