MaxCompute数据开发快速入门
MaxCompute数据开发快速入门
该快速入门演示一个使用MaxCompute对银行贷款购房人员进行分析的完整过程。包含如下步骤:
- 创建并查看表
- 导入数据
- 运行SQL并导出数据
- 编写MapReduce
在进行该部分内容前,需要完成:MaxCompute基础开发环境搭建 。命令的运行可以选用odpscmd客户端,也可以使用IDEA MaxCompute Studio(该工具的使用见:MaxCompute Studio数据开发工具的使用),这里使用MaxCompute Studio进行命令的运行。该部分内容参考自:MaxCompute快速入门文档。
创建并查看表
创建表
1. 在MaxCompute Studio中创建odps sql的运行脚本文件:quickly_start.osql。
2. 创建需要的表bank_data和表result_table。bank_data用于存储业务数据,result_table用于存储数据分析后产生的结果。
表创建的命令格式为:
CREATE TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)]
[LIFECYCLE days]
[AS select_statement]使用如下命令创建bank_data数据表,并执行:
-- create bank_data table using SQL
CREATE TABLE IF NOT EXISTS bank_data
(
age BIGINT COMMENT '年龄',
job STRING COMMENT '工作类型',
marital STRING COMMENT '婚否',
education STRING COMMENT '教育程度',
default STRING COMMENT '是否有信用卡',
housing STRING COMMENT '房贷',
loan STRING COMMENT '贷款',
contact STRING COMMENT '联系途径',
month STRING COMMENT '月份',
day_of_week STRING COMMENT '星期几',
duration STRING COMMENT '持续时间',
campaign BIGINT COMMENT '本次活动联系的次数',
pdays DOUBLE COMMENT '与上一次联系的时间间隔',
previous DOUBLE COMMENT '之前与客户联系的次数',
poutcome STRING COMMENT '之前市场活动的结果',
emp_var_rate DOUBLE COMMENT '就业变化速率',
cons_price_idx DOUBLE COMMENT '消费者物价指数',
cons_conf_idx DOUBLE COMMENT '消费者信心指数',
euribor3m DOUBLE COMMENT '欧元存款利率',
nr_employed DOUBLE COMMENT '职工人数',
y BIGINT COMMENT '是否有定期存款'
);
根据如下命令创建result_table数据表,并执行:
-- create result_table using SQL
CREATE TABLE IF NOT EXISTS result_table
(
education STRING COMMENT '教育程度',
num BIGINT COMMENT '人数'
);查看表
创建完成后可以查看bank_data数据表的描述信息:
-- show table describtion
desc bank_data;
-- 返回结果如下
+------------------------------------------------------------------------------------+
| Owner: [email protected] | Project: yitian_bj_mc |
| TableComment: |
+------------------------------------------------------------------------------------+
| CreateTime: 2019-11-03 11:52:08 |
| LastDDLTime: 2019-11-03 11:52:08 |
| LastModifiedTime: 2019-11-03 11:57:20 |
+------------------------------------------------------------------------------------+
| InternalTable: YES | Size: 716920 |
+------------------------------------------------------------------------------------+
| Native Columns: |
+------------------------------------------------------------------------------------+
| Field | Type | Label | Comment |
+------------------------------------------------------------------------------------+
| age | bigint | | 年龄 |
| job | string | | 工作类型 |
| marital | string | | 婚否 |
| education | string | | 教育程度 |
| default | string | | 是否有信用卡 |
| housing | string | | 房贷 |
| loan | string | | 贷款 |
| contact | string | | 联系途径 |
| month | string | | 月份 |
| day_of_week | string | | 星期几 |
| duration | string | | 持续时间 |
| campaign | bigint | | 本次活动联系的次数 |
| pdays | double | | 与上一次联系的时间间隔 |
| previous | double | | 之前与客户联系的次数 |
| poutcome | string | | 之前市场活动的结果 |
| emp_var_rate | double | | 就业变化速率 |
| cons_price_idx | double | | 消费者物价指数 |
| cons_conf_idx | double | | 消费者信心指数 |
| euribor3m | double | | 欧元存款利率 |
| nr_employed | double | | 职工人数 |
| y | bigint | | 是否有定期存款 |
+------------------------------------------------------------------------------------+其他表操作
1. 删除表
-- drop table from sever
DROP TABLE IF EXISTS bank_data;2. 创建表分区
上述bank_data表创建时不是分区表,创建完成后可以对该表添加分区。例如这里针对married列(married=married)进行分区命令如下:
-- create partition for bank_table
alter table table_name add if not exists
partition(marital = "married");
-- desc
3. 删除表分区
-- drop partition for table
alter table bank_data drop if exists
partition(marital='married');导入数据
MaxCompute提供多种数据导入导出方式,这里主要在客户端上使用Tunnel命令操作进行数据导入,以及使用MaxCompute Studio进行数据导入。
这里使用的数据为banking.txt,主要用于记录各人员的年龄、工作、房贷等信息,选取其中前三条数据展示如下:
44,blue-collar,married,basic.4y,unknown,yes,no,cellular,aug,thu,210,1,999,0,nonexistent,1.4,93.444,-36.1,4.963,5228.1,0
53,technician,married,unknown,no,no,no,cellular,nov,fri,138,1,999,0,nonexistent,-0.1,93.2,-42,4.021,5195.8,0
28,management,single,university.degree,no,yes,no,cellular,jun,thu,339,3,6,2,success,-1.7,94.055,-39.8,0.729,4991.6,1Tunnel导入数据
1. 下载banking.txt数据文件到:/Users/yitian/Documents/MaxCompute/documents/learning-data/banking.txt下。
2. 使用如下tunnel命令导入数据到数据表:
odps@ YITIAN_BJ_MC>tunnel upload /Users/yitian/Documents/MaxCompute/documents/learning-data/banking.txt bank_data;
Upload session: 202004161541180b47df0b15eaa54c
Start upload:/Users/yitian/Documents/MaxCompute/documents/learning-data/banking.txt
Using \n to split records
Upload in strict schema mode: true
Total bytes:4841548 Split input to 1 blocks
2020-04-16 15:41:18 scan block: '1'
2020-04-16 15:41:18 scan block complete, block id: 1
2020-04-16 15:41:18 upload block: '1'
2020-04-16 15:41:20 Block info: 1:0:4841548:/Users/yitian/Documents/MaxCompute/documents/learning-data/banking.txt, progress: 100%, bs: 4.6 MB, speed: 4.6 MB/s
2020-04-16 15:41:20 upload block complete, block id: 1
upload complete, average speed is 1.5 MB/s
OK
3. 查看导入结果,导入完成后存在了41188条数据记录:
odps@ YITIAN_BJ_MC>select count(*) from bank_data;
...
+------------+
| _c0 |
+------------+
| 41188 |
+------------+
MaxCompute Studio导入数据
MaxCompute Studio提供了可视化的数据导入工具,使用过程如下:
1. 打开数据导入页面:
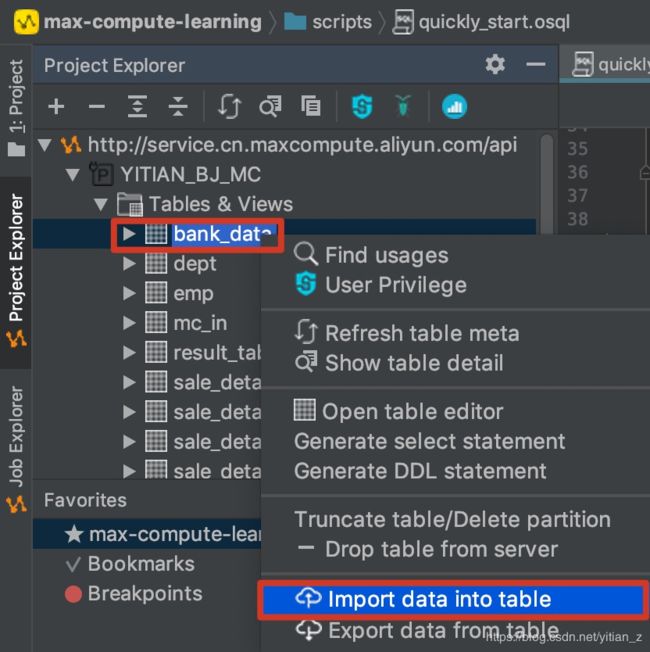
2. 导入页面如下:
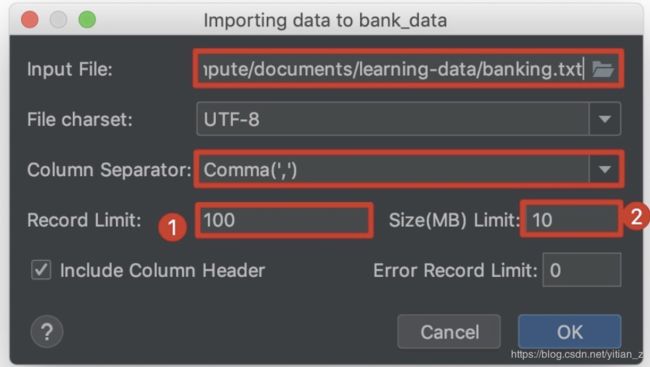
选择本地的banking.txt文件作为Input File。需要注意的是:
- Record Limit默认为100,如果不修改,那么导入的数据就只有100条。
- Size也是对导入数据容量的限制,这里根据banking.txt文件的大小进行相应的修改。
3. 导入完成后,除了试用select语句对导入的数据进行查看外,也可以使用MaxCompute Studio中的可视化数据展示:
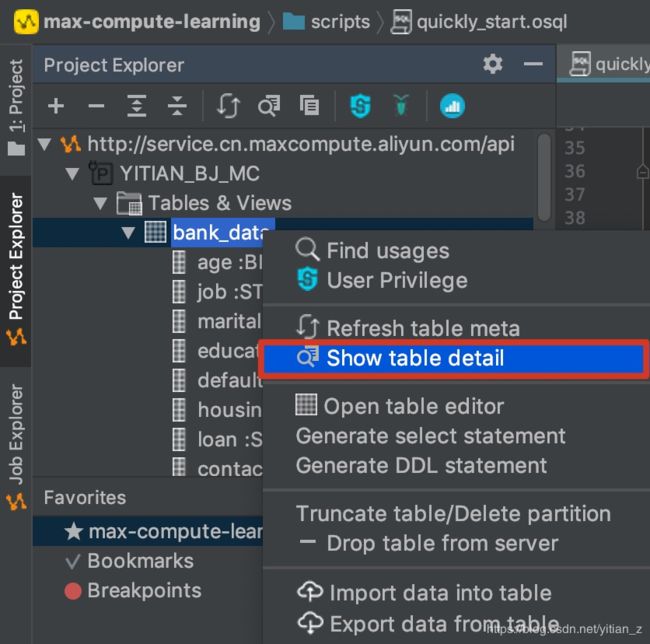
在打开的页面的下方,选择Data Preview进行数据查看,同时可以选择查看的数据条数:
运行SQL并导出数据
关于使用MaxCompute进行数据处理的一些说明:
- MaxCompute SQL不支持事务、索引、UPDATE以及DELETE等操作,同时MaxCompute的SQL语法与Oracle、MySQL有一定差别。
- MaxCompute上作业提交后会有几十秒到数分钟不等的排队调度,所以MaxCompute适合一次批量处理海量数据的跑批作业,不适合直接对接需要每秒处理几千至数万笔事务的前台业务系统。
这里使用一个简单是数据统计进行数据的处理,并导出处理的结果。
提取和分析数据
查询不同学历的单身人士贷款买房的数量,并将结果保存到result_table中。
1. 使用如下语句将表bank_data中不同学历单身贷款买房人士的数量保存至表result_table中。
INSERT OVERWRITE TABLE result_table
SELECT education,COUNT(marital) AS num
FROM bank_data
WHERE housing = 'yes'
AND marital = 'single'
GROUP BY education;2. 使用如下语句查看result_table表中的数据。
SELECT * FROM result_table;得到的结果如下:
education num
+----------+----+
basic.4y 227
basic.6y 172
basic.9y 709
high.school 1641
illiterate 1
professional.course 785
university.degree 2399
unknown 257导出数据
使用tunnel导出数据
1. 使用如下语句将表result_table中数据导出到本地/Users/yitian/Documents/MaxCompute/documents/learning-data/目标,保存成名为result.txt的文件。
tunnel download result_table /Users/yitian/Documents/MaxCompute/documents/learning-data/result.txt;其中,result_table为需要导出的表,/Users/yitian/Documents/MaxCompute/documents/learning-data/result.txt为导出后保存的路径及名称。
2. 导出完成后,查看该本地路径,可以得到导出的结果文件:

使用MaxCompute Studio导出数据
同样可以使用MaxCompute Studio导出result_table表中的数据。
1. 打开数据导出界面:
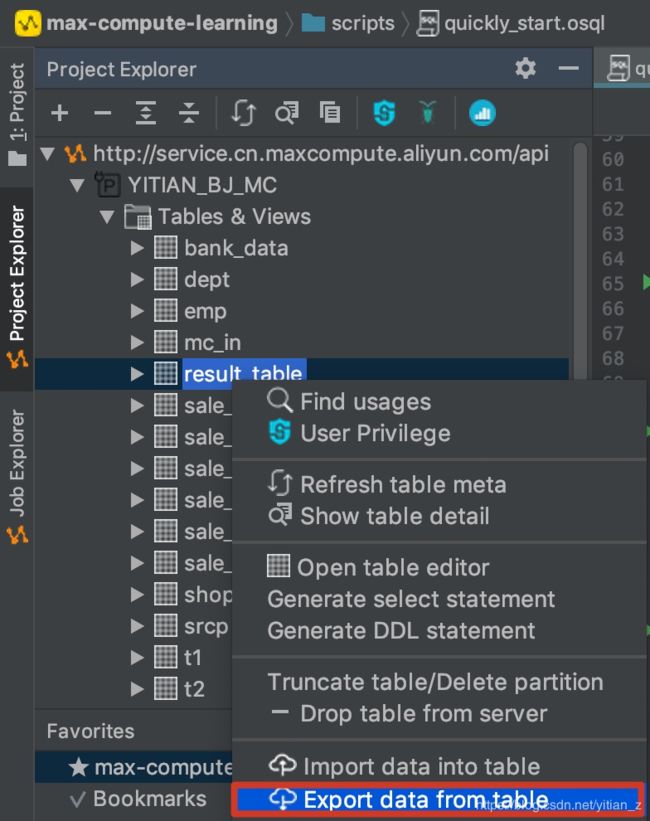
2. 选择导出的目标,进行数据导出:
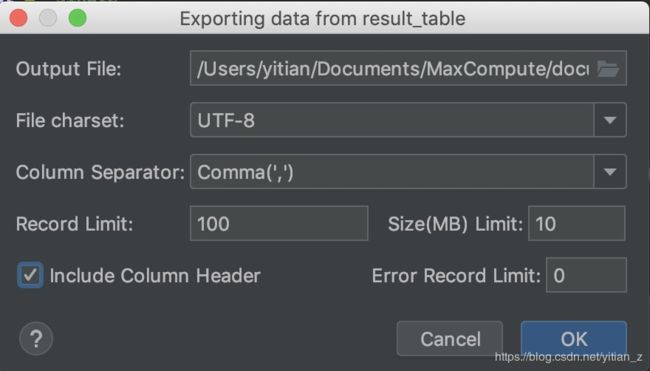
3. 导出结果为:

编写MapReduce
由于当前使用的MaxCompute服务为按量计费开发者版。按量计费开发者版资源,仅支持MaxCompute SQL(支持使用UDF)、PyODPS作业任务,暂不支持MapReduce、Spark等其它任务。
因此暂时无法使用MapReduce的开发功能,具体的开发内容见:MaxCompute快速入门-编写MapReduce(可选)。
开发Java UDF
MaxCompute支持多种UDF:
| UDF 分类 | 描述 |
|---|---|
| UDF(User Defined Scalar Function) | 用户自定义标量值函数(User Defined Scalar Function)。其输入与输出是一对一的关系,即读入一行数据,写一条输出值 。 |
| UDTF(User Defined Table Valued Function) | 自定义表值函数。用来解决一次函数调用输出多行数据场景。它是唯一能够返回多个字段的自定义函数。UDTF不等于UDT(User Defined Type)。 |
| UDAF(User Defined Aggregation Function) | 自定义聚合函数。其输入与输出是多对一的关系, 即将多条输入记录聚合成一条输出值。它可以与SQL中的GROUP BY语句联用。具体语法请参见聚合函数 |
下面通过MaxCompute Studio开发字符小写转换功能的UDF步骤如下:
1. 准备工具环境并创建Java Module。在使用MaxCompute Studio创建的max-compute-learning项目中,创建Java Moudle:
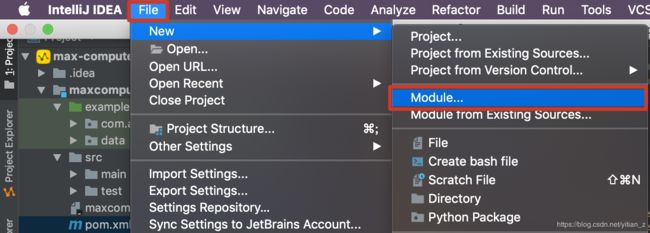
在打开的创建选项中,选择MaxCompute Java选项:
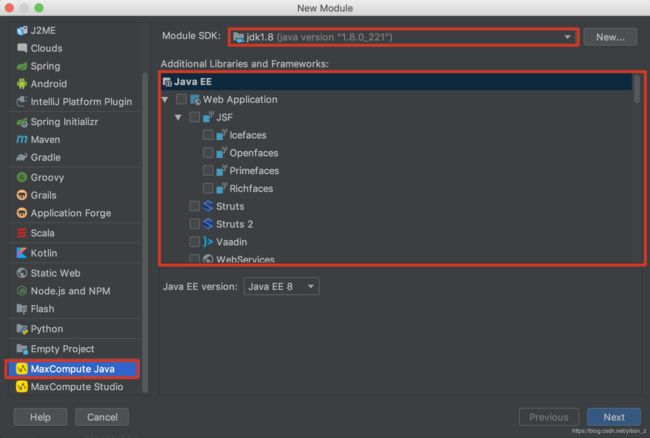
Additional Libraries中可以不选择其他的libraries,保持默认即可。然后输入需要创建的Module Name,创建完成后得到的项目目录如下:
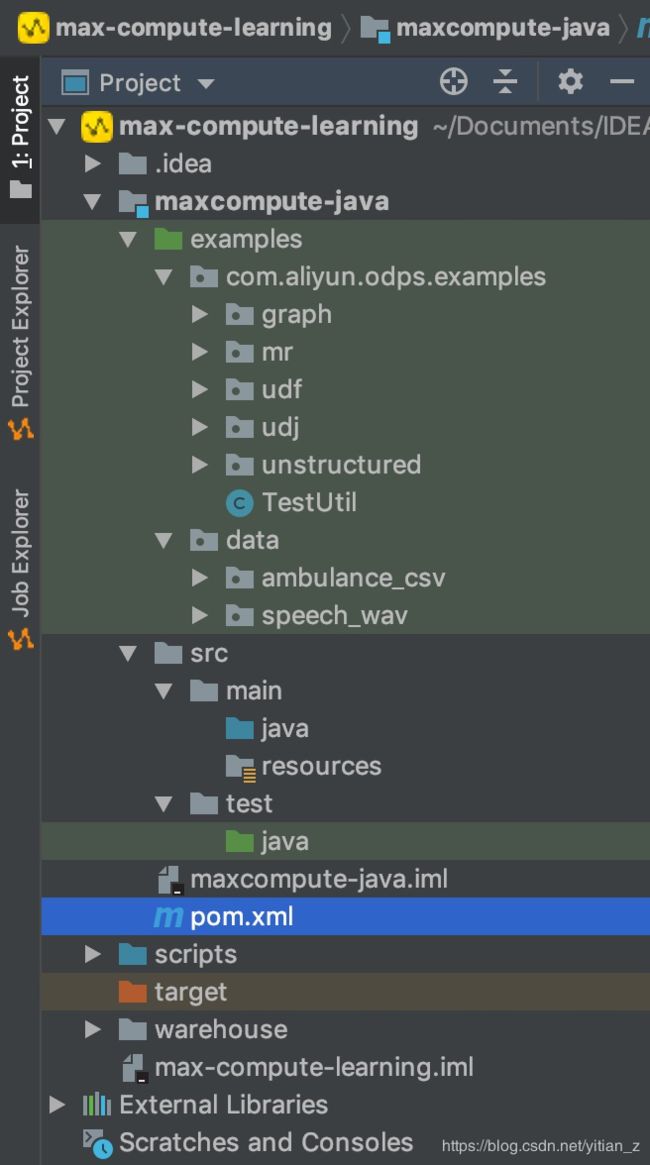
Moudle的pom.xml文件中会自动加入odps-sdk-udf的相关依赖:
2. 创建以上java module之后,就可以创建UDF:
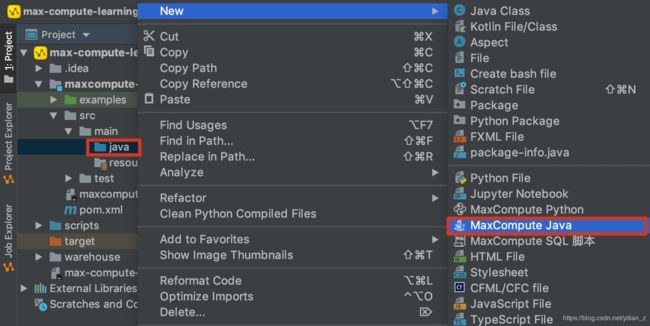
在出现的创建文件的窗口中,选择文件类型为UDF:

3. 创建完成后,编辑UDF代码:
package yitian.odps.udf;
import com.aliyun.odps.udf.UDF;
public class LowerUDF extends UDF {
// TODO define parameters and return type, e.g: public String evaluate(String a, String b)
public String evaluate(String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}4. 注册MaxCompute UDF。右键单击UDF的Java文件,选择Deploy to server...,在Package a jar, sunmit resource and register function弹框中配置参数。配置完成,单击OK即可。
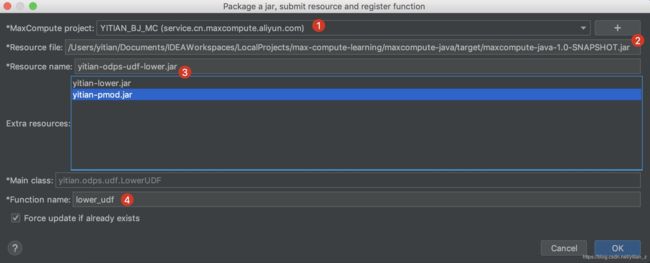
需要配置的参数如下:
- MaxCompute project:UDF所在的MaxCompute Project名称。
- Resource file:选择Jar包路径。
- Resource name:输入注册的资源名。
- Function name:注册的函数名称。(UDF在上传之后,只用该名称进行使用)
5. 执行完成上面的deploy to server过程后,可以在MaxCompute Studio中看到这里上传的资源:
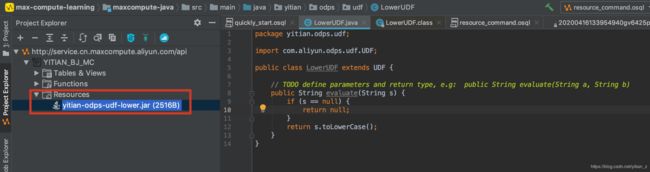
6. 打包并上传完成后,只是在resource中添加了包含了我们定义的UDF文件,在Functions中还没有创建对应的UDF。因此需要根据上传的资源文件来创建我们需要使用的UDF。首先在菜单栏选择:

在显示的窗口中进行设置:
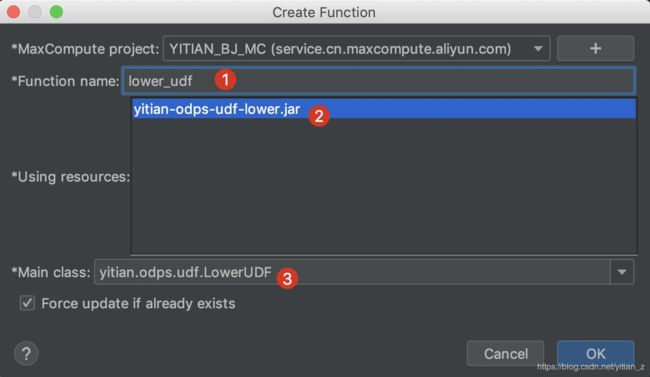
点击确定即根据上传的resource创建名为lower_udf的UDF。此时可以在Functions选项中进行查看创建完成的UDF:
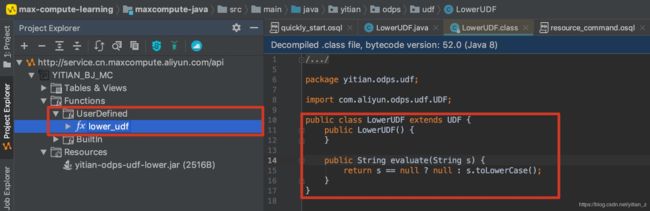
7. 使用UDF。完成上面的操作后,可以使用刚才创建的名为lower_udf的function来使用上传的UDF。在MaxCompute SQL Script中运行如下命令:
select lower_udf('ABC');运行成功后,得到的输出结果如下:
_c0
+----+
abc