0x00 目标
简单线性回归:回顾简单线性回归及最小二乘法的数据推导
实践:简单线性回归实现及向量化应用
多元线性回归:多选线性回归和正规方程解及实现
0x01 简单线性回归(回顾 第二篇0x04)
0x02 多元线性回归

求解思路也与简单线性回归非常一致,目标同样是:已知训练数据样本x、y ,找到θ,使公式:

尽可能小。
改写成向量点乘形式:

向量化,已知训练数据样本x、y ,找到θ,使公式:

尽可能小。
得多元线性回归的正规方程解:
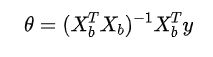
缺点是时间复杂度较高:O(n^3)。
0x02 python实现多元回归
注意点:
1、np.hstack(tup):参数tup可以是元组,列表,或者numpy数组,返回结果为numpy的数组。按列顺序把数组给堆叠起来(加一个新列)。
2、np.ones():返回一个全1的n维数组,有三个参数:shape(用来指定返回数组的大小)、dtype(数组元素的类型)、order(是否以内存中的C或Fortran连续(行或列)顺序存储多维数据)。后两个参数都是可选的,一般只需设定第一个参数。(类似的还有np.zeros()返回一个全0数组)
3、numpy.linalg模块包含线性代数的函数。使用这个模块,可以计算逆矩阵、求特征值、解线性方程组以及求解行列式等。inv函数计算逆矩阵
4、T:array的方法,对矩阵进行转置。
5、dot:点乘
0x03 小结
多元线性回归的正规方程解,看上去简单但是时间复杂度高。其实除了使用正规方程解以外,还可以使用大名鼎鼎的梯度下降法。梯度下降法不仅可以解决线性问题,更是解决机器学习的最优模型的通用算法。
0x04 梯度下降法
4.1 梯度下降(Gradient Descent, GD)
每个模型都有自己的损失函数,不管是监督式学习还是非监督式学习。在学习简单线性回归时,我们使用最小二乘法来求损失函数的最小值,但是这只是一个特例。在绝大多数的情况下,损失函数是很复杂的(比如逻辑回归),根本无法得到参数估计值的表达式。因此需要一种对大多数函数都适用的方法。这就引出了“梯度算法”。
梯度下降(Gradient Descent, GD),不是一个机器学习算法,而是一种基于搜索的最优化方法。梯度下降优化算法,其作用是用来对原始模型的损失函数进行优化,以便寻找到最优的参数,使得损失函数的值最小。从损失值出发,去更新参数,且要大幅降低计算次数。
4.2 梯度(gradient)
梯度下降算法作为一个聪明很多的算法,抓住了参数与损失值之间的导数,也就是能够计算梯度(gradient),通过导数告诉我们此时此刻某参数应该朝什么方向,以怎样的速度运动,能安全高效降低损失值,朝最小损失值靠拢。
多元函数的导数(derivative)就是梯度(gradient),分别对每个变量进行微分,然后用逗号分割开,梯度是用括号包括起来,说明梯度其实一个向量,损失函数L的梯度为:
导数就是变化率。
梯度是向量,和参数维度一样。
在单变量的函数中,梯度其实就是函数的微分,代表着函数在某个给定点的切线的斜率 在多变量函数中,梯度是一个向量,向量有方向,梯度的方向就指出了函数在给定点的上升最快的方向
梯度指向误差值增加最快的方向,导数为0(梯度为0向量)的点,就是优化问题的解。
4.3 致命问题
从理论上,梯度算法只能保证达到局部最低点,而非全局最低点。
解决方案:首先随机产生多个初始参数集,即多组;然后分别对每个初始参数集使用梯度下降法,直到函数值收敛于某个值;最后从这些值中找出最小值,这个找到的最小值被当作函数的最小值。
4.4 Python实现梯度下降
4.4.1 Scipy库中的derivative方法
scipy.misc.derivative(func, x0, dx=1.0, n=1, args=(), order=3)[source]
参数:
func:需要求导的函数,只写参数名即可,不要写括号,否则会报错
x0:要求导的那个点,float类型
dx(可选):间距,应该是一个很小的数,float类型
n(可选):n阶导数。默认值为1,int类型
args(可选):参数元组
order(可选):使用的点数必须是奇数,int类型
4.4.2 Sympy表达式求导
sympy是符号化运算库,能够实现表达式的求导。
"""
import sympy as sy
x = sy.Symbol('x')
"""
博客https://www.cnblogs.com/zyg123/ 中有更多关于Sympy的相关文章。
4.4.3 模拟实现梯度下降
1.构造一个损失函数loss(x),并求出对应的损失函数值。
2.定义一个求导的方法。(计算损失函数在当前点的对应导数,输入当前数据点theta,输出在损失函数上的导数)
3.进行梯度下降。(首先定义一个点θ作为初始值,正常应该是随机的点,但是这里可先直接定为0。然后需要定义学习率η ,也就是每次下降的步长。这样的话,点θ每次沿着梯度的反方向移动η距离,即θ=θ-η*▽f ,然后循环这一下降过程。设定一个非常小的数作为损失函数值的阈值,结束循环。)
0x05 梯度下降之前需要使用归一化
5.1 目标

5.2 推导过程
用梯度下降法来求损失函数最小值时,需要对损失函数进行设计。
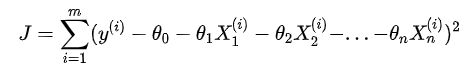
θ=(θ0,,θ1,θ2...,θn)列向量,构造第0个特征X0恒等于1,改写成向量点乘形式:

对其求导,有:

写成向量:

5.3 最终得到的梯度
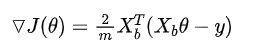
参考阅读:
1.模型之母:简单线性回归&最小二乘法(第二周:评价模型的好坏(20191111-17):0x04简单线性回归)
2.模型之母:简单线性回归的代码实现(第二周:评价模型的好坏(20191111-17):0x04简单线性回归)
3.模型之母:多元线性回归
4.《机器学习》周志华著,第3章 线性模型(P53)
5.《精通数据科学:从线性回归到深度学习》第四章
6.还不了解梯度下降法?看完这篇就懂了!
7.手动实现梯度下降(可视化)
8.线性回归中的梯度下降(代码有些bug仍需调试)
代码另附。