java本地使用JDBC连接Spark SQL(HiveServer2)
根据Spark官网所述,Spark SQL实现了Thrift JDBC/ODBC server:
The Thrift JDBC/ODBC server implemented here corresponds to the HiveServer2 in Hive 1.2.1 You can test the JDBC server with the beeline script that comes with either Spark or Hive 1.2.1.
这就意味着我们可以像HIVE那样通过JDBC远程连接Spark SQL发送SQL语句并执行。
1、准备工作
在这之前需要先将${HIVE_HOME}/conf/hive-site.xml 拷贝到${SPARK_HOME}/conf目录下,由于我的hive配置了元数据信息存
储在MySQL中,所以Spark在访问这些元数据信息时需要mysql连接驱动的支持。添加驱动的方式有三种:
第一种是在${SPARK_HOME}/conf目录下的spark-defaults.conf中添加:spark.jars /opt/lib/mysql-connector-java-5.1.26-bin.jar
第二种是通过 添加 :spark.driver.extraClassPath /opt/lib2/mysql-connector-java-5.1.26-bin.jar 这种方式也可以实现添加多个依赖jar,比较方便
第三种是在运行时 添加 --jars /opt/lib2/mysql-connector-java-5.1.26-bin.jar
做完上面的准备工作后,spark sql和Hive就继承在一起了,spark sql可以读取hive中的数据
2、启动thrift
在spark根目录下执行:./sbin/start-thriftserver.sh 开启thrift服务器
start-thriftserver.sh 和spark-submit的用法类似,可以接受所有spark-submit的参数,并且还可以接受--hiveconf 参数。
不添加任何参数表示以local方式运行。
默认的监听端口为10000
3、用beeline测试
在spark根目录下执行:
./bin/beeline
连接 JDBC/ODBC server
beeline> !connect jdbc:hive2://localhost:10000
连接后会提示输入用户名和密码,用户名可以填当前登陆的linux用户名,密码为空即可,连接成功如下图所示:

执行show tables;
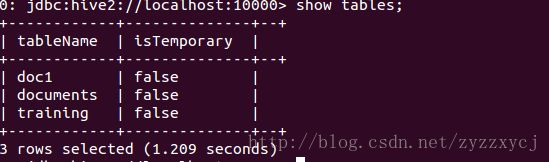
可以看到之前我在hive中使用的三张表
看一下doc1的表结构:

执行查询操作:

4、在java代码中用jdbc连接
接下来打开eclipse用jdbc连接hiveserver2,连接hive的步骤同样如此。
新建一个maven项目:
在pom.xml添加以下依赖:
(注意!!hive-jdbc的版本一定要和服务器上的hive版本对应,jdk版本和本地机器的对应 这边以1.8为例,不然会报错!!!)
(注意!!hive没有提供-version的版本查看命令,查看hive版本请移步:
http://blog.csdn.net/zyzzxycj/article/details/79268754)
org.apache.hive
hive-jdbc
1.1.0
org.apache.hadoop
hadoop-common
2.4.1
jdk.tools
jdk.tools
1.8
然后将jdk中的${JAVA_HOME}/lib/tools.jar拷贝到当前工程目录下,在运行以下代码 手动安装:
(注意!!-Dversion=1.* 这边的版本对应)
mvn install:install-file -DgroupId=jdk.tools -DartifactId=jdk.tools -Dpackaging=jar -Dversion=1.8 -Dfile=tools.jar -DgeneratePom=true
等待maven加载完成后,进入下一步:
在编写jdbc连接代码之前要了解连接hiveserver2的相关参数:
驱动:org.apache.hive.jdbc.HiveDriver
url:jdbc:hive2://你的hive地址:端口号/数据库名
用户名:root (启动thriftserver的linux用户名)
密码:“”(默认密码为空)
import java.sql.*;
public class test_Spark_JDBC {
public static void main(String[] args) throws SQLException {
String url = "jdbc:hive2://你的hive地址:端口号/数据库名";
try {
Class.forName("org.apache.hive.jdbc.HiveDriver");
} catch (ClassNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
Connection conn = DriverManager.getConnection(url, "root", "");
Statement stmt = conn.createStatement();
String sql = "SELECT name,price FROM instancedetail_test limit 10";
String sql2 = "desc instancedetail_test";
String sql3 = "SELECT count(*) FROM instancedetail_test";
ResultSet res = stmt.executeQuery(sql);
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getDouble(2));
}
res = stmt.executeQuery(sql2);
res = stmt.executeQuery(sql3);
// while (res.next()) {
// System.out.println("id: " + res.getInt(1) + "\ttype: " + res.getString(2) + "\tauthors: " + res.getString(3) + "\ttitle: " + res.getString(4) + "\tyear:" + res.getInt(5));
// }
}
}
至此 连接成功! 有错误或疑问欢迎评论~