Parallel Programming Platforms(并行编程平台)
串行计算机由处理器,内存,和数据通道组成。任何一部分都可以成为处理速度的瓶颈。多处理器,多内存,多数据通道是一种有效的解决方法。(多重性可以隐藏,也可以提供给程序员)。
在对代码并行化之前,要先优化串行代码的性能。
指令执行的五个阶段:取指令,解指令,执行指令,内存访问,写回
流水线(Pipelining): 流水线技术是一种将每条指令分解为多步,并让各步操作重叠,从而实现几条指令并行处理的技术。性能受限于最慢的一个阶段。
超流水线:就是将每个阶段再进行细分成更小的步骤,同样是细分后的每个阶 段,单个阶段的运算量小了,单位耗时s也就减少,这样实际上就是提高了时钟频率。这种将标准流水线细分的技术,就是超级流水线技术。当然,流水线和超级流 水线之间并没有很明显的区别。这对分支预测的要求很高,预测失败的代价大。
超标量:超标量(superscalar)是指在CPU中有一条以上的流水线,并且每时钟周期内可以完成一条以上的指令,这种设计就叫超标量技术。 其实质是以空间换取时间。
指令相关性:数据相关(等待上条指令结果),资源相关(用到同一个部件),分支相关
绝大多数处理器都支持乱序发送指令,这也叫做动态指令发送。
执行部件的浪费分为两种:水平浪费和垂直浪费。水平浪费是指同一时钟周期,不是所有执行部件都在使用,而垂直浪费是指由于CPU停顿,导致某个时钟周期中所有执行部件都没有在使用。
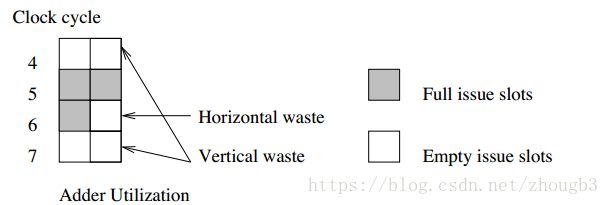
周期4和7是垂直浪费,因为两个部件都没有执行。周期6是水平浪费,因为只有一个部件在执行。周期0-3都是垂直浪费,所以整个利用率为3/8(8个周期,有三次计算)
超长指令字处理器(Very Long Instruction Word Processors)
使用与超标量处理器不同的方法,先绑定能够并发执行的指令,因此叫做超长指令。(硬件更加简单,依赖于编译器)
延迟:多少时间后能得到内存数据(使用高速缓存)。
带宽:能读到数据后,一秒能读到多少数据(在硬件条件不变的前提下,增大每次读取块的大小)(具有空间本地性,连续的计算需要有连续的数据)(时间本地性,读取的数据都是最近要用的,数据会在最近被重复使用)。
多线程和预取可以躲避内存延迟
多线程系统成为带宽的限制而不是延迟的限制。多线程和预取只是解决延迟问题,通常会导致带宽问题加剧。
并行平台的控制结构
单指令流多数据流(SIMD)单一控制部件向每个处理器分派相同指令。
多指令流多数据流(MIMD)每个处理器有自己的控制单元,每个处理器可以对不同的数据执行不同的指令。(每个处理器都能够独立于其他处理器执行不同的程序。需要在每个处理器上存取程序及安装操作系统)
SPMD:MIMD的一个变形,用一个程序的多个实例在不同数据上运行。
SIMD Processors (需要更少的硬件单元,但是设计成本更高)& MIMD Processors
并行平台的通信模型
Shared-Address-Space Platforms(共享地址空间平台)
支持SPMD编程的共享地址空间平台也称为多处理器(multiprocessors)
共享地址空间的内存可以是处理器独占的,也可以是全局的。
uniform memory access (UMA) multicomputer:访问系统中任何内存字的时间都相同(全局或本地)。
shared-address-space :无论是共享内存还是分布式内存,都可以有共享地址空间。
shared-memory computers :内存物理上被多个处理器共享。
Message-Passing Platforms(消息传递平台)
(Platforms that support messaging are also called message passing platforms or multicomputers)
多计算机间的交互必须用消息传递,因为没有共享地址空间。(可以用共享地址空间模拟)
理想并行计算机的体系结构
串行计算模型的扩展:p个处理器,大小不受限的全局内存。这种理想模型称为并行随机访问计算机(PRAM)
这种结构代价很大,如果有p个处理器m个字的全局内存,那么EREW需要O(mp)个锁。
并行计算机互联网络
提供多个处理节点之间(如消息传递平台)或处理器与内存模块之间的数据传输机制。分为动态和静态两种。互联网络由链路和开关组成。
静态网络称为直连网络,在处理器之间建立点到点的连接。
动态网络称为间接连接网络,中间由很多开关组成。
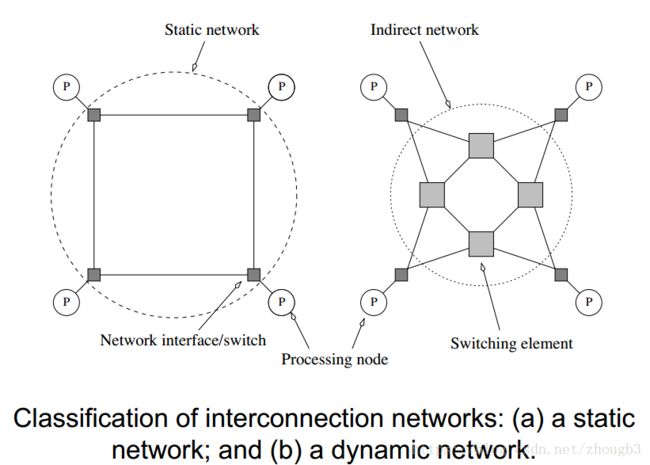
网络拓扑结构
基于总线的网络,交叉开关网络,多级网络(折中方案)

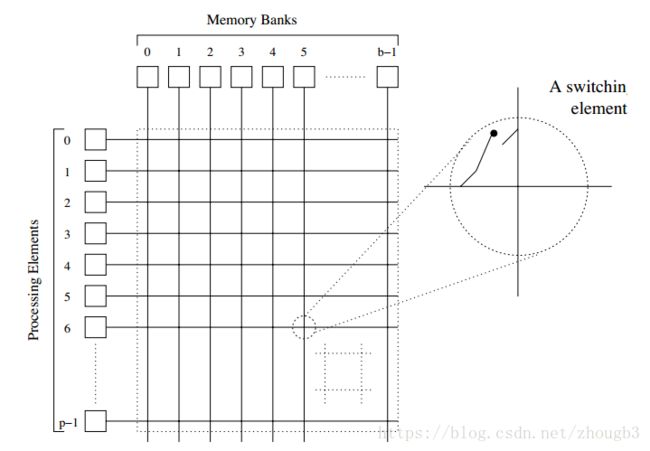
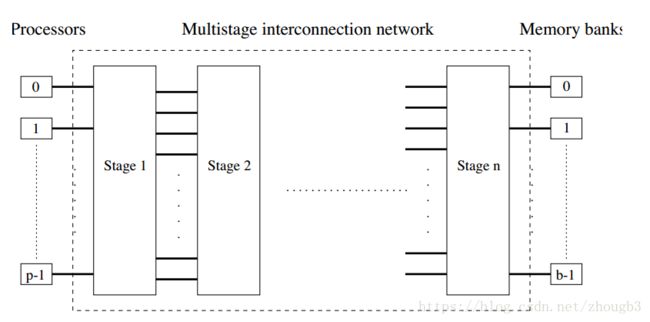
Omega是一种常用的多级互联网络,级数为logP,每一级的互联都是将二进制数左旋一位(将最左边的二进制位放于最右边)。这种互联模式称为完全混洗(perfect shuffle)。每一级的开关数有p/2个,所以一个开关有两个输入和两个输出。开关的输入和输出定义关系有直通式和跨接式。可能会阻塞。
直通式和跨接式的选择:设s为需要写数据到存储区t的处理器的二进制表示。数据穿过链路到达第一个开关节点。比较s和t的最高有效位,一致则采取直通式,不同则采取跨接式。到达第二个开关节点后比较s和t的第二个有效位,依次类推到达t存储区。
全连接网络:交叉开关网络的静态对应模型。任意对的通信不会阻塞其他对的通信。
星形连接网络:与基于总线的网络类似。
线性阵列:从一维推到二维(每一个维度有根号p个节点)推到三维(有回绕则是将首尾也连接起来)
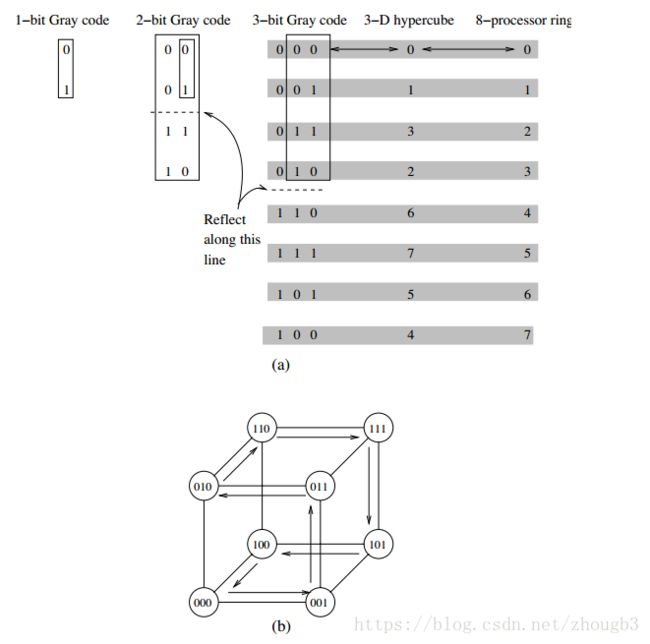
k-d格网:d维,每一维上有k个节点。超立方体是k-d格网的一个极端。有logp维,每个维度有两个节点。d维超立方体由连接两个(d-1)维的超立方体组成。在给节点编号时,通过将一个立方体的编号开头为0,另一个超立方体编号开头为1的方式,可以很容易的根据编号每一位是否相同得到他们之间的链路数目(0110和0101差两个链路)。
基于树的网络:有静态和动态的,动态的只有叶子节点是处理器。树网络中越往上的节点要处理更多的数据。在动态网络中,可以通过增加通信链路,以及增加更接近根节点的交换节点个数,来减少瓶颈。这种动态网络称为胖树。
直径(Diameter):任意两个节点之间的最长距离(距离定义为两个节点之间的最短路径)
连通性:将一个网络分为两个不连通网络需要删去的最小弧数目。
对分宽度(Bisection Width):把网络分为两个相同网络必须删去的最小通信链路数目。通道带宽是通道速度和通道宽度的乘积。
互联网络的评价:


多处理器当中的高速缓存一致性
当处理器修改变量的一个副本时必须发生两件事之一:
无效协议:使得其他的副本无效,这时候有处理器要读取该变量时必须从被修改的副本这里处取得(假共享:不同处理器更新相同高速缓存行中不同部分的情况。这样子无效协议会使得高速缓存行在不同处理器之间传来传去);
更新协议:其他的副本也更新(如果某个副本不再使用,这样会造成多余开销)。
当前的高速缓存一致性计算机通常依靠无效协议。
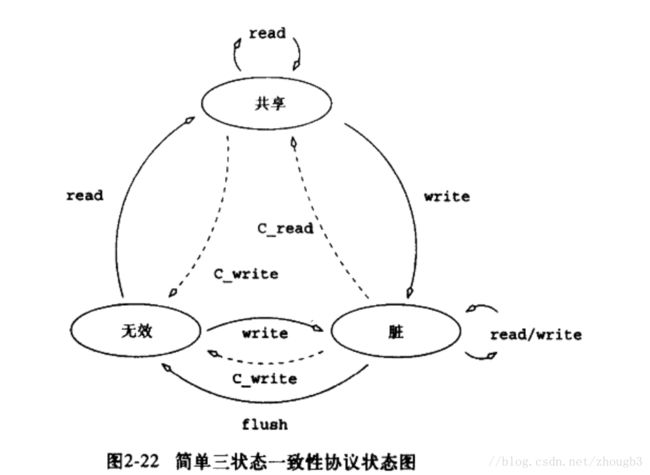
实线为处理器操作,虚线为一致性操作, C_write为一致性写 。
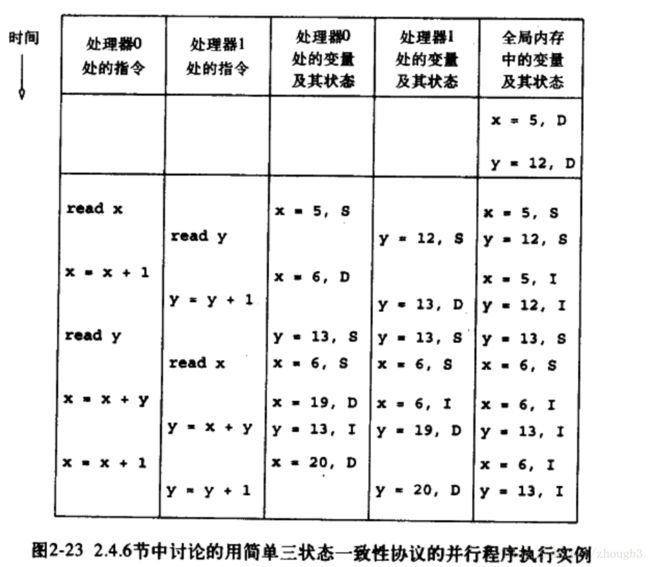
注意最后的x = x + y, y = x + y, 执行第二条时虽然x已经无效,但之前已经读过x了,所以还是拿的之前的值。
一致性协议的实现
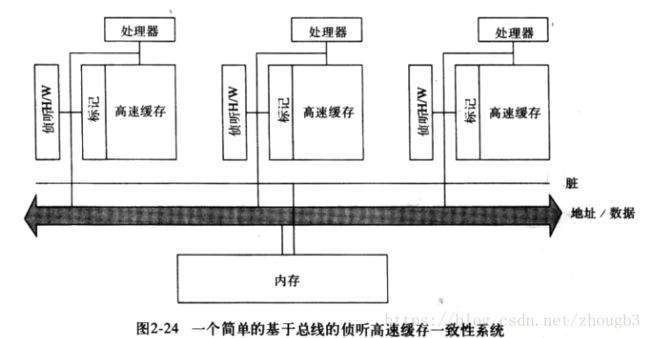
高速缓存侦听系统:所有处理器都侦听总线事务。每个处理器的高速缓存都有一组标记位。(瓶颈在于共享总线的带宽有限,单位时间只能执行这样一组数量不变的一致性操作)所有的处理器都要侦听所有信息。因此可以使用目录的方式。
基于目录的系统:状态表示当前变量状态,存在位表示在哪个处理器中。
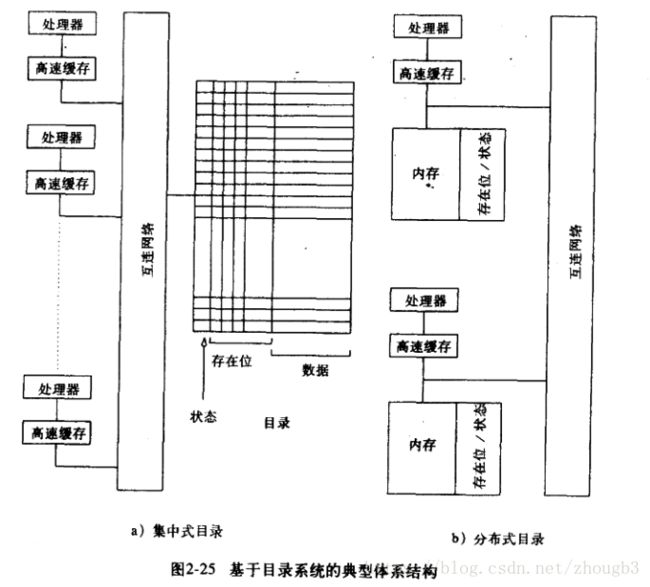
只有拥有某一个特定块的处理器,才会由于一致性操作参与转换。
并行计算机的通信成本
消息传递的成本
存储转发路由:一个节点完全接收消息之后才会转发给下一个节点。

包路由:把消息切分为多个包。每个包可能走不同路径。通信时间同直通路由,但是有包头的开销。
直通路由(cut-through routing):强制所有的包走相同的路径,强制顺序发送,减少路由选择信息开销 。

优化消息传送的成本:
1. 大块通信。每次发送的消息尽可能大,因为每次发消息都要一个ts。一个消息可以分为多个包。
2. 减少数据的大小
3. 减少数据传送的距离。
共享地址空间计算机的通信成本
很难准确计算
互联网络的路由选择机制
- 路由选择机制分为确定性路由选择和自适应路由选择。
- 维序路由选择(dimension-ordered routing)是确定性路由的一种。有XY-routing和e-cube routing等。在一个无回绕的二维格网中,先沿X维发出,到达所在列再从Y维发出。在一个立方体中,先从最低不同有效位开始进行发送。
- Routing must avoid hot-spots - for this reason, two-step routing is often used. In this case, a message from source s to destination d is first sent to a randomly chosen intermediate processor i and then forwarded to destination d.
进程-处理器映射的影响和映射技术
程序员无法控制进程-处理器映射。映射到E’的任意边上的边数最大值称为映射拥塞度。E中任意一条边能映射到E‘中的最大链路数目,称为映射膨胀度(dilation)。集合V’中节点的数目和集合V中节点数目之比称为映射扩充度(expansion)
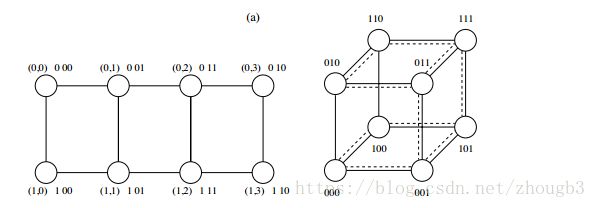
线性阵列嵌入到超立方体
如图所示,原来线性阵列中的4和5通信变成了6和7通信。全都只差一位,所以the congestion, dilation, and expansion of the mapping are all 1
将格网嵌入超立方体
格网中的每一行都映射到超立方体中的不同子立方体上。将行的映射和列的映射串在一起就是立方体上的节点值了。
如上图,把行数(0,1)映射,列数(0,1,2,3)映射,把映射的结果合并就是了。膨胀度和拥塞度都是1。
将格网嵌入线性阵列
这是将稠密网络映射到稀疏网络(边数变少了),所以一定会造成阻塞。
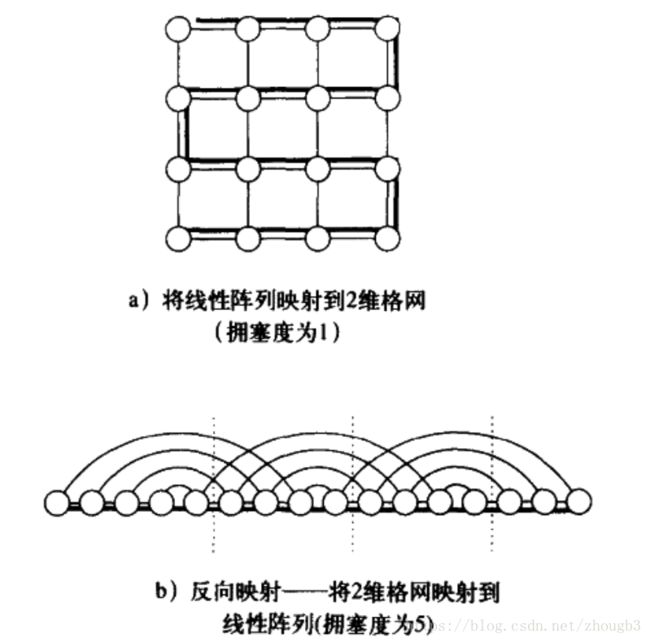
任何映射的拥塞度下界都为根号p,可以通过对分宽度考虑。
将超立方体嵌入二维格网

如果稀疏网络的链路带宽增大到可以抵消拥塞,就可以按稠密网络一样运行。高维网格通常布局复杂,人们通常更喜欢胖的低维网格。
成本-性能平衡
将环绕格网与超立方体进行对比。如果两者的链路数目一样(成本一致),格网的带宽更大。如果使用直通路由选择,当节点数p>16且消息m够大时,格网的通信成本更低。如果使用的是存储-转发路由,则格网不再具有成本有效性。
如果网络负载很重,使用超立方体更好。在网络负载较轻的条件下,同样成本的格网性能总是好于超立方体。
如果网络成本与对分带宽成正比,也可以得出同样结论。