Hadoop,Zookeeper,Kafka 高可用集群搭建
高可用集群搭建
1. 事先准备
我们需要5台虚拟机或者5台服务器,它们的网络需要互通,并且需要配置hosts和各主机间免密登录等操作,以及相应脚本文件,具体详情请查阅以下博客1-5节还有一些相应脚本编写的章节:
hadoop,zk,kafka简单集群搭建
准备好这些之后我们就可以开始了
2. 安装jdk
一、先解压安装包
cd /opt/install/
[root@jerry1 install]# ls
hadoop-2.6.0-cdh5.14.2.tar.gz kafka_2.11-2.0.0.tgz
jdk-8u111-linux-x64.tar.gz zookeeper-3.4.5-cdh5.14.2.tar.gz
[root@jerry1 install]# tar -zxf jdk-8u111-linux-x64.tar.gz -C /opt/bigdata/
[root@jerry1 install]# cd /opt/bigdata/
[root@jerry1 bigdata]# mv jdk1.8.0_111/ jdk180
二、将解压好的jdk传输给其他节点
xrsync jdk180
三、配置环境变量
1.创建配置文件
cd /etc/profile.d
touch env.sh
vi env.sh
2.加入jdk配置
export JAVA_HOME=/opt/bigdata/jdk180
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
3.给集群中所有其他主机传输一下env.sh配置文件
xrsync env.sh
4.给集群中所有主机source一下配置文件,使它生效,所有主机的jdk就都安装完成了。
3. 安装hadoop
一、解压hadoop
[root@jerry1 install]# tar -zxf hadoop-2.6.0-cdh5.14.2.tar.gz -C /opt/bigdata/
[root@jerry1 install]# mv /opt/bigdata/hadoop-2.6.0-cdh5.14.2/ /opt/bigdata/hadoop260
二、修改hadoop中所有配置文件中的jdk路径
进入hadoop的etc文件夹中hadoop文件夹中,对一下几个文件进行修改
vi hadoop-env.sh

vi mapred-env.sh

vi yarn-env.sh

三、配置hdfs配置文件
我们按照下图来进行配置

配置 core-site.xml ,配置了namenode所在节点,在configuration里面添加新内容。
vi core-site.xml
fs.defaultFS</name>
hdfs://mycluster</value>
</property>
hadoop.tmp.dir</name>
/opt/bigdata/hadoop260/hadoopdata</value>
</property>
ha.zookeeper.quorum</name>
jerry1:2181,jerry2:2181,jerry3:2181,jerry4:2181,jerry5:2181</value>
</property>
</configuration>
配置了hdfs-site.xml,配置了双namenode节点以及失败的切换。
vi hdfs-site.xml
dfs.replication</name>
1</value>
</property>
dfs.nameservices</name>
mycluster</value>
</property>
dfs.ha.namenodes.mycluster</name>
nn1,nn2</value>
</property>
dfs.namenode.rpc-address.mycluster.nn1</name>
jerry1:8020</value>
</property>
dfs.namenode.rpc-address.mycluster.nn2</name>
jerry2:8020</value>
</property>
dfs.namenode.http-address.mycluster.nn1</name>
jerry1:50070</value>
</property>
dfs.namenode.http-address.mycluster.nn2</name>
jerry2:50070</value>
</property>
dfs.namenode.shared.edits.dir</name>
qjournal://jerry3:8485;jerry4:8485;jerry5:8485/mycluster</value>
</property>
dfs.client.failover.proxy.provider.mycluster</name>
org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
dfs.ha.fencing.methods</name>
sshfence</value>
</property>
dfs.ha.fencing.ssh.private-key-files</name>
/root/.ssh/id_rsa</value>
</property>
dfs.journalnode.edits.dir</name>
/opt/bigdata/hadoop260/ha/journalnode/edits</value>
</property>
dfs.ha.automatic-failover.enabled </name>
true</value>
</property>
dfs.permissions</name>
false</value>
</property>
配置了mapred-site.xml,配置了MapReduce任务监控节点
cp mapred-site.xml.template mapred-site.xml
vi mapred-site.xml
mapreduce.framework.name</name>
yarn</value>
</property>
mapreduce.jobhistory.address</name>
jerry1:10020</value>
</property>
mapreduce.jobhistory.webapp.address</name>
jerry1:19888</value>
</property>
</configuration>
配置yarn-site.xml,配置了双ResourceManager节点以及失败切换
vi yarn-site.xml
<!-- Site specific YARN configuration properties -->
<!-- reducer获取数据方式 -->
yarn.nodemanager.aux-services</name>
mapreduce_shuffle</value>
</property>
yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
yarn.resourcemanager.ha.enabled</name>
true</value>
</property>
yarn.resourcemanager.cluster-id</name>
cluster1</value>
</property>
yarn.resourcemanager.ha.rm-ids</name>
rm1,rm2</value>
</property>
yarn.resourcemanager.hostname.rm1</name>
jerry3</value>
</property>
yarn.resourcemanager.hostname.rm2</name>
jerry4</value>
</property>
yarn.resourcemanager.webapp.address.rm1</name>
jerry3:8088</value>
</property>
yarn.resourcemanager.webapp.address.rm2</name>
jerry4:8088</value>
</property>
yarn.resourcemanager.recovery.enabled</name>
true</value>
</property>
yarn.resourcemanager.zk-address</name>
jerry1:2181,jerry2:2181,jerry3:2181,jerry4:2181,jerry5:2181</value>
</property>
<!-- 日志聚集功能使用 -->
yarn.log-aggregation-enable</name>
true</value>
</property>
<!-- 日志保留时间设置7天 -->
yarn.log-aggregation.retain-seconds</name>
604800</value>
</property>
</configuration>
配置slaves,这个配置了datanode所在节点
vi slaves
jerry3
jerry4
jerry5
四、配置环境变量
vi /etc/profile.d/env.sh
export HADOOP_HOME=/opt/bigdata/hadoop260
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
五、将环境变量文件发送到集群主机
xrsync /etc/profile.d/env.sh
六、各个主机都要source文件,才可以生效
source /etc/profile.d/env.sh
七、创建data和namenode同步文件夹
mkdir hadoopdata
mkdir -p ha/journalnode/edits
八、将hadoop发送到各主机
xrsync /opt/bigdata/hadoop260
九、格式化hadoop的Namenode
现在还不能启动hadoop,得先安装zookeeper,等zookeeper安装完,就可以开始初始化hadoop了。
4. 安装zookeeper
一、zookeeper解压
tar -zxf zookeeper-3.4.5-cdh5.14.2.tar.gz -C /opt/bigdata/
cd /opt/bigdata
mv zookeeper-3.4.5-cdh5.14.2/ zk345
二、创建zkData,写入当前节点id
mkdir zkData
cd ./zkData
touch myid
vi myid
三、只需要写入当前id即可,这里jerry1我就写1
1
四、修改zookeeper配置文件
cd /conf
cp zoo_sample.cfg zoo.cfg
vi zoo.cfg
五、配置data路径

六、新增server,根据你的虚拟机和之前配置的myid来新增,我新增的是1,2,3,4,5个server(位置随便放zoo.cfg中哪里)
server.1=jerry1.2287:3387
server.2=jerry2.2287:3387
server.3=jerry3.2287:3387
server.4=jerry4.2287:3387
server.5=jerry5.2287:3387
七、将zookeeper发送到集群各主机,并根据主机改变zkData中myid内的值
vi myid
jerry2: 2
jerry3: 3
jerry4: 4
jerry5: 5
八、配置环境变量
vi /etc/profile.d/env.sh
九、添加以下变量
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export PATH=$PATH:$ZOOKEEPER_HOME/bin
十、发送给集群所有主机
xrsync /etc/profile.d/env.sh
十一、每个节点source以下,生效
source /etc/profile.d/env.sh
十二、启动zookeeper
使用之前博客写过的脚本文件
zkop.sh start
5. 启动hadoop
一、第一次启动
首先确保打开了zookeeper服务
然后启动配置在hdfs.xml中的所有journal节点主机中的journal服务
jerry3: hadoop-daemon.sh start journalnode
jerry4: hadoop-daemon.sh start journalnode
jerry5: hadoop-daemon.sh start journalnode
在jerry1进入hadoop根路径中bin目录中
hdfs zkfc -formatZK
然后看见
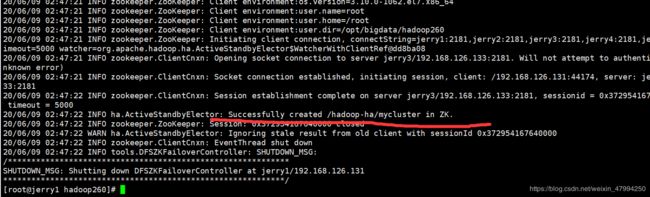
就成功了
对namenode进行格式化
hadoop namenode -format
重要:必须将第一个jerry1中hadoopdata文件夹中的dfs文件夹复制到Jerry2中hadoopdata中,这个很重要。
二、以后(第一次)启动hadoop,以后只需要执行这个,不用执行第一次的步骤了,直接启动
jerry1: start-all.sh
由于jerry3,jerry4配置了ResourceManager节点,去jerry3,jerry4:
jerry3: yarn-daemon.sh start resourcemanager
jerry4: yarn-daemon.sh start resourcemanager
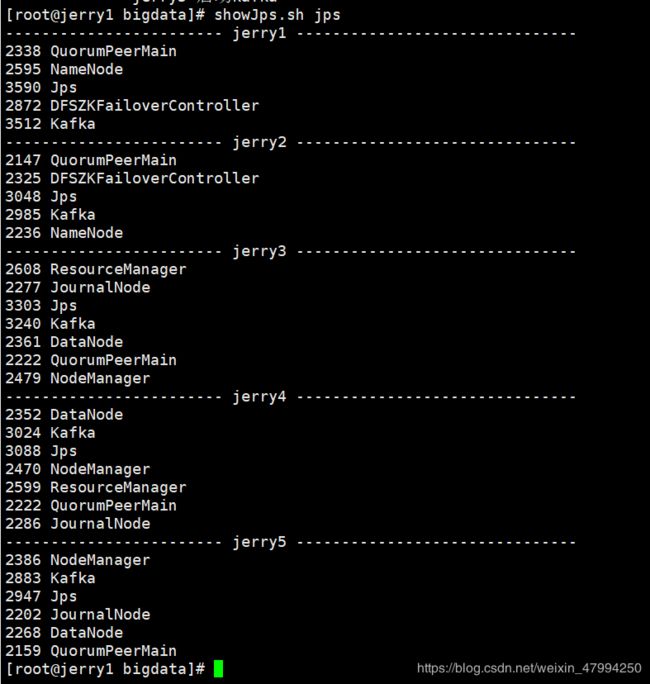
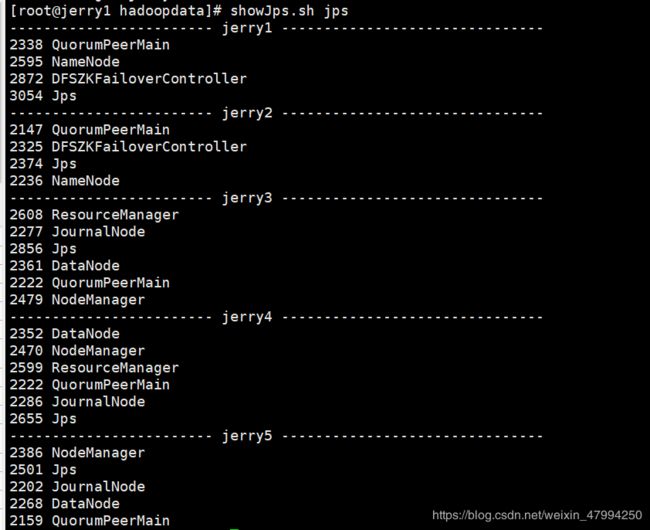
使用showJps.sh查看服务是否正确
5. 安装kafka
一、解压和改名
tar -zxf /opt/install/kafka_2.11-2.0.0.tgz -C /opt/bigdata/
mv /opt/bigdata/kafka_2.11-2.0.0/ /opt/bigdata/kafka211
二、修改kafka配置文件
先在kafka根目录创建logs文件夹
mkdir logs
再进入config文件下,打开server.properties,根据jerry1,所以broker.id写为1,同时添加topic的可删除配置,再配置刚才创建的logs文件夹路径,(注意broker.id在不同节点需要改变,等会发送给集群各主机的时候需要改变id)。


broker.id=1
delete.topic.enable=true
log.dirs=/opt/bigdata/kafka211/logs
发送给集群各主机,记得各主机都要source一下
xrsync /etc/profile.d/env.sh
xrsync kafka211/
source /etc/profile.d/env.sh #source*5
启动kafka,利用前一个博客使用的脚本
kfkop.sh start
6. 到此就结束了,可以通过showJps脚本查看集群所有主机启动的服务,服务完全,如图所示,就说明成功了。