【推荐系统】【论文阅读笔记】Deep content-based music recommendation
原文作者:A¨aronvandenOord,SanderDieleman,BenjaminSchrauwen
本文为了解决协同过滤导致的冷启动问题,使用基于内容推荐算法,建议使用潜在因素模型进行推荐,并在无法从可获取数据中获取潜在因素时从音乐音频中预测潜在因素。我们比较了使用深度卷积神经网络和使用词袋表示音频信号的传统方法,并在“百万首歌曲”数据集上定量和定性地评估了预测。我们展示了使用预测的潜在因素会产生明智的建议,尽管事实上,影响用户偏好的歌曲特征与相应的音频信号之间存在很大的语义差距。并且本文表明深度学习的最新进展很好地转化为音乐推荐设置,深度卷积神经网络的性能明显优于传统方法。
1.音乐中的语义鸿沟(semantic gap)
(基于模型的协同过滤法中)潜在因子向量构成了用户品味的不同方面以及商品的相应特征的紧凑描述。由于许多歌曲缺少使用数据,因此通常无法可靠地估计这些因子向量。因此,我们也需要能够根据音乐音频内容预测它们。
影响用户偏好的歌曲特征与相应的音频信号之间存在较大的语义差距。从音频信号中提取诸如流派,语气,乐器和抒情主题等高级属性需要强大的模型,这些模型必须能够捕获音乐的复杂层次结构。而且 ,仅从音频信号也无法获得某些属性,例如艺术家的知名度,声誉和位置。
在本文中,将通过训练深度卷积神经网络来预测音乐音频中的潜在因素,努力弥合音乐中的语义鸿沟。 我们在具有超过380,000首歌曲的音频摘录的工业规模数据集上评估了我们的方法,并将其与更常规的方法(使用每首歌曲的词袋特征表示法)进行比较。 我们评估在何种程度上可以直接从音频信号中提取影响用户偏好的特征,并在音乐推荐设置中评估我们模型的预测。
2.实验的数据集
使用the taste profile subset
• The Echo Nest Taste Profile Subset提供了来自100万用户的MSD中超过380,000首歌曲的播放计数。
•Last.fm数据集提供了超过500,000首歌曲的标签。
3.加权矩阵分解(WMF weight matrix factorization)
The Taste Profile Subset包含每首歌曲和每位用户的播放计数,这是隐式反馈的一种形式。我们知道用户听过数据集中的每首歌曲的次数,但是他们还没有对他们明确评分。但是,我们可以假设用户喜欢的话可能会更常听歌。如果用户从未听过歌曲,则可能有很多原因:例如,他们可能不知道这首歌,或者他们可能不喜欢它。此设置与旨在预测评分的传统矩阵分解算法不兼容。我们使用了Hu等人提出的加权矩阵分解(WMF)算法。 以学习The Taste Profile Subset中所有用户和项目的潜在因子表示。这是针对隐式反馈数据集的改进矩阵分解算法。假设r ui是用户u和歌曲i的播放计数。对于每个用户项对,我们定义一个偏好变量p ui和一个置信度变量c ui(I(x)是指标函数,α和∈是超参数):

偏好变量p指示用户u是否曾经听过歌曲i。 如果为1,我们将假定用户喜欢这首歌。 置信度变量c衡量我们对这种特殊偏好的确定性。 这是播放次数的函数,因为具有较高播放次数的歌曲更可能被优先选择。 如果从未播放过歌曲,则置信度变量将具有较低的值,因为这是信息最少的情况。
WMF目标函数为:
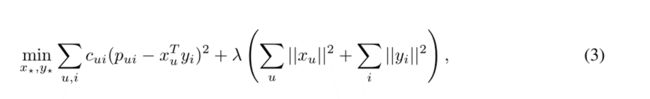
其中λ是正则化参数,Xu是用户u的潜在因子向量,yi是歌曲i的潜在因子向量。 它由置信加权均方误差项和L2正则化项组成。 请注意,第一个总和的范围覆盖所有用户和所有歌曲:与用于评分预测的矩阵分解相反,在该方法中,可以丢弃与没有评分可用的用户项组合相对应的术语,我们必须考虑所有可能的组合。 结果,对于这种大小的数据集,使用随机梯度下降进行优化是不切实际的。 Hu等提出了一种有效的交替最小二乘(ALS)优化方法,我们改用了该方法。
4.从音乐音频中预测潜在因素
从相应的音频信号 预测 给定歌曲的潜在因素是一个回归问题。 它需要学习将时间序列映射到实数向量的函数。 我们评估了实现此目的的两种方法:一种是遵循MIR中的常规方法,通过从音频信号中提取局部特征并将其聚集为词袋(BoW)表示。 然后,可以使用任何传统的回归技术将此特征表示映射到因子。 另一种方法是使用深层卷积网络,将通过将WMF(加权矩阵分解)应用于可用使用数据而获得的潜在因子矢量用作基本事实来训练预测模型。 应该注意的是,该方法与适用于大型隐式反馈数据集的任何类型的潜在因子模型兼容。 我们选择使用WMF是因为存在有效的优化程序。
4.1词袋表示(BoW)
许多MIR系统都依赖以下特征提取管道将音乐音频信号转换为固定大小的表示形式,可以用作分类器或回归器的输入:
•从音频信号中提取MFCC(梅尔倒谱系数)。 我们从1024个音频帧的窗口中计算出13个MFCC,对应于23ms(以22050 Hz的采样率)和512个样本的跳数。 我们还计算了一阶和二阶差,总共得出39个系数。
•向量量化MFCC。 我们使用K-means算法学习了4000个元素的字典,并将所有MFCC向量分配给最接近的mean。
•将它们汇总成一个单词袋表示。 对于每首歌曲,我们计算每个mean被选中的次数。 所得的计数向量是歌曲的词袋特征表示。
然后,我们使用PCA减小了表示的大小(我们保留了足够的分量以保留95%的方差),并使用线性回归和具有1000个隐藏单位的多层感知器来预测潜在因素。 我们还使用它作为度量学习排名(MLR)算法的输入,以学习基于内容的推荐的相似性度量。 这被用作我们的音乐推荐实验的基准
4.2卷积神经网络
卷积神经网络(CNN)最近已被用于改善语音识别和大规模图像分类的最新技术水平。 以下三种因素是该方法成功的关键:
•使用修正线性单位(ReLU)代替S形非线性可加快收敛速度,并减少困扰传统神经网络多层的消失梯度问题。
•并行化用于加快训练速度,以便可以在合理的时间内训练更大的模型。 我们使用Theano库来利用GPU加速。
•需要大量的训练数据才能适合具有许多参数的大型模型。MSD(The Million Song Dataset)包含足够的训练数据才能有效地训练大型模型。
我们首先从音频信号中提取了一个中间时频表示,以用作网络输入。 我们使用具有128个成分的对数压缩梅尔频谱图,并且窗口大小和跳大小与MFCC(梅尔频率倒谱系数)所用的窗口大小和跳数相同(分别为1024和512音频帧)。 在从音频剪辑中随机采样的3秒窗口中训练了网络。 这样做主要是为了加快培训速度。 为了预测整个片段的潜在因素,我们对连续窗口的预测取平均值。
卷积神经网络特别适合于从音乐音频中预测潜在因素,因为它们允许中间特征在不同因素之间共享,并且由于它们的层次结构由交替的特征提取层和池化层组成,因此它们可以在多个时标上运行。
4.3目标函数

潜在因子向量是实值,因此最直接的目标是最小化预测的均方误差(MSE)。 或者,我们也可以继续从WMF目标函数中最小化加权预测误差(WPE)。 假设yi是用WMF获得的歌曲i的潜在因子向量,而y′i是模型的相应预测。