数据库系统概念-----高级SQL
本节目录
1、使用程序设计语言访问数据库
2、函数和过程
3、触发器
4、递归查询
5、高级聚集特性
6、OLAP
7、总结
1、使用程序设计语言访问数据库
SQL提供一种强大的声明性查询语言,实现相同的查询,用SQL写查询语句比通用程序设计语言简单,然而数据库程序员必须能够使用通用程序设计语言,原因至少有以下两点:
*因为SQL没有提供通用设计语言那样的表达能力,所以SQL并不能表达所有查询要求。
*非声明性的动作都不能用SQL实现,一个应用程序通常包括很多部分,查询或更新数据只是其中之一。
可以通过一下两种方法从通用编程语言中访问SQL:
*动态SQL:通用程序设计语言可以通过函数或方法来连接数据库服务器并与之交互。利用动态SQL可以在运行时以字符串形式构建SQL查询,提交查询,然后把结果存入程序变量中,每次一个元组,动态SQL的SQL组件允许程序在运行时构建和提交SQL查询。
这一章中会介绍两种用于连接到SQL数据库并执行查询和更新的标准,一种是java语言的应用程序接口JDBC,另一种是ODBC,最初是为C语言开发的,后来扩展到C++等。
*嵌入式SQL:与动态SQL类似,嵌入式SQL提供了另外一种使程序与数据库服务器交互的手段,然而嵌入式SQL语句必须在编译时全部确定,并交给预处理器,预处理程序提交SQL语句到数据库系统进行预编译和优化,然后把它应用程序中的SQL语句替换成相应的代码和函数,最后调用程序语言的编译器进行编译。
1.1 JDBC(略)
1.2 ODBC
开放数据库互连标准定义了一个API,应用程序用它来打开一个数据库连接、发送查询和更新以及获取返回结果等。应用程序可以使用相同的ODBC API来访问任何一个支持ODBC标准的数据库。
每一个支持ODBC的数据库系统都提供一个和客户端程序相连接的库,当客户端发出一个ODBC API请求,库中的代码就可以和服务器通信来执行被请求的动作并取回结果。
下图是一个使用ODBC API的c语言代码示例,使用ODBC和服务器通信的第一步就是建立一个和服务器的连接,为了实现这一步,程序先分配一个SQL环境变量,然后是一个数据库连接句柄,OBDC定义了HENV、HDBC、和RETCODE几种类型,程序随后利用SQLConnect打开和数据库的连接,这个调用有几个参数,包括数据库的连接句柄、要连接的服务器、用户的身份和密码等,常数SQL_NTS表示前面的参数是一个以null结尾的字符串。

一旦连接建立,C语言就可以通过SQLExecDiret语句把命令发送到数据库,因为C语言的变量和查询结果的属性绑定,所以当一个元组被SQLFetch语句取回时,结果中的相应的属性的值就可以放到对应的C变量里了,SQLBindCol做这项工作,在SQLBindCol函数中第二个参数代表选择属性中哪一个位置的值,第三个参数代表SQL应该把属性转化为什么类型的C变量,再下一个参数给出存放变量的地址,对于诸如字符数组这样的变长类型,最后两个参数还要给出变量的最大长度和一个位置来存放元组取回时的实际长度,如果一个长度域返回一个负值,那么代表着这个值为null。对于定长类型的变量如整型或浮点型,最大长度的域被忽略,而当长度域返回一个负值时表示该值为空值。
SQLFetch在while循环中一直被执行,知道SQLFecth返回一个非SQL_SUCCESS的值,在每一次fecth过程中,程序把值存放在调用SQLBindCol所说明的C变量中并把它们打印出来。在会话结束的时候程序释放语句的句柄,断开与数据库的连接,同时释放连接和SQL环境句柄,好的编程风格要求检查每一个函数的结果,确保它们没有错误。
可以创建带有参数的SQL语句,例如![]() 问号是为将来提供值的占位符,上面的语句可以先被准备,也就是在数据库中先编译,然后可以通过占位符提供具体的值来反复执行。
问号是为将来提供值的占位符,上面的语句可以先被准备,也就是在数据库中先编译,然后可以通过占位符提供具体的值来反复执行。
ODBC为各种不同的任务定义了函数。在默认情况下,每一个SQL语句都被认为是一个自动提交的独立事务,调用SQLConnectOption(conn,SQL_AUTOCOMMIT,0)可以关闭连接conn的自动提交,事务必须通过显式的调用SQLTransact(conn,SQL_COMMIT)来提交或显式的调用SQLTransact(conn,SQL_ROLLBACK)来回滚。
SQL标准定义了调用级接口,它与ODBC接口类似。
1.3 嵌入式SQL
SQL标准定义了嵌入SQL到许多不同的语言中,SQL查询所嵌入的语言被称为宿主语言,宿主语言中使用的SQL结构被称为嵌入式SQL。
使用宿主语言写出的程序可以通过嵌入SQL语法访问和修改数据库中的数据,一个使用嵌入式SQL的程序在编译前必须先由一个特殊的预处理器进行处理,嵌入的SQL请求被宿主语言的声明以及允许运行时刻执行数据库访问的过程中所调用所代替,然后产生的程序由宿主语言编译器编译,这是嵌入式SQL和JDBC或ODBC的主要区别。
在JDBC中SQL语句是在运行时被解释的,当使用嵌入式SQL时,一些SQL相关的错误可以再编译过程中被发现。
为了使预处理器识别嵌入式SQL请求,使用EXEC SQL语句,格式如下:
![]()
嵌入式SQL的确切语法依赖于宿主语言,在应用程序中合适的地方插入SQL INCLUDE SQLCA语句,表示预处理器应该在此处插入特殊变量用以程序和数据库系统之间的通信。
在嵌入的SQL语句中可以使用宿主语言的变量不过前面要加:以区别SQL变量。
在执行任何SQL语句之前,程序必须首先连接到数据库,使用下面的语句实现:
![]()
这里的server标识将要建立的服务器。嵌入式SQL语句的格式和本章描述的SQL语句类似。但是这里要指出几点重要的不同之处。
为了标识关系查询,使用声明游标语句,然而这时并不计算查询的结果,而程序必须用open和fetch语句,得到结果元组。以之前的大学模式,假设我们有一个宿主变量credit_amount,声明方法和宿主语言惯例一样。假设想找出学分高于credit_amount的所有学生的名字,查询如下:

上述表达式中的变量c被称为查询的游标,我们使用这个变量来标识该查询,然后用open语句来执行查询。open语句如下:
![]()
这条居于使得数据库系统执行这条查询并把执行结果存于一个临时关系中,当open语句被执行的时候,宿主变量的值就会被应用到查询中。如果SQL查询出错,数据库系统将会在SQL通信区域的变量中存储一个错误诊断信息。然后利用一系列fecth语句把结果元组的值赋给宿主语言的变量。
![]()
接下来的应用程序就可以利用宿主语言的特性对si和sn进行操作了。我们必须使用close语句来告诉数据库系统删除用于保存查询结果的临时关系,对于上面的例子:

用于数据库修改的嵌入式SQL表达式不返回结果,因此这种语句表达起来在某种程度上相对简单,数据库修改请求格式如下:
![]()
前面带冒号的宿主语言的变量可以出现在数据库修改语句的表达式中,如果在语句执行过程中出错,SQLCA中将设置错误诊断信息。
也可以通过设置游标来更新数据库关系。然后利用在游标上的fecth操作对元组进行迭代。
2、函数和过程
前面学到了SQL的一些内建函数,这一节可以编写自己的函数和过程,把它们存储在数据库中并在SQL语句中调用,函数对于特定的数据类型比如图像和几何对象来说特别有用。
函数和过程允许业务逻辑作为存储过程记录在数据库中,并在数据库中执行。这样有几个优点,比如,允许多个应用访问这个过程,允许当业务规则改变时进行单个点的改变,而不必改变应用系统的其他部分,应用代码可以调用存储过程,而不是直接更新数据库关系。
SQL允许定义函数、过程和方法。
2.1 声明和调用SQL函数和过程

如上图,定义了这样一个函数,给定一个系名字,返回该系的教师数目,之后应用这个函数如下:

SQL标准支持返回关系作为结果的函数,这种函数称为表函数,下图的函数返回一个包含特定系的所有教师的表。

注意使用函数参数的时候要加上函数名作为前缀。如下:

这个查询返回金融系的所有教师,在上面简单情况下直接写这个查询而不用以表为值的函数也是很直观的,通常以表为值的函数可以看做带参数的视图,它允许参数把视图的概念更加一般化。
SQL也支持过程,dept_count函数也可以写成一个过程:

关键字in和out分别表示待赋值的参数和为返回结果而在过程中设置值的参数。
可以从一个SQL过程中或者嵌入式SQL使用call语句调用过程:

过程和函数可以通过动态SQL触发。
SQL允许多个过程同名,只要同名过程的参数个数不同,名称和参数个数用于标识一个过程,SQL也允许多个函数同名,只要这些同名的不同函数的参数个数不同,或者对于那些有相同参数个数的函数,至少有一个参数的类型不同。
2.2 支持过程和函数语言构造
SQL所支持的构造赋予了它与通用程序设计语言相当的几乎所有功能,SQL标准中处理这些构造的部分称为持久存储模块。
变量通过declare语句进行声明,可以是任意的合法SQL类型,使用set语句进行赋值。
一个复合语句有begin...end的形式,在begin和end之间会包含复杂的SQL语句,可以在复合语句中声明局部变量,一个形如begin atomic ...end的复合语句可以确保其中包含的所有语句作为单一的事务来执行。
while语句和repeat语句语法如下:

还有for循环,他允许对查询的所有结果重复执行:

程序每次获取查询结果的一行,并存入for循环变量,语句leave可用来退出循环,而iterate表示跳过剩余语句从循环的开始进入下一个元组。SQL支持的条件语句包括if-then-else语句,语法如下:

SQL也支持case语句,类似C/C++语句中的case语句。下图是一个SQL的过程化结构的更大型的一点的例子,图中定义的函数registerStudent首先确认选课的学生数没有超过该课的所在教室的容量,然后完成学生对该课的注册,函数返回一个错误代码。这个值大于0表示成功,返回负值表示出错,同时以out参数的形式返回消息来说明失败的原因。
SQL程序语言还支持发信号通知异常条件,以及声明句柄来处理异常。代码如下:

SQL过程化结构:

在begin和end之间的语句可以执行signal out_of_classroom_seats来引发一个异常,这个句柄说明,如果条件发生,将会采取动作终止begin end之间的语句,另一个可选的动作是continue,他将从引发异常的语句的下一条语句开始执行,除了明确定义的条件,还有一些预定义的条件,比如,sqlexception,sqlwarning和not found。
虽然SQL标准定义了过程和函数,但是很多数据库并不严格遵守标准。
2.3 外部语言过程
SQL过程化扩展很有用但是并不能跨数据库的标准的方法,所以,有一种方案可以解决语言支持的问题,即在一种命令式程序设计语言中定义过程,然后从SQL查询和触发器的定义中调用它。
SQL允许我们用一种程序设计语言定义函数,比如java、C、C++等,这种方式定义函数比SQL中定义的函数效率更高,无法在SQL中执行的计算可以由这些函数执行。
外部过程和函数可以这样指定:

通常来说外部语言过程需要处理参数(包含in和out参数)和返回值中的空值,还需要传递操作失败/成功的状态,以方便对异常进行处理,这些信息可以通过几个额外的参数来表示,一个指明失败/成功状态的sqlstate值。一个存储函数返回值的参数,以及一些指明每个参数函数结果的值是否为空的指示器变量。还可以通过其他机制来解决控制问题,比如传递指针。如果一个函数不关注这些情况,在声明语句的上方添加一行parameter style general 指明外部过程函数只使用说明的变量并且不处理空值和异常。
用程序设计语言定义并在数据库系统之外编译的函数可以由数据库系统代码来加载和执行,不过这样做的存在危险,那就是程序中的错误可能破坏数据库内部的结构,并且绕过数据库系统的访问-控制功能,如果数据库系统关心执行的效率胜过安全性则可以采用这种方式执行过程。关心安全性的数据库系统一般会将这些代码作为一个单独的进程的一部分来执行,通过进程间通信传入参数的值,取回结果,但是进程间通信的时间代价非常高,在典型的CPU体系结构中,一个进程通信所需的时间可以执行数万到数十万的执行。
3、触发器
触发器是一条语句,当对数据库系统修改时,它被自动被系统执行,要设置触发器机制,必须满足两个要求:
*指明什么条件下执行触发器,它被分解为一个引起触发器被监测的事件和一个触发器执行必须满足的条件。
*指明触发器执行时的动作。
一旦我们把一个触发器输入数据库,只要指定的事件发生,相应的条件满足,数据库系统就有责任去执行它。
3.1 对触发器的需求
触发器可以用来实现未被SQL约束机制指定的某些完整性约束,它还是一种非常有用的机制,只用来当满足特定条件时对用户发警报或自动开始执行某项任务。
3.2 SQL中的触发器
这里介绍的是SQL标准定义的语法,但是大部分数据库实现的方法并不是标准版本,但是概念是适用的。下图展示了如何使用触发器来确保关系section中属性time_slot_id的参照完整性,图中第一个触发器定义指明该触发器在任何一次对关系section的插入操作执行之后被启动,以确保所插入元组的time_slot_id字段是合法的,一个SQL插入语句可以向关系中插入多个元组,在触发器代码中for each row语句可以显示的在每一个被插入的行上进行迭代,referencing new row as语句建立了一个变量nrow成为过渡变量,用来在插入完成后存储所插入的值。

when语句指定一个条件,对于满足条件的元组才会执行触发器部分,begin atomic ...end语句用来将多行SQL语句集成一个复合语句,在上例中只有一条语句,它对引起触发器被执行的事务进行回滚,这样所有违背参照完整性约束的事务都会被回滚。,从而确保数据库中的数据满足约束条件。
只要检查插入时的参照完整性还不够,还需要考虑对关系section的更新,以及被引用的表time_slot的删除和更新操作。
为了保证参照完整性,我们必须处理section和time_slot的更新来创建触发器。对更新来说,触发器指定哪个属性的更新使其执行,其他属性的更新不会让它产生动作。
referencing old row as子句可以建立一个变量用来存储已经更新或删除行的旧值,referencing new row as子句除插入还可以用于更新操作。
如下图所示,当关系takes中元组的属性grade被更新时,需要用触发器来维护student里元组的tot_cred属性,使其保持实时更新,只有当属性grade从空值或F被更新为代表课程已经完成的具体分数时,触发器才会被激发,除了nrow的使用,update语句都属于标准的SQL语法。

许多数据库系统支持各种别的触发器事件,比如当一个用户登录到数据库的时候、或者系统停止的时候、或者当系统设置改变的时候。触发器可以在事件(insert、delete、update)之前激活,而不仅是事件之前被执行的触发器可以避免非法更新、插入、或删除的额外约束。
我们可以对引起插入、删除或更新的SQL语句执行单一动作,而不是对每个被影响的行执行一个动作。要做到这一点,我们用for each statment子句来替代for each row子句,可以用referencing old table as 或referencing new table as来指向包含所有被影响的行的临时表(过渡表),过渡表不能用于before 触发器但是可以用于after触发器,他们是语句触发器还是行触发器,这样在过渡表的基础上,一个单独的SQL语句就可以执行多个动作。
触发器可以设置为有效或无效,默认情况下他们在创建时是有效的。但是可以通过使用alter trigger trigger_name disable,将其设置为无效。设为无效的触发器可以重新设置为有效,通过命令drop tigger tigger_name,触发器也可以被丢弃,即将其永久移除。
3.3 何时不用触发器
很多数据库现在支持物化视图,有数据库系统自动维护,因此没有必要编写代码让触发器来维护这样的物化视图。
触发器也被用来复制和备份数据库,在每一个关系的插入、删除或更新上的操作创建触发器,将改变记录在称为change或delta的关系上,一个单独的进程将改变这些复制到数据库的副本。然而现代数据库提供内置的数据库复制工具,使得复制在大多数情况下不必使用触发器。
触发器是很有用的工具,但是如果有其他候选方法最好不使用触发器。
4、递归查询
考虑下图的例子,关系preeq的实例包含大学开设的各门课程的信息以及每门课的先修条件,假设我们知道某个特定课程(例如CS-347)的直接或者间接的先修课程,也就是说,我们想找这样的课,要么是选修CS-347的直接先决条件,要么是CS-347的先修课程的先决条件。因此,如果CS-301是CS-347的先修课程,CS-201是CS-301的先修课程,还有CS-101是CS-201的先修课程,那么CS-301、CS-201、CS-101都是CS-347的先修课程。
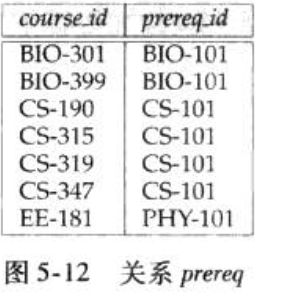
关系prereq的传递闭包,是一个包含所有的(cid,pre)对的关系,pre是cid的一个直接或间接先修课程。
4.1 用迭代来计算传递闭包
一个写上述查询的方法就是是用迭代,首先找到CS-347的那些直接先修课程,然后第一个集合中的所有课程的先修课程。如此类推,迭代持续进行,直到某次循环中没有新课程加进来才停止,下图显示了执行这次任务的函数。

这个函数以课程的course_id为参数(cid),计算该课程所有直接或间接的先修课程并返回它们组成的集合。过程中用到三个临时表:
*c_prereq:存储要返回的元组集合。
*new_c_prereq:存储在前一次迭代中找到的课程。
*temp:当对课程集合进行操作时用作临时存储。
注意,SQL允许使用命令create temporary table来创建临时表,这些表仅在执行查询的事务内部才可用,并随事务的完成而被删除,而且,如果findAllPrereqs的两个实例同时运行,每个实例都拥有自己的临时表副本,假设他们共享一份副本,结果就会出错。
该过程在repeat循环之前,就把课程的cid的所有先修课程插入new_c_prereq中,repeat循环首先把new_c_prereq中所有的课程中加入c_prereq中,然后它为new_c_prereq中所有课程计算先修课程,从结果中筛选掉此前已经计算出来是cid的先修课的课程。把剩下的存放在临时表temp中,最后它把new_c_prereq中的内容替换成temp中的内容,当找不到新的新修课程时,repeat循环终止。
下图是迭代过程中产生的先修课程。

4.2 SQL中的递归
用迭代表示传递闭包并不是很方便,还有另一种方法即使用递归试图定义,这种方法更容易使用。
用递归为某个指定课程如CS-347定义先修课程集合,方法如下,CS-347的(直接或间接)先修课程是:
*CS-347的先修课程
*作为CS-347的(直接或间接)先修课程的先修课程的课程。
第二条也就是递归。它用CS-347的先修课程来定义CS-347的先修课程。
SQL标准中用with recursive子句来支持有限形式的递归。在递归中一个视图或临时视图用自身来表达自身。whit子句用于临时定义一个视图,该视图的定义只能对它的查询可用,附加的关键字recursive表示该视图是递归的。
例如用下图显式的递归SQL视图,可以找到每一对(cid,pre)其中pre是cid的直接或间接的先修课程。

任何递归视图都必须被定义为两个字查询的并,一个是非递归的基查询和一个使用递归视图的递归查询,上图中,基查询是关系prereq上的选择操作,而递归查询则计算prereq和rec_prereq的连接。
对递归视图含义最好的理解如下,首先计算基查询并把所有结果元组添加到视图关系的内容计算递归查询,并把所有结果元组加到视图关系中。知道上述步骤中没有新的元组添加到视图关系中为止,得到的视图关系实例就称为递归视图定义的一个不动点,这里的不动是指不会再有进一步的改变。这样的视图关系被定义为正好包含处于不动点实例中的元组。
递归查询不能用于人和系啊咧够早,因为它们会导致查询并非单调:
*递归视图上的聚集
*在使用递归视图的子查询的not exists语句。
*右端使用递归视图的集合差运算。
5、高级聚集特性
5.1 排名
从一个大的集合找出某值的位置是一个常见的操作,在之前的大学例子中,关系takes存储了每个学生所选的每一门课程上所获得的成绩,为演示排名,假设有一个视图student_grades(ID,GPA),它给出每个学生的平均绩点。
排名使用order by说明实现的,下面的查询给出每个学生的名次:

注意上面并没有定义输出中的元组顺序,所以元组可能不按名次排序,需要使用一个附加的order by子句得到排序的元组,如下所示:

有关排名的一个基本问题是如何处理多个元组在排序属性上具有相同值的情况,rank函数对所有在order by属性上相等的元组相同的名词,还有一个函数dense_rank函数,它不在排序中产生隔断。
可以使用基本的SQL聚集函数来表达上述查询,查询语句如下:

上述语句,一个学生的排名就是那些GPA比他高的学生的数目再加1,但是很明显上述语句需要花很多时间来执行,相比之下,rank子句的系统实现能够对关系进行排序并在相当短的时间计算排名。排名可在数据的不同分区进行,比如我们可以按照系而不是整个学校范围对学生排名,假设有一个视图,它像student_grades那样定义,但是包含系名dept_grades,那么下面的查询给出学生们在每个分区的排名:

外层的order by子句将结果元组按照系名排序,在各系按照名次排序。一个单独的select语句中可以使用多个rank表达式,因此通过在一个select语句中使用两个rank表达式的方式,我们可以得到总名次以及在系内的名次,当排名与group by 子句同时出现时,group by 语句先执行,分区和group by 在结果上执行。因此得到的聚集值之后可以用来做排名。
利用将排名查询嵌入外层查询中的方法,排名函数可以用于找出排名最高的n个元组。一些数据库允许在SQL查询后面添加limit n子句,用来指明只输出前n个元组,这个字句可以和order by子句连用获取排名最高的n个元组。limit子句不支持分区。
还有几个可以用来代替rank的函数,函数cume_dist对一个元组定义为p/n,其中p是分区中排序值小于或等于该元组排序值的元组数,n是分区中的元组数,函数row_number对行进行排序,并且按行在排序顺序中所处位置给每行一个唯一行号,具有相同排序值的不同行将按照非确定的方式得到不同的行号。
最后对于一个给定的常数n,排名函数ntile按照给定的顺序取得每个分区中的元组,并把它们分成n个具有相同元组数目的桶,对每个元组,ntile(n)给出他所在的桶号,该函数对构造基于百分比的直方图特别有用。比如我们可以使用下面的查询,根据GPA把学生分为四个等级,

空值的存在可能使排名的定义复杂化,因为不清楚的空值应该出现在排序顺序的什么位置。SQL允许用户使用null first或null last以指定它们出现的位置。

5.2 分窗
窗口查询用来对于一定范围内的元组计算聚集函数,这个特性很有用,比如计算一个固定时间内区间的聚集值。这个时间区间就被成为一个窗口,窗口可以重叠,这种情况下一个元组可能对多个窗口都有贡献,这和之前的的分区是不一样的,因为分区查询中一个元组只对一个分区有贡献。
趋势分析是分窗的应用案例之一。要写一个查询来计算一个窗口的聚集值,用之前的哪些特性是相对简单的,例如计算一个固定的三天时间区间的销售量,但是如果对三天时间区间都如此计算,查询就变得比较难了。SQL提供分窗用于支持这样的查询,假设我们有一个视图,tot_credits(year,num_credits)它记录了每年学生选课的总学分,注意这个关系中每个年份最多对应一个元组。那么如下查询:

这个查询计算指定顺序下的前三个元组的均值。假设不想回溯固定数量的元组,而是把前面所有年份都包含在窗口内,这意味着要关注的前面的年数并不恒定,可以编写下面代码得到前面所有年的平均总学分:

也可以使用following来替换preceding,如果这样做,year值就表示窗口的起始年份,而不是结束年份。类似的可以指定一个窗口,他在当前元组之前开始,在其后结束:

还可以使用order by属性上的值的范围而不是行的数目来指定窗口,为了得到一个包含当前年以及前面四年的范围,我们可以这样写:

注意上面关键字range的使用。
6、OLAP
联机分析处理(OLAP)系统是一个交互式系统,他允许分析人员查看多维数据的不同种类的汇总数据,联机一词5表示分析人员必须能够提出新的汇总数据请求,几秒钟之内得到响应,无须为了看到查询结果而被迫等待很长时间。
6.1 联机分析处理
考虑这样一个应用,某商店想要找出流行的服装款式,假设衣服的特性包括商品名、颜色、尺寸,并且我们有一个关系sales,它的模式是
假设item_name可以取得值为skirt、dress、shirt、pants;color可以取得值为dark、pastel、white;clothes_size可以取得值为small、medium、large;quantity是一个整数值,表示一个给定条件{item_name、color、clothes_size}的商品数量。
统计分析通常需要对多个属性进行分组,给出一个用于数据分析的关系,我们可以把它的某些属性看做度量属性,因为这些属性度量了某个值,可以在其上进行聚集操作。例如,关系sales的属性qualtity就是一个度量属性,因为它的度量卖出商品的数量,关系的其他属性中的某些或所有的属性可以看做是维属性,因为他们定义了度量属性以及度量属性的汇总可以在其上进行观察的各个维度。
能够模式化为维属性和度量属性的数据统称为多维数据。为了分析多维数据,管理者可能需要查看如下图那样显式的表:
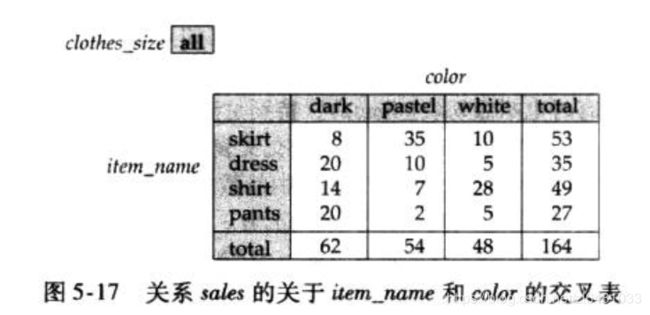
该表显示了item_name和color值之间不同组合情况下的商品数目,clothes_size的值指定为all,意味着表中显示的数值是所有的size值上的数据汇总。上图所示的表是一个交叉表,也可称为转轴表,一般来说,一个交叉表是从一个关系导出来的,由关系R的一个属性的值构成其行表头,关系R的另一个属性构成其列表头。
在我们的例子中,交叉表还另有一列和一行,用来存储一行、列中的所有单元总和,大多数的交叉表中都有这样的汇总行和汇总列。
将二维的交叉表推广到n维,可视作一个n维立方体,称为数据立方体。在OLAP系统中,数据分析人员可以交互的选择交叉表的属性,从而能够在相同的数据上查看不同内容的交叉表。改变交叉表中的维的操作叫作转轴。
OLAP系统分析允许分析人员对于一个属性固定的值来查看在另外属性上值的交叉表,这种操作叫作切片。有时也叫切块,当多个维度的值是确定的时候。
6.2 交叉表与关系表
交叉表与数据库中的关系表是不同的,因为交叉表中的列的数目依赖于实际的数据。作为向用户的展现,交叉表示比较令人满意的,对于没有汇总值的交叉表,可以把它直接表示为具有固定列数的关系形式,对于有汇总行/列的交叉表,可以通过引入一个特殊值all以表示子汇总值,实际上SQL标准使用null值代替all,但是为了避免与通常的null混淆,继续使用all。
值all可以看做代表一个属性的所有值的集合。维度上具有all值的元组可以通过group by聚集得到。
6.3 SQL中的OLAP
有些SQL实现支持在SQL中使用pivot子句,用于创建交叉表。如下:

可以返回一个交叉表,pivot子句中的for子句用来指定属性color的那些值应该在转轴的结果中作为属性名出现,属性color本身在结果中被去除,然而所有其他属性都被保留,另外新产生的属性的值被设定为来自属性quantity,在多个元组对于给定单元有贡献的情况下,pivot子句中的聚集操作指定了把这些值进行汇总的方法。
单个SQL查询使用基本的group by结构生成不了数据立方体中的数据,因为聚集是对维属性的若干个不同分组计算的,由于这个原因,SQL包含一些函数,用来生成OLAP中所需要的分组。
SQL支持group by结构的泛化形式用于进行cube和rollup操作,group by子句中的cube和rollup结构允许在单个查询中运行多个group by 查询,结果以单个关系的形式返回。
以一个零售商店为例,关系是:![]() ,我们可以编写简单的group by 查询来得到每个商品名所对应的商品销售量:
,我们可以编写简单的group by 查询来得到每个商品名所对应的商品销售量:

这个查询结果如下所示:

类似的,我们可以得到每种颜色的商品销售量,在group by 子句中用多个属性,就可以知道某个参数集合条件下每类商品卖出了多少,但是如果想用这种方式生成整个数据立方体,我们不得不为每个属性集写一个独立的查询:

()表示空的group by列表。
cube结构使我们能在一个查询中完成这些任务:

上述的查询产生了一个模式如下的关系:
![]()
这样,该查询结果实际上是一个关系,对于在特定分组中不出现的属性,在结果元组中包含null作为其值。
数据立方体经常非常庞大,上面的cube查询,会产生80个元组,可以用all代替空值,这样更容易被一般用户读懂。
rollup结构与cube结构基本一样,只有一点不同,就是roolup产生的group by查询较少一些,我们看到,group by cube(item_name,color,clothes_size)生成使用部分属性,可以产生的全部8中实现group by 查询的方法,而在下面的查询中:

group by rollup (item_size,color,clothes_size)只产生四个分组:
![]()
注意,rollup中的属性按照顺序不同有所区分,最后一个属性只在一个分组中出现,倒数第二个属性出现在两个分组中,以此类推,第一个属性出现在所有组中。rollup产生的特定分组在具有频繁的实用价值。rollup结构允许我们为更深层次的细节而设定这样的下钻序列,多个rollup和cube可以在一个单独的group by子句中使用,如下:

产生以下分组:
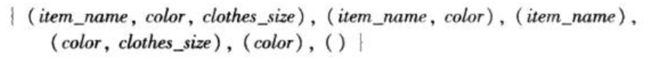
为了理解其原因,注意到rollup(item_size)产生了两个分组,{(item_name),()},rollup(color,clothes_size)产生了三个分组:
{(color,clothes_size),(color),()},这两部分的笛卡尔积得到上面显示的六个分组。
rollup和cube子句都不能完全控制分组的产生。
7、总结
*SQL查询可以从宿主语言通过嵌入和动态SQL激发。
*函数和过程可以用SQL提供的过程扩展来定义。
*触发器定义了当某个事件发生而满足相应条件时自动执行的动作。
*一些查询,比如传递闭包,可以用迭代表示,也可以用递归表示。
*SQL提供一些高级聚集特性,包括排名和分窗查询。
*联机分析处理(OLAP)工具帮助分析人员用不同方式查看汇总数据。