Python3 高级编程
文章目录
- Python高级编程
- 生成式(推导式)
- 生成器
- 迭代器
- 异步编程
- 并发(concurrent)
- 并行(parallel)
- 协程
- 扩展:IO模型
- lambda表达式与函数式编程
- 闭包
- 装饰器
- C语言扩展
- 调用系统API
Python高级编程
生成式(推导式)
用于创建list的生成式
>>> list(range(1,11))
[1,2,3,4,5,6,7,8,9,10]
常见用法
>>> [x * x for x in range(1,11)]
[1, 4, 9, 16, 25, 36, 49, 64, 81, 100]
写列表生成式时,把要生成的元素 x * x 放到前面,后面跟 for 循环,就可以把 list 创建出来
更多示例
>>> [x * x for x in range(1, 11) if x % 2 == 0]
[4, 16, 36, 64, 100]
>>> d = {'x': 'A', 'y': 'B', 'z': 'C' }
>>> [k + '=' + v for k, v in d.items()]
['y=B', 'x=A', 'z=C']
生成器
在 Python 中,一边循环一边计算的机制,称为生成器:
generator。这种机制可以节省内存,提高性能。
1、通过列表创建。即将列表生成式的[]改成()
>>> L = [x * x for x in range(10)]
>>> L
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
>>> g = (x * x for x in range(10))
>>> g
at 0x1022ef630>
注意:生成器对象,可通过for循环进行迭代,也可使用next(g)取下一个值
2、通过函数创建
如果一个函数定义中包含 yield 关键字,那么这个函数就不再是一个普通函数,而是一个 generator对象
def odd():
print('step 1')
yield 1
print('step 2')
yield 3
print('step 3')
yield 5
>>> o = odd()
>>> next(o)
step 1
1
>>> next(o)
step 2
3
>>> next(o)
step 3
5
>>> next(o)
Traceback (most recent call last):
File "", line 1, in
StopIteration
实例,生成器实现斐波那契数列
# 生成斐波那契数列,max指定最大范围
def fib(max):
n, a, b = 0, 0, 1
while n < max:
yield b
a, b = b, a + b
n = n + 1
return 'done'
func = fib(10)
print(next(func))
print(next(func))
print(next(func))
print(next(func))
注意:generator在执行过程中,遇到 yield就中断,下次又继续执行。须要给循环设置一个条件来退出,不然就会产生一个无限数列出来
除了使用next函数,生成器还可以使用for循环来调用,如下
for i in fib(10):
print(i)
迭代器
可以直接作用于 for 循环的对象统称为可迭代对象: Iterable。可以使用 isinstance()判断一个对象是否是 Iterable 对象。但是需要注意,可以被 next()函数调用并不断返回下一个值的对象才被称为迭代器:Iterator,因此生成器一定是迭代器。
>>> from collections import Iterable
>>> isinstance([], Iterable)
True
>>> isinstance({}, Iterable)
True
注意:
>>> isinstance([], Iterator)
False
>>> isinstance({}, Iterator)
False
>>> isinstance('abc', Iterator)
False
需要特别注意的几点:
1、凡是可作用于 for 循环的对象都是 Iterable 类型
2、凡是可作用于 next()函数的对象都是 Iterator 类型,它们表示一个惰性计算的序列。只有在需要返回下一个数据时它才会计算
3、集合数据类型如 list、 dict、 str 等是 Iterable 但不是 Iterator,我们可以通过 iter()函数将之转为一个 Iterator 对象
异步编程
- I/O密集型
- 计算密集型
- GIL(Global Interpreter Lock)
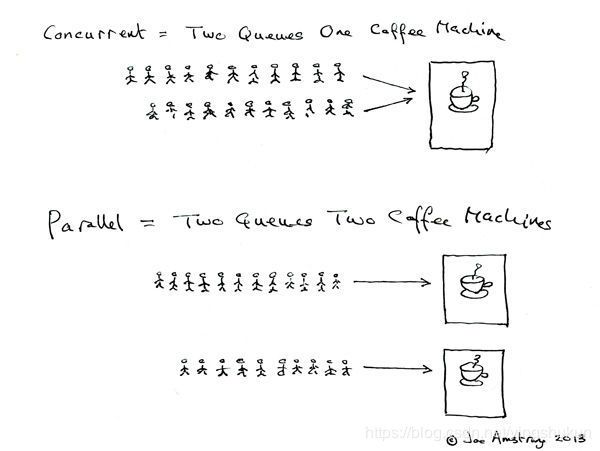
并发(concurrent)
一个单核处理器同时处理多个任务
并行(parallel)
多个处理器或者多核的处理器同时处理多个不同的任务
单核多线程一定是并发,多核多线程不一定是并行。只有当多核多线程处理任务时,这两个线程被分配到不同的核上执行时,这两个任务才是并行的。
并发和并行的区别就是一个人同时吃三个馒头和三个人同时吃三个馒头的区别
协程
协程(coroutine)最初在1963年被提出,但并没有受到重视,现在重新火起来,很大一部分原因是Web服务的发展,对服务器并发的需求。它是一种比线程更加轻量级的存在, 协程不被操作系统内核所管理,而完全由程序员自己去控制和调度,带来的好处就是性能得到了很大的提升,不会像线程切换那样消耗资源

背景
在IO密集型的程序中由于IO操作远远慢于CPU的操作,所以往往需要CPU去等待IO操作。同步IO下系统需要切换线程,让操作系统可以在IO过程中执行其他的东西。 这样虽然代码是符合人类的思维习惯但是由于大量的线程切换带来了大量的性能的浪费,尤其是IO密集型的程序。
所以人们发明了异步IO。就是当数据到达的时候触发我们的回调,用来减少线程切换带来性能损失。 但是这样的坏处也是很大的,主要的坏处就是操作被 “分片” 了,代码写的不是 “一气呵成” ,而是每次来段数据就要判断 数据够不够处理,够处理就处理,不够处理就在等等。这样的代码可读性很低,不符合人类的习惯。
-
同步IO
同步IO指发出一个功能调用时,在没有得到结果之前,该调用就不返回,一直是阻塞状态。 -
异步IO
异步IO的概念和同步IO相对。通常来讲,当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的部件在完成后,通过状态、通知和回调来通知调用者。
协程的优势:一个形象的比喻
假设有1个洗衣房,里面有10台洗衣机,有一个洗衣工在负责这10台洗衣机。那么洗衣房就相当于1个进程,洗衣工就相当1个线程。如果有10个洗衣工,就相当于10个线程,1个进程是可以开多线程的。这就是多线程
然而洗衣机洗衣服是需要等待时间的,如果10个洗衣工,1人负责1台洗衣机,这样效率肯定会提高,但是很浪费资源。明明1个人能做的事,却要10个人来做。只是把衣服放进去,打开开关,这十个人就没事做了,等衣服洗好再拿出来就可以了。就算很多人来洗衣服,1个人也足以应付了,开好第一台洗衣机,在等待的时间就可以去处理第二台洗衣机、第三台……直到有衣服洗好
手写协程,最简示例。运行后可看到A、B两个任务交替进行
import time
def methodA():
while True:
print("----A 任务---")
yield
print("----A sleep---")
time.sleep(0.5)
def methodB(c):
while True:
print("----B 任务---")
next(c)
print("----B sleep---")
time.sleep(0.5)
if __name__ == '__main__':
a = methodA()
methodB(a)
使用gevent协程库,安装python -m pip install gevent
import gevent
def f1():
for i in range(3):
print("f1 run ", i)
# 用来模拟一个耗时操作
gevent.sleep(2)
def f2():
for i in range(4):
print("f2 run ", i)
# 用来模拟一个耗时操作
gevent.sleep(2)
g1 = gevent.spawn(f1)
g2 = gevent.spawn(f2)
g1.join()
g2.join()
协程实现并发爬虫实例:
from gevent import monkey
monkey.patch_all() # 导入monkey机制,并自动替换Python中的一些原生代码,将其替换为gevent框架重写过的代码
import gevent
import urllib.request
def run_task(url):
print('URL:%s' % url)
response = urllib.request.urlopen(url)
html = response.read()
print(html)
if __name__ == '__main__':
urls = ['https://www.baidu.com', 'https://www.python.org/', 'http://www.gevent.org/']
greenlets = [gevent.spawn(run_task, url) for url in urls]
gevent.joinall(greenlets)
扩展:IO模型
来自于类Unix系统的概念
-
阻塞IO模型
A同学用杯子装水,打开水龙头装满水然后离开。这一过程就可以看成是使用了阻塞IO模型,因为如果水龙头没有水,他也要等到有水并装满杯子才能离开去做别的事情。很显然,这种IO模型是同步的 -
非阻塞IO模型
B同学也用杯子装水,打开水龙头后发现没有水,它离开了,过一会他又拿着杯子来看看……在中间离开的这些时间里,B同学离开了装水现场(回到用户进程空间),可以做他自己的事情。这就是非阻塞IO模型。但是它只有是检查无数据的时候是非阻塞的,在数据到达的时候依然要等待复制数据到用户空间(等着水将水杯装满),因此它还是同步IO。 -
IO复用模型
这个时候C同学来装水,发现有一排水龙头,舍管阿姨告诉他这些水龙头都还没有水,等有水了告诉他。于是等啊等(属于select函数调用),过了一会阿姨告诉他有水了,但不知道是哪个水龙头有水,于是C同学一个个打开,往杯子里装水(recv)。
如果这时候舍管阿姨告诉C同学哪几个水龙头有水了,而不需要一个个打开检查,则属于epoll式(对select的增强版本)调用。著名的Nginx服务器即使用的这种方式 -
信号驱动IO模型
D同学让舍管阿姨等有水的时候通知他(注册信号函数),没多久D同学得知有水了,跑去装水。这还是属于同步IO,装水的时间并没有省(从内核态到用户态的数据拷贝)。 -
异步IO模型
E同学让舍管阿姨将杯子装满水后通知他。整个过程E同学都可以做别的事情(没有recv),这是真正的异步IO。即调用aio_read,让内核等数据准备好,并且复制到用户进程空间后执行事先指定好的函数。
一般来讲:阻塞IO模型、非阻塞IO模型、IO复用模型(select/poll/epoll)、信号驱动IO模型都属于同步IO 概念来自于《UNIX网络编程卷1》
lambda表达式与函数式编程
lambda表达式实际上就是一种匿名函数,在GUI编程中用处很大。
# 普通函数
def f1(x):
return x * x
# lambda表达式
f2 = lambda x: x * x
f2(5)
在动态类型语言中,通常函数也是一种对象,其中存放了一段等待执行的指令,函数名也是变量,故函数也可以赋值给变量,因此函数也可以作为返回值
>>> def add():
... return 2 + 1
...
>>> add
>>>
示例
def add(a, b):
return a + b
def process(t, func):
print(func(t[0], t[1]))
# 定义一个坐标点的元组
point = (2, 8)
process(point, add)
闭包
内部函数对外部函数作用域内变量的引用(非全局变量),则称内部函数为闭包
最小示例
# 定义一个函数
def test(number):
# 在函数内部再定义一个函数
def test_in(number_in):
return number + number_in
# 返回闭包
return test_in
res = test(10)
print(res(100))
print(res(200))
print(res(300))
计数器示例
def counter(start=0):
counts = [start]
def incr():
counts[0] += 1
return counts[0]
return incr
count = counter()
print(count())
print(count())
print(count())
装饰器
面向对象编程中有
开放封闭原则,但它也适用于函数式编程,简单来说,它规定已经实现的功能代码不允许被修改,但可以被扩展。这种扩展是非侵入式的。Python提供的装饰器就是解决该问题。
import time
def consume(func):
def inner():
start = time.time()
func()
print(time.time() - start)
return inner
@consume
def a():
time.sleep(0.7)
print("-- a --")
def b():
print("-- a --")
def c():
print("-- a --")
以上代码中,@consume实际上只是Python的语法糖,即使我们不使用这个语法糖,照样可以使用装饰器,它等价于以下代码
f = consume(a)
f()
a = f
装饰器的常用用途
- 引入日志
- 函数执行时间统计
- 执行函数前预备处理
- 执行函数后清理功能
- 权限校验等场景
- 缓存
C语言扩展
在Python中调用C基本有两种方式:
1.使用标准库的ctypes模块。该方式主要用于在Python中调用动态链接库(.dll、.so),当不需要在C代码中反调用Python代码时,推荐使用,简单高效。使用这种方式,编写的动态库无需为Python特别处理,就和编写普通的动态库一样。
2.使用Python提供的一组特定C API(声明在Python.h中),用C语言为Python编写模块。在这种方式中,Python可以和C互相调用。与Java JNI 相似,但比之更简洁高效。
需要注意一点,为Python写C扩展时,解释器的版本需和编译出的程序的版本匹配,也就是说,本地解释器是32位,编译出的C扩展程序也必须是32位,64位亦然。
hello.c
#include
void showTips(){
MessageBox(NULL,"Hello Windows","Tips",MB_OK);
}
test01.py
import platform
from ctypes import *
if platform.system() == 'Windows':
lib = cdll.LoadLibrary('hello.dll')
lib.showTips()
安装MinGW环境进行编译:gcc hello.c -shared -o hello.dll
获得hello.dll动态库
第二种使用Python提供的C API写扩展,详见我的博客
调用系统API
通过ctypes模块可以直接调用到操作系统API
如下示例,调用Windows系统中的user32.dll库中的mouse_event函数,移动当前屏幕鼠标箭头的位置
import ctypes
ctypes.windll.user32.mouse_event(0x0001|0x8000, 1000, 500, 0, 0)
安装第三方封装的pywin32库,使用Python进行window编程。
python -m pip install pywin32
该库主要有三个模块win32api、win32gui和win32con
Windows API编程示例
import win32gui
from win32con import *
def WndProc(hwnd, msg, wParam, lParam):
if msg == WM_PAINT:
hdc, ps = win32gui.BeginPaint(hwnd)
rect = win32gui.GetClientRect(hwnd)
win32gui.DrawText(hdc, 'GUI Python', len('GUI Python'), rect, DT_SINGLELINE | DT_CENTER | DT_VCENTER)
win32gui.EndPaint(hwnd, ps)
if msg == WM_DESTROY:
win32gui.PostQuitMessage(0)
return win32gui.DefWindowProc(hwnd, msg, wParam, lParam)
wc = win32gui.WNDCLASS()
wc.hbrBackground = COLOR_BTNFACE + 1
wc.hCursor = win32gui.LoadCursor(0, IDI_APPLICATION)
wc.lpszClassName = "Python no Windows"
wc.lpfnWndProc = WndProc
reg = win32gui.RegisterClass(wc)
hwnd = win32gui.CreateWindow(reg, 'Python', WS_OVERLAPPEDWINDOW, CW_USEDEFAULT, CW_USEDEFAULT,
CW_USEDEFAULT, CW_USEDEFAULT, 0, 0, 0, None)
win32gui.ShowWindow(hwnd, SW_SHOWNORMAL)
win32gui.UpdateWindow(hwnd)
win32gui.PumpMessages()
MFC 编程示例
import win32ui
from win32con import *
from pywin.mfc import window
class MyWnd(window.Wnd):
def __init__(self):
window.Wnd.__init__(self, win32ui.CreateWnd())
self._obj_.CreateWindowEx(WS_EX_CLIENTEDGE, \
win32ui.RegisterWndClass(0, 0, COLOR_WINDOW + 1), \
'MFC', WS_OVERLAPPEDWINDOW, \
(100, 100, 400, 300), None, 0, None)
def OnClose(self):
self.EndModalLoop(0)
def OnPaint(self):
dc, ps = self.BeginPaint()
dc.DrawText('this is MFC',
self.GetClientRect(),
DT_SINGLELINE | DT_CENTER | DT_VCENTER)
self.EndPaint(ps)
w = MyWnd()
w.ShowWindow()
w.UpdateWindow()
w.RunModalLoop(1)
欢迎关注我的公众号:编程之路从0到1
