多目标非支配排序遗传算法-NSGA-II
本博客将详细介绍 NSGA-II算法的实现过程,对比分析约束与非约束条件下NSGA-II实现方法,另后期本博客还将添加基于偏好的 NSGA-II算法分析。本人对于智能优化算法/元启发式优化算法是初学,若有不当/错误之处,还望告知
文章目录
- 1. 参考文献及博客
- 2. 源码
- 3. 支配与非支配解
- 4. 何为非劣解,Pareto解集,Pareto前沿?
- 5 NSGA与NSGA-II算法
- (1)NSGA算法
- 1)实现过程
- 2)缺陷
- (2) NSGA-II算法
- 1)精英主义策略
- 2)评估函数
- 3)非支配排序和等级划分
- 4)选择操作-拥挤度计算
1. 参考文献及博客
首先,我提前在文章的上半部分列出本文撰写时所参考的论文及博客,望读者多多阅读,慢慢体会文章及博客所要表达的算法含义,相信读者将收益匪浅。
论文:
[1]:Deb K, Pratap A, Agarwal S, et al. A fast and elitist multiobjective genetic algorithm: NSGA-II[J]. IEEE Transactions on Evolutionary Computation, 2002, 6(2):182-197.
[2]: Siinivas N, Deb K.N. Muiltiobj ective optimization using nondominated sorting in genetic algorithms[J]. 1994,2(3):221-248.
[3]: Deb K, Sundar J, Rao N UB. Chaudhuri S. Reference point based multi-objective optimization using evolutionary algorithms2006,2(3):273-286.
[4] Matlab Help, Global optimization toolbox.
[5] Deb K, Thiele L, Laumanns M, et al. Scalable Test Problems for Evolutionary Multi-Objective Optimization[C]. Piscataway, New Jersey: 2002.
[6] Lin S. NGPM – a NSGA-II program in Matlab (Version 1.4).
[7] 李莉, 基于遗传算法的多目标寻优策略的应用研究[D].无锡: 江南大学,2008.
英文论文一并打包,请自行下载。
————————————————
博客:
多目标优化算法(一)NSGA-Ⅱ(NSGA2)
作者:晓风wangchao
多目标遗传算法NSGA
作者:kiding_k
NSGA-II入门C1
作者:WUST许志伟
NSGA 和 NSGA-II 学习笔记
作者:royce_feng
2. 源码
NSGA-II YARPIZ
NSGA-II Kalyanmoy Deb
NGPM Song Lin
3. 支配与非支配解
在对NSGA-II展开之前,我们先了解一下多目标优化算法中的一些概念。何为支配,何为非支配?从字面意思上, A 支配B,表明A的权利更大。 举个不恰当的例子,导师支配博士学生,博士学生支配硕士学生,则优先级导师>博士>硕士。 当我们讲支配与非支配放到多目标优化中,则会出现一定程度的不同,“支配”含义在多目标优化中更多表示被支配的解集(学生),非支配则表示不能被支配的解集(导师)。老师跟学生的支配与被支配关系在于导师拥有更高的科研能力(也就是,多目标优化中拥有较大/小目标函数值),进而老师这一群体获得的成就一般都会大于学生,成为学术的引领者(最优解集)。

4. 何为非劣解,Pareto解集,Pareto前沿?
非劣解:非劣解(noninferior solution)是多目标规划的基本概念之一,对于包括有定量和定性属性的多指标决策问题,其非劣解是指在所给的可供选择的方案集中,已找不到使每一指标都能改进的解。在多目标规划中,它即指有效解和较多最优解。
一般来说多目标规划问题(VP)的绝对最优解是不存在的。当绝对最优解不存在时,需要引入新的“解”的概念——非劣解( non-inferior solution),又称非控解(non-dominance solution)、有效解(efficient solution)、巴列托最优解(Pareto-optimal solution)、锥最优解( cone-optimal solution)
非劣解即指在可行方案集中再也找不到一个各目标的属性值都不劣于A方案,而且至少有一个目标属性比A优的方案,那么方案A就是非劣解。换句话说,各目标函数值在A方案下是最大/最小的了。
多目标决策问题中没有最优解,但通常有一个以上的非劣解。如何理解?既然没有不劣于方案的方案了,那为什么还有一个以上的非劣解?
我个人理解的:方案是针对目标函数的,解是针对变量的,目标函数值相同,变量可以不同。
Pareto 解集,Pareto 前沿:多目标优化问题的目标往往量纲不同、互相冲突,难以像单目标优化问题一样直接比较目标值来确定最优解。Pareto占优思想是一种评价多目标问题解优劣的处理方法,Pareto最优解集是指可行域中 所有非劣解 的集合(就是你所说的约束变量(x1、x2、……xn)的集合),Pareto最优前沿是 Pareto最优解集对应目标值的集合(就是你所说的目标函数空间的值(f1 f2… fn)的集合)。(参考:Pareto解集、Pareto前沿,到底是指的x还是y?)
5 NSGA与NSGA-II算法
(1)NSGA算法
关于遗传算法,本人在之前的博客中转载介绍过,具体请参照 遗传算法详解。 非支配排序遗传算法(NSGA)由Kalyanmoy Deb于1994年提出,NSGA的提出跟同期的进化算法(EAs)一样,主要目的用于求解多目标优化的问题。
在这里,我多提一下多目标优化问题的本质:我个人认为传统的多目标优化转换为单目标优化问题实则违背了多目标优化问题的本质,也与现实多目标问题所存在的不确定性相冲突。传统方法给予决策者一个所谓的优化解,这种解决方式严重依赖对于目标函数权重的设置,决策者较难认可该优化解的可靠性,更别说是处理该问题的全局最优解了。因此,给予决策者一组可行性的优化解,不同的决策者对问题分析、权衡可能会选择不同决策方案。当然,给予的可行性优化解并不一定是全局最优的,但现实社会就是这样的,社会的进步也并不是总以全局最优的方式前进的。这也是为什么要求解Pareto优化解集的原因了。

1)实现过程
NSGA算法与一般GA算法相比,仅在选择部分有着不同的操作。在一般GA算法中是通过轮盘赌方式来进行概率选择的,轮盘赌的原理请参考遗传算法详解。实现过程可通过代码来说明:
%如何选择新的个体
%输入变量:pop二进制种群,fitvalue:适应度值
%输出变量:newpop选择以后的二进制种群
function [newpop] = selection(pop,fitvalue)
%构造轮盘
[px,py] = size(pop); %px是种群个数
totalfit = sum(fitvalue);
% 取最大值的原因在这里,fitvalue越大,概率越大,是根据适应度获取的概率
p_fitvalue = fitvalue/totalfit;
p_fitvalue = cumsum(p_fitvalue);%概率求和排序
ms = sort(rand(px,1));%从小到大排列
fitin = 1;
newin = 1;
while newin<=px
if(ms(newin))此处求解的是最大- M a x f Maxf Maxf,则适应度值(目标函数值)越大,在轮盘中所占的概率也就越大,然后随机概率下被选中的概率也就越大,进而实现选择过程。
NSGA算法在选择过程中主要进行了以下几方面的修改和完善:
#1).种群分层,划分非支配解集等级
在NSGA算法中通过支配与非支配关系,实现了种群个体间的等级划分,等级越低的个体将拥有更大的选择的的权利,反之,被选择的权利将会减小。那么如何获得等级的非支配解集呢?在讲解NSGA算法非支配解等级划分之前,有必要先了解清楚算法对于非支配解的概念界定。
这里我们直接给出论文 (Siinivas N and Deb K.N,1994)中所给予的定义。

概括来讲, x 1 x_1 x1是非支配解集满足两点 ( x 1 , x 2 ∈ X x_1,x_2∈X x1,x2∈X,均为解集):
① 对任意的 x 2 ∈ X , f i ( x 1 ) < f i ( x 2 ) x_2∈X,f_i(x_1)
② 对任意的 x 2 ∈ X , f i ( x 1 ) ≤ f i ( x 2 ) x_2∈X,f_i(x_1)≤ f_i(x_2) x2∈X,fi(x1)≤fi(x2),且存在至少一个 f i ( x 1 ) < f i ( x 2 ) f_i(x_1)
③若对任意的 x 2 ∈ X x_2∈X x2∈X,存在 f i ( x 1 ) < f i ( x 2 ) f_i(x_1)<f_i(x_2) fi(x1)<fi(x2),且存在至少一个 f i ( x 1 ) > f i ( x 2 ) f_i(x_1)>f_i(x_2) fi(x1)>fi(x2); 则此时 x 1 x_1 x1与 x 2 x_2 x2不存在支配关系;
不好意思,我又邪性了,学术圈强支配上图。

#2). 基于shared niche (共享小生境)的共享适应度值计算
种群在非支配等级分层结束后,NSGA算法给每级指定一个虚拟适应度值,级别越小,说明其中的个体
越优,赋予越高的虚拟适应值,反之级别越大,赋予越低的虚拟适应值。此方式的目的保证了虚拟适度值较大或等级较小的非支配个体有更多的机会进入下一代,使得算法以最快的速度收敛于最优区域。比如第一级非支配层的个体标上虚拟适应值为 1,第二级非支配层的个体标上虚拟适应值为 0.9(或其他),以此类推,直到所有的个体都被标上虚拟适应值,同一非支配层的虚拟适度值是一样的,表明它们具有相同的复制再生(遗传)能力。但此方式也产生一个问题,同一级非支配层中的个体拥有相同的适应度值,某些个体在遗传操作中可能被遗弃,从而导致最优解集缺乏多样性。为了得到分布均匀的 Pareto 最优解集,NSGA 算法还引入了基于拥挤策略的共享小生境(Niche)技术,对同一级上原先指定的虚拟适应度值进行重新指定。然后再进行接下来的遗传操作。

说明:图中图面来源百度图片,本博客对图片进行了修改
那么这个小生境到底如何实现呢?本文参考了李莉硕士论文对于NSGA部分的介绍,截图部分已经说的很清楚了。



#3).NSGA 算法整体实现流程
NSGA算法具体的实现流程如下图所示。

说明一点,我认为图中的 reproduction accroding to dummy fitness实则说的是共享适度值。
(该图引自 Siinivas N and Deb K.N,1994)
2)缺陷
随着,对于NSGA的应用,研究学者发现NSGA同类似的EA算法一样,存在着以下缺陷:
#1). 非支配排序的高计算复杂度 ( High computational complexity of nondominated sorting),也就是我们所说的时间复杂度,NSGA算法为 O ( M N 3 ) O(MN^3) O(MN3);
#2). 缺乏精英策略(Lack of elitism);
#3). NSGA需要指定共享参数 σ s h a r e \sigma_{share} σshare。
此外,我个人认为所谓的虚拟适度值也是很随机的一种指定方式,这对寻找最优解集也有一定的影响。
因NSGA算法已更新了多个版本,原NSGA算法代码很难从网上找到,因此,本文不再对NSGA代码进行分析了。
(2) NSGA-II算法
对于NSGA算法的讲解,我们很清楚的认识到NSGA所存在的缺陷,其中#1)和#3) 我相信大家已经很清楚。但是,缺乏精英策略是什么鬼?NSGA-II算法对于NSGA算法又进行了哪些修改?接下来,我们便一一解释。
1)精英主义策略
NSGA-II中的精英策略即保留父代(上代),然后让父代和经过选择、交叉、变异后产生的子代共同组成一个群体,其目的就是为了防止父代中可能存在的最优解被遗落,最后经过再次选择操作,获得与初始种群同样规模的群落。其实,这个思想还是蛮好理解的,我们不妨再上图说明。
熟悉龙珠的朋友,相信已经明白了精英主义的策略。号称最强的赛亚人,被弗利沙干掉了,剩下的卡卡罗特及贝吉塔活了下来,而且由于他们拥有超强的赛亚人血液及男主光环,他们生下了孩子,有了孙子,而且他们还一直活着,这些人成了地球的精英人群。 不觉有感而发:“保卫地球!”。
而NSGA-II修改之处也主要是在于选择上,具体的修改部分,我将通过代码的形式来说明,参考代码主要用的是NGPM。
2)评估函数
该函数主要用于计算目标函数值及计算所需用的时间,并获取可行解信息,代码如下。
function [indi, evalTime] = evalIndividual(indi, objfun, varargin)
% Function: [indi, evalTime] = evalIndividual(indi, objfun, varargin)
% Description: Evaluate one objective function.
%
% LSSSSWC, NWPU
% Revision: 1.1 Data: 2011-07-25
%*************************************************************************
tStart = tic;
[y, cons] = objfun(indi.var, varargin{:} );
evalTime = toc(tStart);
% Save the objective values and constraint violations
indi.obj = y;
if( ~isempty(indi.cons) )
idx = find( cons ); % Find indices and values of nonzero elements
if( ~isempty(idx) )
indi.nViol = length(idx);%constrian 值非0个数
indi.violSum = sum( abs(cons) );
else
indi.nViol = 0;
indi.violSum = 0;
end
end
3)非支配排序和等级划分
非支配排序,根据有无约束条件,实现的方式也不同。无约束条件下,仅需考虑满足前边非支配讲解的条件即可;但时对于有约束条件的多目标优化问题,需要考虑以下三种情况:

也就是分别考虑两个均为可行解、一个为可行解或两个均为不可行解的情况。实现代码如下。
无约束情况:
#1) 非支配排序
%=================================================================
% Copyright (c) 2015, Yarpiz (www.yarpiz.com)
% All rights reserved. Please read the "license.txt" for license terms.
%
% Project Code: YPEA120
% Project Title: Non-dominated Sorting Genetic Algorithm II (NSGA-II)
% Publisher: Yarpiz (www.yarpiz.com)
%
% Developer: S. Mostapha Kalami Heris (Member of Yarpiz Team)
%
% Contact Info: [email protected], [email protected]
%==================================================================
function [pop, F]=NonDominatedSorting(pop)
nPop=numel(pop); % Number of array elements
for i=1:nPop
pop(i).DominationSet=[];
pop(i).DominatedCount=0;
end
F{1}=[]; % 元胞数组
for i=1:nPop
for j=i+1:nPop
p=pop(i);
q=pop(j);
% 两个if来断定两两之间的支配与被支配关系
if Dominates(p,q)
p.DominationSet=[p.DominationSet j];
q.DominatedCount=q.DominatedCount+1;
end
% 与上相反
if Dominates(q.Cost,p.Cost)
q.DominationSet=[q.DominationSet i];
p.DominatedCount=p.DominatedCount+1;
end
% 将DominationSet和DominatedCount两个属性加入到种群中
pop(i)=p;
pop(j)=q;
end
% 个体若无被支配,则放入第一级中
if pop(i).DominatedCount==0
F{1}=[F{1} i];
pop(i).Rank=1;
end
end
%
% Copyright (c) 2015, Yarpiz (www.yarpiz.com)
% All rights reserved. Please read the "license.txt" for license terms.
%
% Project Code: YPEA120
% Project Title: Non-dominated Sorting Genetic Algorithm II (NSGA-II)
% Publisher: Yarpiz (www.yarpiz.com)
%
% Developer: S. Mostapha Kalami Heris (Member of Yarpiz Team)
%
% Contact Info: [email protected], [email protected]
%
% x,y 可能不是结构体嘛?
function b=Dominates(x,y)
if isstruct(x)
x=x.Cost;
end
if isstruct(y)
y=y.Cost;
end
b=all(x<=y) && any(x#2) 等级划分
% 分级非支配解,F{k}为非支配解等级集合
k=1;
while true
Q=[];
%删除第一级的个体,并获取第二级个体,并递推
for i=F{k} %非支配解
p=pop(i); %非支配解个体
for j=p.DominationSet %非支配解支配解集
q=pop(j); %非支配解支配的个体
q.DominatedCount=q.DominatedCount-1;
%获取第二级的个体,依次递增
if q.DominatedCount==0
Q=[Q j]; %#ok
q.Rank=k+1;
end
pop(j)=q;
end
end
if isempty(Q)
break;
end
F{k+1}=Q; %#ok
k=k+1;
end
有约束情况:
#1) 约束条件的非支配排序
domMat = calcDominationMatrix(nViol, violSum, obj); % domination matrix for efficiency
% Compute np and sp of each indivudal ,np被支配,sp支配集
for p = 1:N-1
for q = p+1:N
if(domMat(p, q) == 1) % p dominate q
ind(q).np = ind(q).np + 1;
ind(p).sp = [ind(p).sp , q];
elseif(domMat(p, q) == -1) % q dominate p
ind(p).np = ind(p).np + 1;
ind(q).sp = [ind(q).sp , p];
end
end
end
function domMat = calcDominationMatrix(nViol, violSum, obj)
% Function: domMat = calcDominationMatrix(nViol, violSum, obj)
% Description: Calculate the domination maxtrix which specified the domination
% releation between two individual using constrained-domination.
%
% Return:
% domMat(N,N) : domination matrix
% domMat(p,q)=1 : p dominates q
% domMat(p,q)=-1 : q dominates p
% domMat(p,q)=0 : non dominate
%
% Copyright 2011 by LSSSSWC
% Revision: 1.0 Data: 2011-07-13
%*************************************************************************
N = size(obj, 1); %行个数(种群)
numObj = size(obj, 2);% 列个数(目标函数)
domMat = zeros(N, N);
for p = 1:N-1
for q = p+1:N
%*************************************************************************
% 1. p and q are both feasible
%*************************************************************************
%两个个体约束均为0的情况
if(nViol(p) == 0 && nViol(q)==0)
pdomq = false;
qdomp = false;
for i = 1:numObj
if( obj(p, i) < obj(q, i) ) % objective function is minimization!
pdomq = true; % p支配q
elseif(obj(p, i) > obj(q, i))
qdomp = true;
end
end
%只有两个对比个体所有目标函数都为1或0是才会产生支配,若存在不同目标函数个体支配相反情况,则两个个体不存在支配与被支配关系
if( pdomq && ~qdomp )
domMat(p, q) = 1; %表示p支配q
elseif(~pdomq && qdomp )
domMat(p, q) = -1; %表示q支配p
end
%*************************************************************************
% 2. p is feasible, and q is infeasible
%*************************************************************************
elseif(nViol(p) == 0 && nViol(q)~=0)
domMat(p, q) = 1;
%*************************************************************************
% 3. q is feasible, and p is infeasible
%*************************************************************************
elseif(nViol(p) ~= 0 && nViol(q)==0)
domMat(p, q) = -1;
%*************************************************************************
% 4. p and q are both infeasible
%*************************************************************************
else
if(violSum(p) < violSum(q))
domMat(p, q) = 1;
elseif(violSum(p) > violSum(q))
domMat(p, q) = -1;
end
end
end
end
#2) 等级划分
% The first front(rank = 1)
front(1).f = []; % There are only one field 'f' in structure 'front'.
% This is intentional because the number of individuals
% in the front is difference.
for i = 1:N
if( ind(i).np == 0 )
pop(i).rank = 1;
front(1).f = [front(1).f, i];
end
end
% Calculate pareto rank of each individuals, viz., pop(:).rank
fid = 1; %pareto front ID
while( ~isempty(front(fid).f) )
Q = [];
for p = front(fid).f
for q = ind(p).sp
ind(q).np = ind(q).np -1;
if( ind(q).np == 0 )
pop(q).rank = fid+1;
Q = [Q, q];
end
end
end
fid = fid + 1;
front(fid).f = Q;% 获取每个层次前沿的集合
end
front(fid) = []; % delete the last empty front set
4)选择操作-拥挤度计算
#1) 原理
NSGA-II为了解决NSGA算法中共享函数参数难以明确的缺点,选择了拥挤度距离的方式。该方法的基本思想是:
首先,需要计算某一特定解的密度,该密度值是通过计算沿该点两边沿每个目标函数的平均距离获得的。如下图所示,其距离等于相邻两个点构成矩形的矩形周长一般(两个目标函数情况下,且这个矩形应该是均一化的,归一化的目的:多个目标函数(可以看作是多维度)量纲不同,这样可以排除量纲的干扰。)。
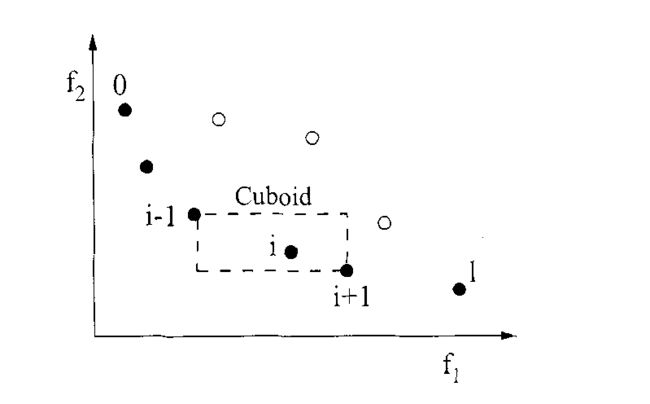
伪代码:

拥挤度距离计算完成后,通过之前非支配操作获取了各个体的等级排序和拥挤度距离,完成选择操作。具体实现原理如下。

#2)代码
拥挤度距离:
function pop = calcCrowdingDistance(opt, pop, front)
% Function: pop = calcCrowdingDistance(opt, pop, front)
% Description: Calculate the 'crowding distance' used in the original NSGA-II.
% Syntax:
% Parameters:
% Return:
%
% Copyright 2011 by LSSSSWC
% Revision: 1.0 Data: 2011-07-11
%*************************************************************************
numObj = length( pop(1).obj ); % number of objectives
for fid = 1:length(front)
idx = front(fid).f;
frontPop = pop(idx); % frontPop : individuals in front fid
numInd = length(idx); % nInd : number of individuals in current front
obj = vertcat(frontPop.obj);
obj = [obj, idx']; % objctive values are sorted with individual ID
% 获取每个rank下每个个体不同目标函数下的拥挤度距离,个体拥挤度为个目标函数拥挤度之和s
for m = 1:numObj
obj = sortrows(obj, m); %Sort the rows of A based on the values in the second column. When the specified column has repeated elements,
%the corresponding rows maintain their original order.
%对于每一个目标函数排序后的第一个和最后一个个体的距离设置为inf
colIdx = numObj+1;
pop( obj(1, colIdx) ).distance = Inf; % the first one
pop( obj(numInd, colIdx) ).distance = Inf; % the last one
minobj = obj(1, m); % the maximum of objective m
maxobj = obj(numInd, m); % the minimum of objective m
for i = 2:(numInd-1)
id = obj(i, colIdx);
pop(id).distance = pop(id).distance + (obj(i+1, m) - obj(i-1, m)) / (maxobj - minobj); %均一化
end
end
end
选择:
function newpop = selectOp(opt, pop)
% Function: newpop = selectOp(opt, pop)
% Description: Selection operator, use binary tournament selection.
%
% LSSSSWC, NWPU
% Revision: 1.1 Data: 2011-07-12
%*************************************************************************
popsize = length(pop);
pool = zeros(1, popsize); % pool : the individual index selected
randnum = randi(popsize, [1, 2 * popsize]);
j = 1;
for i = 1:2:(2*popsize)
p1 = randnum(i);
p2 = randnum(i+1);
if(~isempty(opt.refPoints))
% Preference operator (R-NSGA-II)
result = preferenceComp( pop(p1), pop(p2) );
else
% Crowded-comparison operator (NSGA-II)
result = crowdingComp( pop(p1), pop(p2) );
end
if(result == 1)
pool(j) = p1;
else
pool(j) = p2;
end
j = j + 1;
end
newpop = pop( pool );
function result = crowdingComp( guy1, guy2)
% Function: result = crowdingComp( guy1, guy2)
% Description: Crowding comparison operator.
% Return:
% 1 = guy1 is better than guy2
% 0 = other cases
%
% LSSSSWC, NWPU
% Revision: 1.0 Data: 2011-04-20
%*************************************************************************
if((guy1.rank < guy2.rank) || ((guy1.rank == guy2.rank) && (guy1.distance > guy2.distance) ))
result = 1;
else
result = 0;
end
可以看出随机选择的方式相对于轮盘赌选择来讲,更具有多样性,让概率小的最优解可以更好的被选择。
交叉操作:
NSGA-II交叉方式选择了matlab 多目标优化中的intermediate方式,具体原理我这里直接用代码表示。
fraction = 2.0 / nVar; % 交叉概率
function [child1, child2] = crsIntermediate(parent1, parent2, fraction, options)
% Function: [child1, child2] = crsIntermediate(parent1, parent2, fraction, options)
% Description: (For real coding) Intermediate crossover. (Same as Matlab's crossover
% operator)
% child = parent1 + rand * Ratio * ( parent2 - parent1)
% Parameters:
% fraction : crossover fraction of variables of an individual
% options = ratio
%
% LSSSSWC, NWPU
% Revision: 1.1 Data: 2011-07-13
%*************************************************************************
if( length(options)~=1 || ~isnumeric(options{1}))
error('NSGA2:CrossoverOpError', 'Crossover operator parameter error!');
end
ratio = options{1};
child1 = parent1;
child2 = parent2;
nVar = length(parent1.var);
crsFlag = rand(1, nVar) < fraction; %小于交叉概率的化则交叉
randNum = rand(1,nVar); % uniformly distribution
child1.var = parent1.var + crsFlag .* randNum .* ratio .* (parent2.var - parent1.var);
child2.var = parent2.var - crsFlag .* randNum .* ratio .* (parent2.var - parent1.var);
变异操作
变异采用了matlab多目标优化中的高斯函数变异方式,具体代码如下:
fraction = 2.0 / nVar;
function child = mutationGaussian( parent, opt, state, fraction, options)
% Function: child = mutationGaussian( parent, opt, state, fraction, options)
% Description: Gaussian mutation operator. Reference Matlab's help :
% Genetic Algorithm Options :: Options Reference (Global Optimization Toolbox)
% Parameters:
% fraction : mutation fraction of variables of an individual
% options{1} : scale. This paramter should be large enough for interger variables
% to change from one to another.
% options{2} : shrink
% Return:
%
% LSSSSWC, NWPU
% Revision: 1.1 Data: 2011-07-13
%*************************************************************************
%*************************************************************************
% 1. Verify the parameters.
%*************************************************************************
if( length(options)~=2)
error('NSGA2:MutationOpError', 'Mutation operator parameter error!');
end
%*************************************************************************
% 2. Calc the "scale" and "shrink" parameter.
%*************************************************************************
scale = options{1}; %scalar, the scale parameter determines the standard deviation of the random number generated.
shrink = options{2}; %scalar, [0,1]. As the optimization progress goes forward, decrease the mutation range (for example, shrink∈[0.5, 1.0]) is usually used for local search.
scale = scale - shrink * scale * state.currentGen / opt.maxGen;
lb = opt.lb;
ub = opt.ub;
scale = scale * (ub - lb);
%*************************************************************************
% 3. Do the mutation.
%*************************************************************************
child = parent;
numVar = length(child.var);
for i = 1:numVar
if(rand() < fraction)
child.var(i) = parent.var(i) + scale(i) * randn();
end
end
精英策略选择
原理:
这也是NSGA-II选择部分比较重要的部分,其原理是:首先,将父代与选择、交叉、变异产生的新子代共同构建一个群体,然后再进行非支配选择操作和等级划分(nsort函数),最后再进行等级优先选择,直到种群数量等于原种群个数。其中有2N种群个数到N种群的操作原理图如下。

代码:
function nextpop = extractPop(opt, combinepop)
% Function: nextpop = extractPop(opt, combinepop)
% Description: Extract the best n individuals in 'combinepop'(population
% size is 2n).
%
% LSSSSWC, NWPU
% Revision: 1.1 Data: 2011-07-12
%*************************************************************************
popsize = length(combinepop) / 2;
nextpop = combinepop(1:popsize); %just for initializing
rankVector = vertcat(combinepop.rank);
n = 0; % individuals number of next population
rank = 1; % current rank number
idx = find(rankVector == rank);
numInd = length(idx); % number of individuals in current front
while( n + numInd <= popsize )
nextpop( n+1 : n+numInd ) = combinepop( idx );
n = n + numInd;
rank = rank + 1;
idx = find(rankVector == rank);
numInd = length(idx);
end
% If the number of individuals in the next front plus the number of individuals
% in the current front is greater than the population size, then select the
% best individuals by corwding distance(NSGA-II) or preference distance(R-NSGA-II).
if( n < popsize )
if(~isempty(opt.refPoints))
prefDistance = vertcat(combinepop(idx).prefDistance);
prefDistance = [prefDistance, idx];
prefDistance = sortrows( prefDistance, 1);
idxSelect = prefDistance( 1:popsize-n, 2); % Select the individuals with smallest preference distance
nextpop(n+1 : popsize) = combinepop(idxSelect);
else
distance = vertcat(combinepop(idx).distance);
distance = [distance, idx];
distance = flipud( sortrows( distance, 1) ); % Sort the individuals in descending order of crowding distance in the front.
idxSelect = distance( 1:popsize-n, 2); % Select the (popsize-n) individuals with largest crowding distance.
nextpop(n+1 : popsize) = combinepop(idxSelect);
end
end
先到这里吧!后续再加入偏好选择的讲解!祝大家能早日摆脱冠状病毒这个噩梦,中国加油!