NLP面试知识点整理(2):fastText
目录
- 1. 字符级别的n-gram
- 2. 模型架构
- 3. fastText的优点
- 4. 代码实现
1. 字符级别的n-gram
英语单词通常有其内部结构和形成⽅式。例如,我们可以从“dog”“dogs”和“dogcatcher”的字⾯上推测它们的关系。这些词都有同⼀个词根“dog”。
在word2vec中,我们并没有利⽤构词学中的信息,这种单词内部形态信息因为它们被转换成不同的id丢失了。例如,“dog”和“dogs”分别⽤两个不同的向量表⽰,而模型中并未直接表达这两个向量之间的关系。鉴于此,fastText提出了子词嵌入(subword embedding)的方法,从而试图将构词信息引入word2vec中的CBOW。
fastText使用了字符级别的n-grams来表示一个单词。对于单词“book”,假设n的取值为3,则它的trigram有:
“
其中,‘<‘表示前缀,‘>‘表示后缀。于是,我们可以用这些trigram来表示“book”这个单词,进一步,我们可以用这4个trigram的向量叠加来表示“apple”的词向量。
这带来两点好处:
- 对于低频词生成的词向量效果会更好。因为它们的n-gram可以和其它词共享。
- 对于训练词库之外的单词,仍然可以构建它们的词向量。我们可以叠加它们的字符级n-gram向量。
fastText的核心思想
仔细观察模型的后半部分,即从隐含层输出到输出层输出,会发现它就是一个softmax线性多类别分类器,分类器的输入是一个用来表征当前文档的向量;
模型的前半部分,即从输入层输入到隐含层输出部分,主要在做一件事情:生成用来表征文档的向量。那么它是如何做的呢?**叠加构成这篇文档的所有词及n-gram的词向量,然后取平均。**叠加词向量背后的思想就是传统的词袋法,即将文档看成一个由词构成的集合。
**于是fastText的核心思想就是:将整篇文档的词及n-gram向量叠加平均得到文档向量,然后使用文档向量做softmax多分类。**这中间涉及到两个技巧:字符级n-gram特征的引入以及分层Softmax分类。
2. 模型架构
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DkVKdt9u-1589019933329)(…/pic/2-4-2-2635-1516863566-2.jpeg)]
**注意:**此架构图没有展示词向量的训练过程。可以看到,和CBOW一样,fastText模型也只有三层:输入层、隐含层、输出层(Hierarchical Softmax),输入都是多个经向量表示的单词,输出都是一个特定的target,隐含层都是对多个词向量的叠加平均。
fastText与CBOW的不同之处在于
- CBOW的输入是目标单词的上下文,fastText的输入是多个单词及其n-gram特征,这些特征用来表示单个文档;
- CBOW的输入单词被one-hot编码过,fastText的输入特征是被embedding过;
- CBOW的输出是目标词汇,fastText的输出是文档对应的类标。
- CBOW的叶子节点是词和词频,fastText叶子节点里是类标和类标的频数。
值得注意的是,fastText在输入时,将单词的字符级别的n-gram向量作为额外的特征;在输出时,fastText采用了分层Softmax,大大降低了模型训练时间。
【注】embedding:
- embedding就是将一个矩阵映射到另一个空间的操作,把原来稀疏的one/multi hot编码的向量表达为稠密的向量;
- 本质就是用来降维的,实现降维的原理就是矩阵乘法。
有意思的是,fastText和Word2Vec的作者是同一个人。
fastText与Word2Vec的相同点:
- 图模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
- 都采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
| Word2Vec | fastText | |
|---|---|---|
| 输入 | one-hot形式的单词的向量 | embedding过的单词的词向量和n-gram向量 |
| 输出 | 对应的是每一个term,计算某term概率最大 | 对应的是分类的标签。 |
本质不同,体现在softmax的使用:
word2vec的目的是得到词向量,该词向量最终是在输入层得到的,输出层对应的h-softmax也会生成一系列的向量,但是最终都被抛弃,不会使用。
fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label。
3. fastText的优点
- 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”
- 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
- 专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。
需要特别注意的是,对于不加n-gram向量的FastText模型,他不可能去分辨否定词的位置,看下面的两句话:
我不喜欢这类电影,但是喜欢这一个。
我喜欢这类电影,但是不喜欢这一个。
这样的两句句子经过词向量平均以后已经完全一模一样了,分类器不可能分辨出这两句话的区别,只有添加n-gram特征以后才可能有区别。
那么,为什么fastText的分类效果常常不输于传统的非线性分类器?
假设我们有两段文本:
我 来到 达观数据
俺 去了 达而观信息科技
这两段文本意思几乎一模一样,如果要分类,肯定要分到同一个类中去。但在传统的分类器中,用来表征这两段文本的向量可能差距非常大。传统的文本分类中,你需要计算出每个词的权重,比如tfidf值, “我”和“俺” 算出的tfidf值相差可能会比较大,其它词类似,于是,VSM(向量空间模型)中用来表征这两段文本的文本向量差别可能比较大。
但是fastText就不一样了,它是用单词的embedding叠加获得的文档向量,词向量的重要特点就是向量的距离可以用来衡量单词间的语义相似程度,于是,在fastText模型中,这两段文本的向量应该是非常相似的,于是,它们很大概率会被分到同一个类中。
使用词embedding而非词本身作为特征,这是fastText效果好的一个原因;另一个原因就是字符级n-gram特征的引入对分类效果会有一些提升 。
4. 代码实现
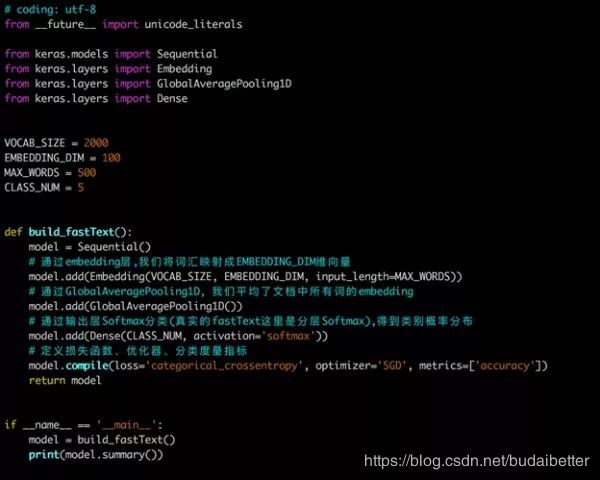
keras是一个抽象层次很高的神经网络API,由python编写,底层可以基于Tensorflow、Theano或者CNTK。它的优点在于:用户友好、模块性好、易扩展等。
模型搭建遵循以下步骤:
-
添加输入层(embedding层)。Embedding层的输入是一批文档,每个文档由一个词汇索引序列构成。Embedding层将每个单词映射成n维的向量。
-
添加隐含层(投影层)。投影层对一个文档中所有单词的向量进行叠加平均。keras提供的GlobalAveragePooling1D类可以帮我们实现这个功能。这层的input_shape是Embedding层的output_shape,这层的output_shape=( BATCH_SIZE, EMBEDDING_DIM);
-
添加输出层(softmax层)。真实的fastText这层是Hierarchical Softmax,因为keras原生并没有支持Hierarchical Softmax,所以这里用Softmax代替。这层指定了CLASS_NUM,对于一篇文档,输出层会产生CLASS_NUM个概率值,分别表示此文档属于当前类的可能性。这层的output_shape=(BATCH_SIZE, CLASS_NUM)
-
指定损失函数、优化器类型、评价指标,编译模型。损失函数我们设置为categorical_crossentropy,它就是我们上面所说的softmax回归的损失函数;优化器我们设置为SGD,表示随机梯度下降优化器;评价指标选择accuracy,表示精度。
用训练数据feed模型时,你需要:
-
将文档分好词,构建词汇表。词汇表中每个词用一个整数(索引)来代替,并预留“未知词”索引,假设为0;
-
对类标进行onehot化。假设我们文本数据总共有3个类别,对应的类标分别是1、2、3,那么这三个类标对应的onehot向量分别是[1, 0, 0]、[0, 1, 0]、[0, 0, 1];
-
对一批文本,将每个文本转化为词索引序列,每个类标转化为onehot向量。就像之前的例子,“我 昨天 来到 达观数据”可能被转化为[10, 30, 80, 1000];它属于类别1,它的类标就是[1, 0, 0]。由于我们设置了MAX_WORDS=500,这个短文本向量后面就需要补496个0,即[10, 30, 80, 1000, 0, 0, 0, …, 0]。因此,batch_xs的 维度为( BATCH_SIZE,MAX_WORDS),batch_ys的维度为(BATCH_SIZE, CLASS_NUM)。
下面是构建模型的代码,数据处理、feed数据到模型的代码比较繁琐,这里不展示。
另一个实现案例:
清华文本分类数据集下载:https://thunlp.oss-cn-qingdao.aliyuncs.com/THUCNews.zip
实例代码:新闻文本分类代码
本文参考:
https://github.com/NLP-LOVE/ML-NLP
fastText原理及实践(达观数据王江)