使用k-近邻算法改进约会网站的配对效果
有关k-近邻的理论知识以及算法实现,可查看上一篇博文k-近邻
此文以一个实际例子:使用k-近邻算法改进约会网站的配对效果。
在约会网站上使用k-近邻算法:
1、收集数据:提供文本文件
2、准备数据:使用python解析文本文件
3、测试算法:将数据集分为训练数据和测试数据。用训练数据训练分类器,用测试数据集评估分类器。
4、使用算法:输入一些特征数据来判断是否是自己想要的结果。
使用k-近邻算法改进约会网站的配对效果
数据存放在文本文件datingTestSet2.txt中,每一个样本数据占一行,总共有1000行。样本主要有三个特征。
将特征数据输入到分类器之前,必须将待处理数据的格式变为分类器可接受的格式。故在kNN.py文件中创建名为file2matrix函数,用来处理输入格式问题。该函数的输入:文件名字符串;输出:训练样本矩阵和类标签向量
一、准备数据:从文本文件中解析数据,处理文件格式
def file2matrix(filename):
###1、得到文件行数
fr = open(filename) ###打开文件
arrayOLines = fr.readlines() ###readlines()用于读取所有行,并返回包含行的列表
numberOfLines = len(arrayOLines) ###读取文件的行数
###2、创建返回的NumPy矩阵
returnMat = zeros((numberOfLines, 3)) ### 创建以0填充的矩阵,且与特征数据集匹配,训练样本矩阵。
###3、解析文件数据到列表
classLabelVector = []#类标签向量
index = 0
for line in arrayOLines:
line = line.strip() ###删除空白符,这里截取掉所有回车字符
listFromLine = line.split('\t') ###对于每一行,按照制表符切割字符串,将上一步得到的整行数据分割成一个元素列表。
returnMat[index, :] = listFromLine[0:3] ###选取前三个元素,将它们存储到特征矩阵中。
classLabelVector.append(int(listFromLine[-1])) ###将列表的最后一列存储到类别标签向量中。int是告诉解释器,列表中存储的元素值为整型。
index += 1
return returnMat, classLabelVector#返回的是训练样本矩阵和类标签向量。在命令提示符下输入命令:
import kNN
>>> datingDataMat, datingLabels=kNN.file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt')
>>> datingDataMat
>>> datingLabels
补充:
**1.**read()函数
read(size):从文件当前位置起读取size个字节(如果文件结束,就读取到文件结束为止),如果size是负值或省略,读取到文件结束为止,返回结果是一个字符串。readline():readline()每次读取一行,当前位置移到下一行readlines():读取整个文件所有行,保存在一个列表(list)变量中,每行作为一个元素读取文本所有内容,一般配合for
in使用。2.
strip()函数
声明: s为字符串,rm为要删除的字符序列s.strip(rm)删除s字符串中开头、结尾处,位于 rm删除序列的字符s.lstrip(rm)删除s字符串中开头处,位于 rm删除序列的字符s.rstrip(rm)删除s字符串中结尾处,位于
rm删除序列的字符
当rm为空时,默认删除空白符(包括’\n’, ‘\r’, ‘\t’, ’ ‘)
这里的rm删除序列是只要边(开头或结尾)上的字符在删除序列内,就删除掉。
3.
s.split('\t')s为字符串 对于每一行,按照制表符切割字符串,将上一步得到的整行数据分割成一个元素列表。详情可参考:
http://blog.csdn.net/Holyang_1013197377/article/details/49205065
二、准备数据:归一化数值
回到那个数据集,第一列代表的特征数值远远大于其他两项特征,这样在求距离时,这个特征就会占很大的比重,使两点的距离很大程度上取决于这个特征,这当然是不公平的,如果我们认为三种特征都同等地重要,我们就需要三个特征都均平地决定距离,所以我们要对数据进行处理,希望处理之后既不影响相对大小又可以不失公平。
常采用的方法是:归一化:将取值范围处理为0到1或者-1到1之间。下面的公式可以将任意取值范围的特征值转化为0到1区间内:
newValue=(oldValue−min)/(max−min)
归一化特征值的代码为:
#归一化特征值
def autoNorm(dataSet):
minVals=dataSet.min(0)###获取每列中的最小值,1x3个值
maxVals=dataSet.max(0)###获取每列中的最大值
ranges=maxVals-minVals
normDataSet=zeros(shape(dataSet)) ###shape()查看矩阵或数组的维数,创建一个与dataSet结构一样的返回矩阵(初始为0)
m=dataSet.shape[0]###查看dataSet的第一维度的长度
normDataSet=dataSet-tile(minVals, (m, 1))###因为特征矩阵都是1000x3个值,而minVals的值是1x3,故将变量内容复制成输入特征矩阵同样大小的矩阵。
normDataSet=normDataSet/tile(ranges, (m, 1))
return normDataSet, ranges, minVals在python命令提示符下,执行autoNorm函数:
>>> import kNN
>>> datingDataMat, datingLabels =kNN.file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt')
>>> datingDataMat
>>> normMat, ranges, minVals=kNN.autoNorm(datingDataMat)
>>> normMat
>>>> ranges
>>> minVals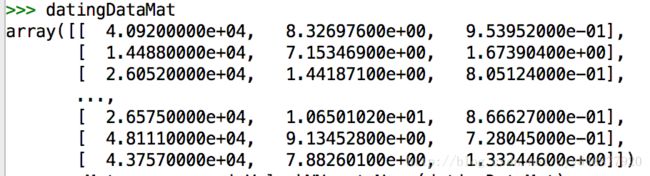

补充:
dataSet.min(0):获取每列中的最小值;
dataSet.shape[0]:查看dataSet的第一维度的长度。即返回行数,即查看每一列中有多少个元素;
dataSet.shape[1]:返回列数,即查看每一行中有多少个元素;
shape(dataSet): 查看矩阵或数组的维数
tile(minVals, (m, 1)):因为特征矩阵都是1000x3个值,而minVals的值是1x3,故将变量内容复制成输入特征矩阵同样大小的矩阵
linalg.solve(matA, matB): Numpy库中的矩阵除法
三、验证分类器
机器学习算法一个很重要的工作就是评估算法的正确率,通常提供已有数据的90%作为训练样本,来训练分类器,而使用其余的10%数据去测试分类器,检测分类器的正确率。
用错误率来检测分类器性能。对于分类器来说,错误率就是分类器给出错误结果的次数除以测试数据的总数。
分类器针对约会网站的测试代码:
###分类器针对约会网站的测试代码
def datingClassTest():
hoRatio = 0.10 # 测试数据集所占比例
datingDataMat, datingLabels = file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt') # 读取数据,输出样本矩阵和类标签向量
normMat, ranges, minVals = autoNorm(datingDataMat) # 将样本特征矩阵进行归一化
m = normMat.shape[0] # 查看归一化特征矩阵第一维度的长度
numTestVecs = int(m * hoRatio) # 测试集的数量
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
# 利用训练数据训练分类器,再用分类器预测测试集的结果
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "the total error rate is : %f" % (errorCount / float(numTestVecs))在python命令提示符下,重新加载kNN模块,执行分类器测试程序:
>>> import kNN
>>> kNN.datingClassTest()结果:the total error rate is : 0.050000。
四、约会网站预测函数
###预测函数
def classifyPerson():
resultList=['一点也不喜欢', '喜欢一点点', '非常喜欢']
percentTats=float(raw_input("看视频所占的时间"))
ffMiles=float(raw_input("每年获得的飞行常客里程数"))
iceCream=float(raw_input("每周消耗的冰淇淋公升数"))
datingDataMat, datingLabels = file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt') # 读取数据,输出样本矩阵和类标签向量
normMat, ranges, minVals = autoNorm(datingDataMat) # 样本矩阵转换成归一化
inArr=array([ffMiles, percentTats, iceCream])#待分类特征向量
classifierResult = classify((inArr-minVals)/ranges, normMat, datingLabels, 3)
#归一化的待分类特征向量,归一化的训练特征向量以及标签
print 'you will probably like this person: ', resultList[classifierResult - 1]
整体的代码如下:
-*- coding: utf-8 -*-
from numpy import * # numpy 是科学计算包
import operator # 运算符模块
def classify(inX, dataSet, labels, k): # inX是待分类的输入向量,dataSet是输入的训练样本集,标签向量为labels。
# 1、首先计算当前点与已知类别数据集中的点的距离。
dataSetSize = dataSet.shape[0] # 返回数据集的行数,shape[1]返回数据集的列数
diffMat = tile(inX, (dataSetSize, 1)) - dataSet # tile的功能是重复某个数组。比如tile(A,n),功能是将数组A重复n次,构成一个新的数组.
sqDiffMat = diffMat ** 2 # 每个元素的平方
sqDistances = sqDiffMat.sum(axis=1) # 行求和
distances = sqDistances ** 0.5 # 待分类向量与输入的训练样本集中数据的距离
# 2、下面进行排序:np.argsort(x)升序排序;np.argsort(-x)降序排序。
sorteDistIndicies = distances.argsort() # np.argsort(x, axis=0)按列排序,返回的是原数组从小到大排序的下标值;np.argsort(x, axis=1)按行排序;默认按列排序。
# 3、选择距离最小的k个点,并获得了距离最近的k个点对应的标签,以及每个标签对应的点的个数。
classCount = {}
for i in range(k):
voteIlabel = labels[sorteDistIndicies[i]] # 返回距离最近的第i个点的标签值
classCount[voteIlabel] = classCount.get(voteIlabel,
0) + 1 # get(key, default)返回字典中指定健的值,没有则返回默认值default,这里没有的话返回0+1。
# 例如距离最近第近的标签计作vote1label,则由于空字典内肯定不含vote1label(健)对应的值,故字典中加入元素vote1label:1;
# 若距离第2近的标签vote2label如果与vote1label相同,则get函数返回字典中vote1label对应的值1,+1=2变为vote1label的新值;
# 若距离第2近的标签vote2label如果与vote1label不同,则由于字典中没有vote2label这样的健,故get函数返回0,+1=1是健vote2label对应的值;
# 并将vote2label:1这个健值对加入字典中;。。。依次下去,便获得了距离最近的k个点对应的标签,以及每个标签对应的点的个数!
# 4、排序
# sorted() 方法,对list或者iterable进行排列;sorted(iterable, cmp, key, reverse)
# iterable指定要排序的list或者iterable;dict.items()返回的是一个完整的列表,而dict.iteritems()返回的是一个生成器(迭代器)。
# cmp为函数,指定排序时进行比较的函数,可以指定一个函数或者lambda函数,
# key为函数,指定取待排序元素的哪一个域进行排序;operator.itemgetter(1)定义了一个函数,获取对象的第1个域的值。这里第一个域是指字典中的值。
# reverse默认为false(升序排列),定义为True时将按降序排列。
sortedClassCount = sorted(classCount.iteritems(), key=operator.itemgetter(1),
reverse=True) # 指定迭代器iterable的第一个域进行降序排序。
return sortedClassCount[0][0]
def creatDateSet():
group = array([[1.0, 1.1], [1.0, 1.0], [0, 0], [0, 0.1]])
labels = ['A', 'A', 'B', 'B']
return group, labels
###使用k-近邻算法改进约会网站的配对效果
# 1、准备数据:从文本文件中解析数据,处理文件格式
def file2matrix(filename):
###1、得到文件行数
fr = open(filename) ###打开文件
arrayOLines = fr.readlines() ###readlines()用于读取所有行,并返回包含行的列表
numberOfLines = len(arrayOLines) ###读取文件的行数
###2、创建返回的NumPy矩阵
returnMat = zeros((numberOfLines, 3)) ### 创建以0填充的矩阵,且与特征数据集匹配
###3、解析文件数据到列表
classLabelVector = []
index = 0
for line in arrayOLines:
line = line.strip() ###截取掉所有回车字符
listFromLine = line.split('\t') ###对于每一行,按照制表符切割字符串,将上一步得到的整行数据分割成一个元素列表。
returnMat[index, :] = listFromLine[0:3] ###选取前三个元素,将它们存储到特征矩阵中。
classLabelVector.append(int(listFromLine[-1])) ###将列表的最后一列存储到类别标签向量中。int是告诉解释器,列表中存储的元素值为整型。
index += 1
return returnMat, classLabelVector
### 归一化特征值
def autoNorm(dataSet):
minVals = dataSet.min(0) ###获取每列中的最小值,1x3个值
maxVals = dataSet.max(0) ###获取每列中的最大值
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet)) ###shape()查看矩阵或数组的维数,创建一个与dataSet结构一样的返回矩阵(初始为0)
m = dataSet.shape[0] ###查看dataSet的第一维度的长度
normDataSet = dataSet - tile(minVals, (m, 1)) ###因为特征矩阵都是1000x3个值,而minVals的值是1x3,故将变量内容复制成输入特征矩阵同样大小的矩阵。
normDataSet = normDataSet / tile(ranges, (m, 1))
return normDataSet, ranges, minVals
###分类器针对约会网站的测试代码
def datingClassTest():
hoRatio = 0.10 # 测试数据集所占比例
datingDataMat, datingLabels = file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt')
# 读取数据,输出样本矩阵和类标签向量
normMat, ranges, minVals = autoNorm(datingDataMat) # 转换成归一化特征值
m = normMat.shape[0] # 查看归一化特征矩阵第一维度的长度
numTestVecs = int(m * hoRatio) # 测试集的数量
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 3)
# 利用训练数据训练分类器,再用分类器预测测试集的结果
if (classifierResult != datingLabels[i]):
errorCount += 1.0
print "the total error rate is : %f" % (errorCount / float(numTestVecs))
###预测函数
def classifyPerson():
resultList=['一点也不喜欢', '喜欢一点点', '非常喜欢']
percentTats=float(raw_input("看视频所占的时间"))
ffMiles=float(raw_input("每年获得的飞行常客里程数"))
iceCream=float(raw_input("每周消耗的冰淇淋公升数"))
datingDataMat, datingLabels = file2matrix('/Users/lb1/Desktop/小学伴-机器学习/机器学习实战源代码/machinelearninginaction/Ch02/datingTestSet2.txt')
# 读取数据,输出样本矩阵和类标签向量
normMat, ranges, minVals = autoNorm(datingDataMat) # 转换成归一化特征值
inArr=array([ffMiles, percentTats, iceCream])#待分类特征向量
classifierResult = classify((inArr-minVals)/ranges, normMat, datingLabels, 3)
#归一化的待分类特征向量,归一化的训练特征向量以及标签
print 'you will probably like this person: ', resultList[classifierResult - 1]