FPGA硬件加速原理性学习001----随手记一下
学习生涯需要仪式感-------以写博客的方式留作记录。
于2019年3月开始入门FPGA硬件加速方向,冲冲冲!~
1、余同学的设计,初代目设计
参考了下面这篇博客
https://blog.csdn.net/Setul/article/details/83827980
先找篇博客看看浙大的余大佬是怎么做的 T T
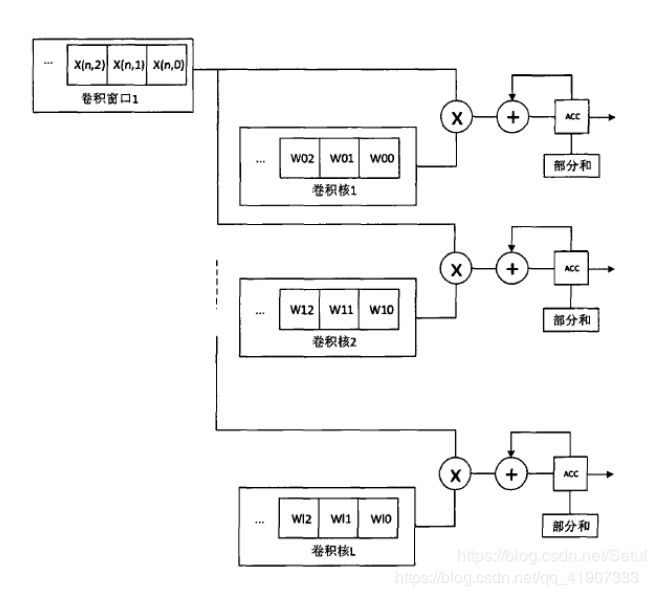
首先看卷积部分的并行加速怎么来的
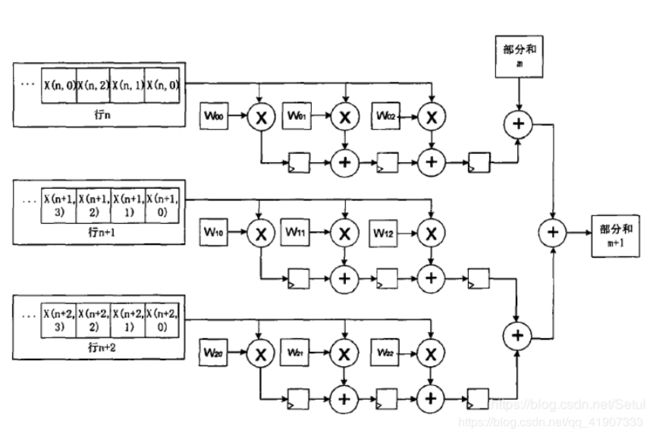
以第一行为例
第一个时钟: X(n,0)*W00 图里有个寄存器,应该是结果放里面寄存了
第二个时钟: X(n,1)*W01 + X(n,0)*W00 && X(n,1)*W00 即下一次卷积窗口的第一个计算值。(这种顺序看着有点难受,从右往左的感觉T T)咱也没搞懂这个结果存哪。
第三个时钟:第三级流水线执行X(n, 2)*W02 + X(n, 1)*W01 + X(n, 0)*W00,第一级流水线执行X(n, 2)*W00,第二级流水线执行X(n, 1)*W00 + X(n, 2)*W01。以此类推。
(这里我理解的流水线就是这一行的三个分叉叉。
X(n,2)进来的时候 ,第一个分支执行X(n, 2)*W00,就是所谓的第一级流水线。第二个分支执行X(n, 1)*W00 + X(n, 2)*W01,其中X(n, 1)*W00是第二个时钟计算出来的结果,然后第三个分支就是X(n, 2)*W02 + X(n, 1)*W01 + X(n, 0)*W00 )
看到这感觉到的好处 1、数据得到了复用 2、计算结果以后也能复用
但是该怎么个调度还不太清楚。卷积核的大小是否会影响计算的并行度??
然后说了下相同特征图卷积窗口间并行实现分析
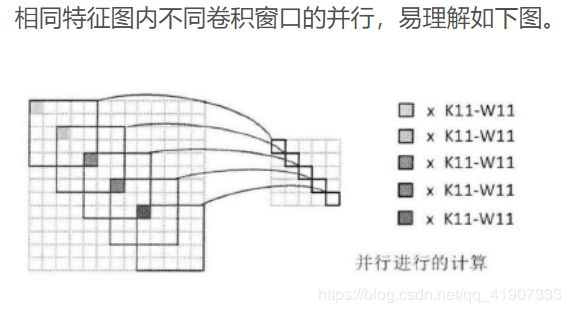
来了这么一个图,说实话,有点懵比。我猜这个图的意思是每个卷积窗口的结果能复用。
还有个图,Emmmmm 没太明白想表达啥。
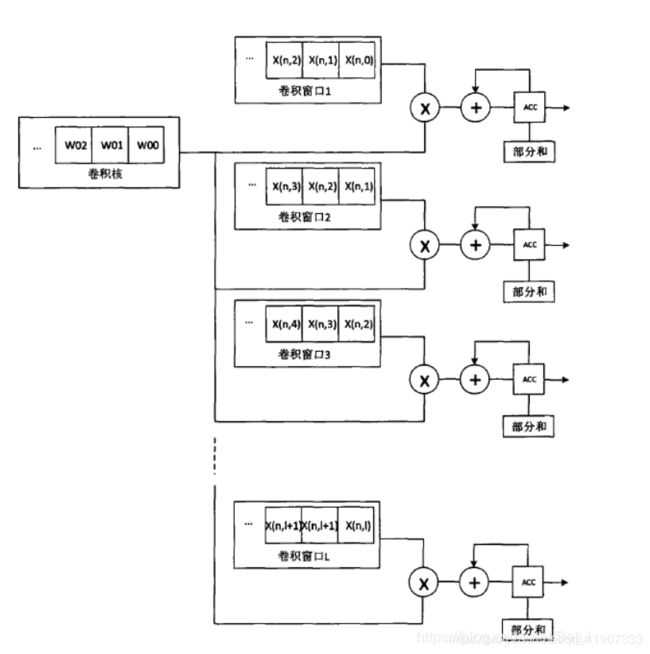
强行分析一波: 就拿这个图来看,咱就先当是个3*3的卷积核,这是是对卷积核的第一行做操作。 相同特征图内话卷积核参数一样没得问题,如果是单通道特征图大小是H*W的话,然后每行的并行度是L。。 这么做的话好像没体现计算结果的复用?
然后是不同输入特征图卷积窗口并行
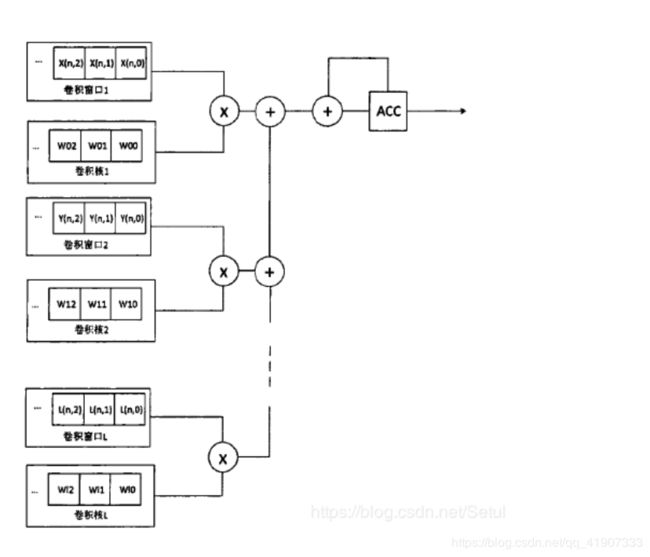
额 不应该是一个卷积核对每个通道卷积然后求和拍成一张,不过这么画也没问题。
不同输出特征图并行
暂时还没太看明白其深意,没错就是菜。
FPGA加速器设计
这里好像是一个重头戏的样子,先看一下整体设计

发现看了没啥用,这俩箭头画的有点随意。。
卷积计算单元
或者这才是重头戏?
CNN层间运算具有独立性且各层运算具有高度相似性。
因此可通过复用单层运算资源来实现完整的CNN神经网络计算,在实现过程中只需实现单层的卷积计算结构。
来张高糊的图
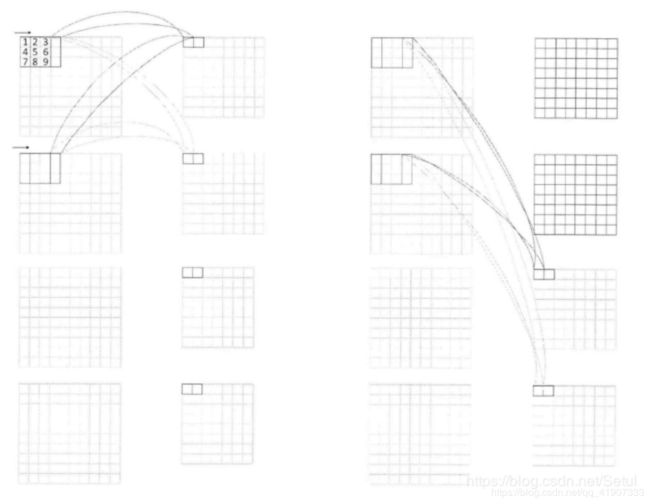
上图是计算过程。在该实例中,有4副输入特征图,4副输出特征图,核的大小为3*3,上图中分左边阶段和右边阶段。采用并行性组合的方式,输出特征图之间的并行度为2,即同时计算两个输出特征图;输入特征图之间的并行度为2,即同时计算两个输入特征图;同一输入特征图不同卷积窗口的并行度为2,即同时计算两个卷积窗口。
就是相当于 输入的时候两张图一起算,每张图一次算临近的两个卷积窗口。输出的时候同理。
但是这里的输入、输出特征图意义不够清晰,还得细看论文才能明白。
日后明白需补上 补丁1
2、菜同学的设计
先看一下卷积加速层的伪代码是怎么写的

这个循环需要进行展开,已变成一个通用的计算架构。
注意:这里的Sy Sx是步长。
比如对于输出通道,可以这么展开。

ceil的功能是:返回大于或者等于指定表达式的最小整数
这样的话并行度就是`k, 然后根据不同层的要求。 外边的循环的次数可以变换,实现一个通用框架的目的。
整个代码全部以这种思想展开的话就是下图

这里是以输入输出通道做并行操作 。输入K个并行计算 输出K个并行计算,那么算法就是K2的并行度。
那这里为什么不用卷积核的宽高做并行呢?而是使用通道做并行?
卷积核的大小是有很多变化的,如果对3*3的卷积核做了个并行,9个乘法器同时并行操作。
那么对于一个6*6的卷积核,是可以用4个并行的3*3卷积核来完成,这样利用率还可以说是100%
如果是5*5的话, 我们还得用4个3*3的单元来做,但这样的利用率就变成了25/36 。利用率会降低。如果是1*1的卷积核的话,那基本也没啥利用率了。而且我感觉沿着卷积核的宽高做的话并行度也肯定赶不上按通道来的。因为卷积的输入输出通道数是很多的,资源够可以做到很高。
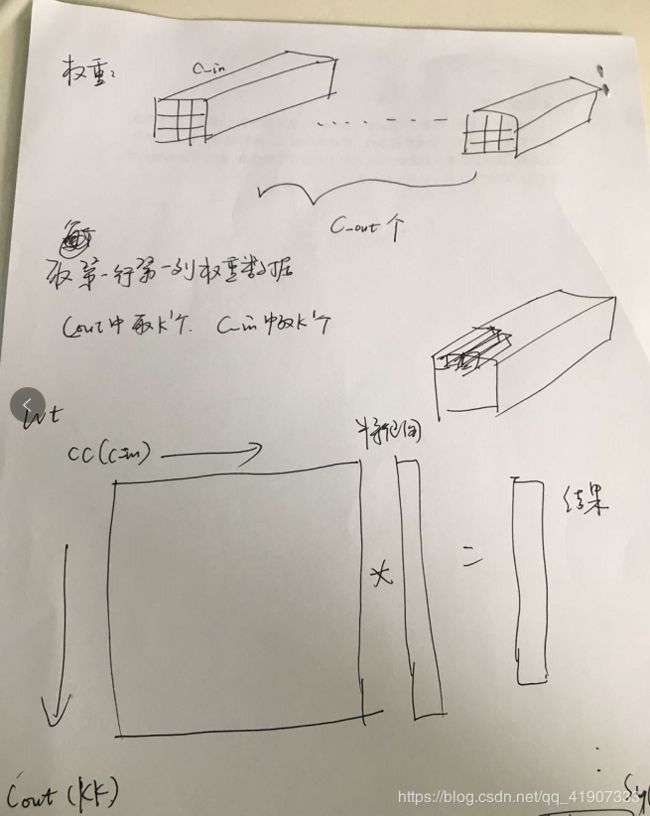
如果这里的`K是16的话,看一下上图的红色框。
我们 就可以理解为是一个16*16的矩阵X 16*1的向量。 得到一个16*1的向量。

这一部分可以做成一个固定的硬件, 用K^2个乘法器。
我们希望这个乘法器阵列每个周期都可以运算,每个周期都要加载特征,数据。对于特征图的话K*16(假设我们的数据是int16的),需要256bit位宽的总线,输出也是如此。但如果我们要加载权重矩阵的话,那数据总线的位宽就很 夸张了16*256 = 4096了,这会对后端布局和布局布线等造成很大的挑战。
所以这时候,又回到了类似第一个余同学的思路,要对这个大的权重数据充分利用,利用完了他然后再一脚踢开。
所以再上面那个矩阵乘法运算的时候,权重数据不动,变输入特征图数据。 这时候比如我们输入第一行第一列的通道数值。下一次 输入第一行第二列的通道特征图的数据,虽然这一次的值可能要以后才会用得上。然后在下一次第一行第三列的。
这样做法的好处是不用反复加载特征图数据,不然如果是3*3的话 9个权重图数据得来回加载,就会很不方便,拖累速度。可以再看一下代码,就能理解为什么卷积核的循环会放在更外边一层,以及为什么这一层是PP循环。

这里的权重图就是没有变化的,感觉给力噢!蔡同学牛逼!(主要要理解卷积的过程,还有其中一些步骤是可以调换顺序的)
这样就减少了权重数据的更新速度。
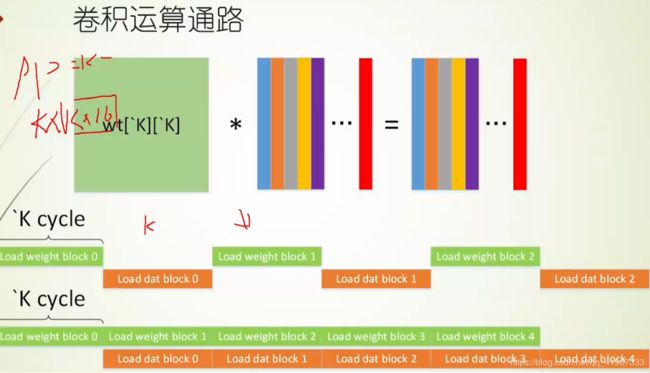
为了进一步提高效率 ,来一个乒乓操作,来俩权重缓存区。 加载权重图的时候也一边数据运算。这样的话效率就比较高了~好像也不算乒乓,就是个流水线模式。