pacemaker+corosync实现集群管理
前言:
高可用集群,是指以减少服务中断(如因服务器宕机等引起的服务中断)时间为目的的服务器集群技术。简单的说,集群就是一组计算机,它们作为一个整体向用户提供一组网络资源。这些单个的计算机系统就是集群的节点。
高可用集群的出现是为了减少由计算机硬件和软件易错性所带来的损失。它通过保护用户的业务程序对外不间断提供的服务,把因软件/硬件/人为造成的故障对业务的影响降低到最小程度。
什么是pacemaker :
Pacemaker是一个集群资源管理器。它利用集群基础构件(OpenAIS 、heartbeat或corosync)提供的消息和成员管理能力来探测并从节点或资源级别的故障中恢复,以实现群集服务(亦称资源)的最大可用性。
Corosync
Corosync是集群管理套件的一部分,他在传递信息的时候可以通过一个简单的配置文件来定义信息传递的方式和协议等。也就是说,corosync是Messaging Layer集群信息层软件,需要pacemaker资源管理器,才能构成一个完整的高可用集群。它也是运行于心跳层的开源软件。(是集群框架引擎程序)
实验搭建:
准备三台7.3的虚拟机
server1:ip为172.25.5.111 作为管理节点和HA节点
server2:ip为172.25.5.112 作为HA节点
server3:ip为172.25.5.113 作为iscsi共享磁盘
三台虚拟机关火墙,selinux状态disabled,
首先需要配好高可用yum源(server1和server2):
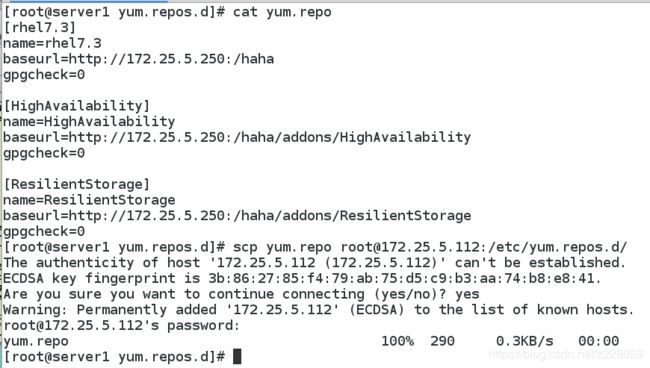

yum源配好之后安装工具(一和二都装)
yum install pacemaker pcs corosync -y
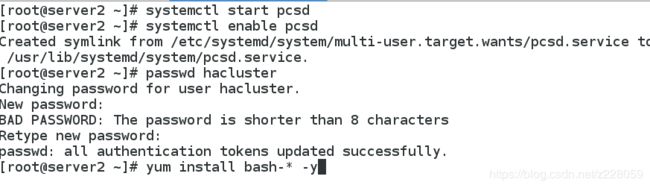
systemctl start pcsd
systemctl enable pcsd
passwd hacluster 为高可用用户设定密码
yum install bash-* -y 安装pcs相关命令
因为官方规定为了安全起见要生成ssh密钥,给自己和server2发送一份
server2重复相同操作
ssh-keygen
ssh-copy-id server1
ssh-copy-id server2
发送不了你看下自己的解析写好没:

在server1上
pcs cluster auth server1 server2
pcs cluster setup --name mycluster server1 server2
pcs cluster start --all
pcs cluster enable --all
pcs status
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
crm_verify -L
pcs resource list
pcs resource standards
在server1和server2上安装httpd,并写入网页

在server1上创建vip:
pcs resource create vip ocf:heartbeat:IPaddr2 ip=172.25.5.100 cidr_netmask=32 op monitor interval=30s
在server2上查看
crm_mon
测试:
pcs cluster stop server1
crm_mon
pcs cluster start server1
在sever1上添加httpd资源和组
pcs resource create apache systemd:httpd op monitor interval=1min
pcs resource group add apache_group vip apache
crm_mon
pcs constraint order vip then apache
添加fence栅设备
在server1、server2和物理机上分别安装fence
yum install fence-virt -y
mkdir /etc/cluster
在物理机上
fence_virtd -c ##配置fence
Interface [virbr0]: br0 ##设备选择br0,其他用默认
生成fence_xvm.key
mkdir /etc/cluster
dd if=/dev/urandom of=/etc/cluster/fence_xvm.key bs=128 count=1
把fence_xvm.key分发到HA节点,通过这个key来管理节点
scp fence_xvm.key root@server1:/etc/cluster/
scp fence_xvm.key root@server2:/etc/cluster/
systemctl start fence_virtd.service
在server1上识别并添加fence
注意:server1(主机名):server1(虚拟机名)
stonith_admin -I
pcs stonith create vmfence fenxe_xvm pcmk_host_map="server1:server1;server2:server2" op monitor interval=1min
测试:
写坏server2的内核,通过fence重启
pcs property set stonith-enabled=true
echo c >/proc/sysrq-trigger
添加iscsi网络共享磁盘
server3作为共享磁盘
为server3添加一块20G的虚拟磁盘
fdisk /dev/vda 建个分区
partprobe
安装共享磁盘服务并设置
yum install targetcli -y
targetcli
/backstores/block create my_disk1 /dev/vda
iscsi/ create iqn.2019-06.com.example:server3
iscsi/iqn.2019-06.com.cc.example:server3:/tpg1/luns create /backstores/block/my_disk1
iscsi/iqn.2019-06.com.cc.example:server3/tpg1/acls create iqn.2019-06.com.example:client
exit
在server1和server2上安装iscsi
并编写文件
yum install iscsi-* -y
cat /etc/iscsi/initiatorname.iscsi
InitiatorName=iscsi/iqn.2019-06.com.cc.example:client
systemctl restart iscsid
识别并登陆共享磁盘
iscsiadm -m discovery -t st -p 172.25.5.113
iscsiadm -m node -l
partprobe
cat /proc/partitions
在共享磁盘上创建一个分区并格式化
fdisk /dev/sdb
mkfs.ext4 /dev/sdb1
partprobe
在server2同步并查看
partprobe
cat /proc/partitions
添加mysql数据库资源
在server1和server2上分别安装mariadb
yum install mariadb-* -y
sysemctl start mariadb
server1挂载到共享磁盘并登陆数据库
chown mysql.mysql /var/lib/mysql
mount /dev/sdb1 /var/lib/mysql
systemctl start mariadb
mysql -uroot
关闭server1的mariadb并在server2登陆数据库
server1 systemctl stop mariadb
server2 mount /dev/sdb1 /var/lib/mysql
systemctl start mariadb
mysql -uroot
测试完毕卸载并关闭mariadb
umount /var/lib/mysql
systemctl stop mariadb
删除之前创建的apache组
并创建新的vip和组
pcs resource delete apache_group
pcs resource create vip1 ocf:heartbeat:IPaddr2 ip=172.25.11.200 cidr_netmask=32 op monitor interval=30s
pcs resource create mysql_data ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/var/lib/mysql fstype=xfs op monitor interval=30s
df
crm_mon
pcs resource create mariadb systemd:mariadb op monitor interval=1min
pcs resource group add mysql_group vip1 mariadb
crm_mon
在server1登陆mysql测试
mysql -uroot
在server2把内核写崩测试fence
pcs property set stonith-enabled=true
echo c >/proc/sysrq-trigger
解决fence资源的bug
目的:写崩server2内核,在server2重启过程中,资源会回到server1上,当server2重启以后,资源也会一直在server1上
解决办法:
删除之前创建资源、组、fence
pcs resource delete mysql_group
pcs resource delete vmfence
pcs property set stonith-enabled=false
crm_verify -L -V
重新添加资源、组、fence
pcs resource create vip1 ocf:heartbeat:IPaddr2 ip=172.25.5.200 cidr_netmask=32 op monitor interval=30s
pcs resource create mysql_data ocf:heartbeat:Filesystem device=/dev/sdb1 directory=/var/lib/mysql fstype=xfs op monitor interval=30s
pcs resource create mariadb systemd:mariadb op monitor interval=1min
pcs resource group add mysql_group vip1 mariadb
更改resource-stickiness值
pcs resource defaults
pcs resource defaults resource-stickiness=100
pcs resource defaults
添加fence并再次更改resource-stickiness值
pcs stonith create vmfence fenxe_xvm pcmk_host_map="server1:server1;server2:server2" op monitor interval=1min
pcs resource defaults resource-stickiness=0
pcs resource defaults
pcs property set stonith-enabled=true
测试:
写崩server2内核,在server2重启过程中,资源会回到server1上,当server2重启以后,资源也会一直在server1上