《Conditional Generative Adversarial Networks for SE and Noise-Robust Speaker Verification》
摘要:在嘈杂环境中提高语音系统性能仍然是一项具有挑战性的任务,语音增强(SE)是解决该问题的有效技术之一。由于生成对抗网络(GAN)在各种图像处理任务中的有发展前景的实验结果,我们探索条件GAN(cGAN)对SE的潜力,特别是,我们利用Isola提出的图像处理框架[1] ]学习从嘈杂语音的谱图到增强对应物的映射。SEcGAN由两个以对抗方式训练的网络组成:一个试图增强输入噪声频谱图的生成器,以及一种判别器,以有噪声的谱图为条件,试图区分由生成器生成的增强谱图和数据集中干净语音的谱图。我们根据语音质量感知评估(PESQ),短时客观可懂度(STOI)和说话者验证的等错误率(EER)(示例应用)来评估cGAN方法的性能。实验结果表明,cGAN方法总体上优于经典的短时谱振幅最小均方误差(STSA-MMSE)SE算法,并且与基于深度神经网络的SE方法(DNN-SE)相当。
引言
处理降级的语音信号在许多应用中是一项具有挑战性但重要的任务,例如, 自动说话人验证(ASV)[2],语音识别[3],移动通信和听力辅助设备[4,5,6]。 当接收器是人类用户时,SE的目标是改善带噪语音信号的质量和可懂度。 当它是自动语音系统时,目标是改善系统的噪声稳健性,例如, 在不利条件下降低ASV系统的EER。 在过去,这个问题已经用维纳滤波器和STSA-MMSE等统计方法解决[7]。 最近,已经使用了深度学习方法,例如DNN [6,8],深度自动编码器(DAE)[5]和卷积神经网络(CNN)[9]。 但是,据我们所知,还没有人尝试过将GAN用于SE。
GANs是Goodfellow等人最近引入的一个框架。[10]由一个生成模型(generator, G)和一个判别模型(discriminative, D)组成,这两个模型之间进行最小-最大博弈。特别是,G试图欺骗D, D经过训练,能够区分G的输出和真实数据。目前[11]所采用的架构大多基于深卷积GAN (DCGAN)[12],它成功地解决了GANs应用于高分辨率图像时的训练不稳定性问题。实现这一目标需要三个关键思想。首先,将批处理规范化[13]应用于大多数层。然后,网络被设计成没有像[14]中那样的池化层。最后,使用Adam优化器[15]执行培训。
到目前为止,GAN已成功应用于各种计算机视觉和图像处理任务[1,12,16,17]。然而,在语音相关的任务中的应用很少,文献[18]是个例外,作者将深层视觉模拟网络[19]作为GAN的生成器来实现语音转换,实验结果以音频文件呈现但是没有语音质量、可懂性等其他的评估。在相关领域,将GAN概念应用于古典音乐生成[20]的递归神经网络训练。
最近,一个通用的cGAN框架Pix2Pix被提出用于图像到图像的转换[1]。基于GANs在多个任务上的成功部署,我们对该框架进行了调整,旨在探索cGANs对SE的潜力,作为研究GANs在语音处理方面的可行性和性能的总体目标的一部分。具体来说,我们使用Pix2Pix来学习噪声和干净语音谱图之间的映射,以及学习训练映射的损失函数。
Pix2Pix framework for speech enhancement
在GAN中,G表示从随机噪声向量z到输出样本G(z)的映射函数,理想情况下与实际数据x [10]无法区分。 在cGAN中,G和D都以一些额外的信息y [1]为条件,并且他们在最小 - 最大游戏之后训练,目标是:
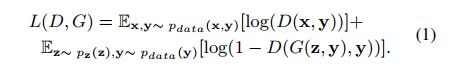
Pix2Pix与其他cGAN作品不同,如[21],因为它不使用z。Isola等[1]报告说,像[22]所做的那样,将高斯噪声作为输入添加到G中是无效的。因此,他们引入dropout形式的噪声,但这种技术未能产生随机输出。然而,我们更感兴趣的是噪声频谱图和干净频谱图之间的准确映射,而不是能够捕获其建模的分布的全部熵的cGAN,因此这代表了一个小问题。图1显示了在本文的特定情况下,如何在训练过程中使用数据和条件。
除了从数据中学习的对抗性损失L(D; G)之外,Pix2Pix还利用G的输出与地面实况之间的L1距离。选择结合不同的损失,如L2距离[23]或特定任务的知觉损失[16,17],已被证明是有益的。在Pix2Pix中,L1距离优于L2,因为L1距离可以减少[1]的模糊,而且与感知损失相比,L1距离的泛化效果更好。

此外,改编自[12]的G和D分别是U-Net [24]和PatchGAN。由于在图像到图像转换任务中,G的输入和输出共享相同的结构,G是编码器 - 解码器结构,其中解码器层的每个特征映射与来自编码器的镜像对应物连接以避免最内层 layer表示信息流的瓶颈。此外,建立D对数据的高频进行建模,因为低频结构被L1损耗捕获。这是通过考虑局部图像patch实现的。特别地,在图像上对D进行卷积,将每个patch分为真patch和假patch。然后,将得到的分数平均在一起,得到一个单独的输出。该结构具有体积小的优点,可以应用于不同尺寸的[1]图像。当D的patch大小与输入图像大小相同时,D相当于经典的GAN识别器
我们的Pix2Pix实现基于[25],G获得256 * 256 * 1通道图像,而D 256 * 256 * 2通道图像。 与原始框架的主要区别在于卷积层采用5 * 5滤波器,最后一层的D被压平并输入到一个单一的sigmoid输出中,如[12]。
2.1 预处理和训练
对于采样率为16khz的语音信号,我们使用一个512点短时傅里叶变换(STFT)计算时频(T-F)表示,其汉明窗大小为32 ms,窗移动步长为16 ms。这样,频率分辨率为16 kHz / 512 = 31.25 Hz /(per frequency bin). 我们只考虑了由于对称性而覆盖正频率的257点STFT幅度矢量。我们的生成器G接受256 * 256 * 1的输入,因此对于训练我们连接所有语音信号,然后以256帧为间隔分离频谱图,而为了测试我们将每个测试样本的频谱图填零,以便具有帧数 等于256的倍数,然后相应地执行拆分。测试时,我们对每个测试样本的光谱图进行零填充,使帧数等于256的倍数,然后进行相应的分割。我们还删除了频谱图的最后一行,这是一个影响可以忽略不计的选择,因为它只代表信号的最高31.25 Hz频段,但允许我们的输入尺寸大小为2的幂,使得G和D的设计更加简单。在数据被送入系统之前,也被归一化为[1;1]。
我们使用随机梯度下降(SGD)训练GAN并采用Adam优化器,根据[1]对批量大小为1的10个时期进行训练,每次迭代更新G两次以避免D的快速收敛[25]。 网络权重已从正态分布初始化,均值为零,标准差为0.02 [1]。将L1norm添加到GAN损失中,超参数为100。
为了用Pix2Pix增强语音信号,我们首先计算了它的T-F表示,然后通过G向前传播谱图幅度。最后,利用噪声输入的相位,用反STFT对信号进行重构。
3 实验
3.1 评估指标
我们系统的性能是根据PESQ [26](特别是宽带扩展[27]),STOI [28]和ASV的EER来评估的。 已选择PESQ和STOI,因为它们分别是最常用的语音质量和语音清晰度的估计器。 本文中使用的实现来自PESQ的[7]和STOI的[28]。
关于ASV评估,我们使用经典的高斯混合模型 - 通用背景模型(GMMUBM)框架[29],它适用于这项工作中的简短话语。我们首先构建了一个通用模型UBM,它是一个GMM训练的期望最大化算法,使用大量不属于目标说话者的语音数据。然后,通过UBM的最大后验自适应导出每个特定密码短语和每个说话者的目标说话者模型。使用适应UBM的方法是为了即使在没有太多可用数据的情况下也有被较好训练的说忽然识别模型。此时,对于测试话语,我们计算了申请人说话者模型和UBM之间的对数似然比。 从语音数据中提取的特征是57维梅尔频率倒频谱系数(MFCC),并且GMM混合数是512。
3.2 基线方法
我们将该方法的结果与另外两种我们认为是基线的方法进行了比较:STSA-MMSE和一种基于理想比掩码(IRM)的DNN-SE算法。
STSA-MMSE是一种基于统计的SE技术,其中使用Decision-Directed方法[30]估计先验信噪比(SNR),并使用噪声PSD跟踪器估计噪声功率谱密度(PSD)[31]。噪声PSD估计初始化为每个语音的前1000个样本,假设是一个无语音区域。
对于DNN-SE算法,我们使用与[6]相同的过程和参数。通过使用具有三个隐藏层(每个1024个单元)的DNN和具有64个单元的输出层来估计IRM。DNN的输入是1845维特征向量,它是帧的稳健表示,其结合了MFCC,幅度调制频谱图,相对频谱变换 - 感知线性预测(RASTA-PLP)和gammatone滤波器组能量,以及它们的组合。 对于2个过去和2个未来帧的上下文的delta和double delta。训练标签由IRM表示,其根据[32]中的TF表示基于gammatone滤波器组计算,其中64个滤波器在Mel频率标度上线性间隔并且带宽等于一个等效的矩形带宽[33]。 系统使用SGD训练30个epochs,使用均方误差作为误差函数,批量大小为1024.为了增强测试信号,DNN提供了一种IRM估计,并将其应用于含噪信号的T-F表示。最后,合成时域信号。
3.3 数据集
我们使用两个语料库,TIMIT[34]和RSR2015[35],如下所示:
- Set 1 (TIMIT) - UBM训练使用男性说话者的4380个话语。
- Set 2 (RSR2015)—选择50位男性说话者(从m051到m100)在第1、4和7个会话中2到30个会话中的文本ID来训练Pix2Pix和DNN-SE。
- Set 3 (RSR2015)—使用会话1、会话4和会话7的文本ID 1为49位男性说话者(从m002到m050)培训说话模型。
- Set 4 (RSR2015)—选择用于训练模型的相同文本ID和说话者的第2、3、5、6、8和9对话进行评估。
选择RSR2015作为培训和测试的主要数据库可以看作是一种妥协,因为我们对ASV系统的评估很感兴趣,而ASV系统提供了对性能的另一种客观度量,而RSR2015被广泛用于这项任务。
我们使用了5种不同的噪音类型来模拟现实生活中的情况:
从Librispeech语料库[36]中随机添加6个语音样本,得到Babble; MATLAB中产生的高斯白噪声; Cantine,由作者记录; Market and Airplane,由Fondazione Ugo Bordoni (FUB)收集,可根据OCTAVE项目[37]的要求提供。在不同信噪比下,将噪声数据添加到Set 2、3、4中的话语中,用于训练和测试的数据是不同的。
3.4 设置
受[2]的启发,我们研究了两种不同类型的基于Pix2Pix的SE前端:5个噪声特定的前端(NS-Pix2Pix),每个前端只训练一种类型的噪声,1个噪声通用前端(NG-Pix2Pix),对所有类型的噪音进行过培训。DNN-SE前端也采用了同样的方法,获得了5个噪声特定前端(NS-DNN)和1个噪声通用前端(NG-DNN)。对于训练,我们在干净语音上添加两种不同信噪比的噪声(10db和20db)。在高信噪比的情况下,训练能够捕捉噪声输入的底层结构并生成干净的谱图的G应该会更容易,但是,在未来,训练的低信噪比测试是值得探索的。为了测试,报告了5种不同SNR条件的结果:0,5,10,15和20 dB,这是ASV通常所做的,但未来有趣的工作是测试较低的SNR,特别是对于可懂度评估。此外,为了在无噪声条件下找到前端的行为,还报告了增强的干净语音数据的ASV性能。在所有测试中,呈现了以下前端的性能:没有增强(当在噪声数据上没有使用SE算法时),STSA-MMSE,NS-DNN,NS-Pix2Pix,NG-DNN和NG-Pix2Pix。 总共进行了三次不同的测试。
- Test1: 在第一个测试中,我们计算不同前端的PESQ和STOI来估计语音质量和可懂度.
- Test2: 在第二次测试中,ASV系统使用增强干净语音进行训练(使用干净语音的No增强前端除外),并对5种噪声进行测试。
- Test3: 进行最后一次测试以评估多条件训练对ASV的影响。 对于无增强,STSA-MMSE,NS-DNN和NS-Pix2Pix,说话人模型由增强的干净语音和一种增强的噪声语音构成,而对于NGDNN和NG Pix2Pix,使用各种噪声。
4、结果与讨论
测试1的结果显示在表1中。观察到NS-Pix2Pix和NG-Pix2Pix的平均PESQ得分总是优于其他前端。 无论噪声类型如何,都可以在5到15 dB SNR之间实现最佳性能提升。 在20 dB时,我们的方法在市场和白噪声方面优于其他方法,但对于飞机噪声,STSAMMSE是最好的,而对于Babble和Cantine噪声,没有增强是优越的,这表明所有SE技术都引入了超过 减少噪音的好处。 在0 dB时,NG-Pix2Pix通常优于噪声特定版本,但有一个例外(市场噪声),其分数接近DNN-SE。
就STOI而言,Pix2Pix前端的性能与STSA-MMSE类似。 然而,DNN-SE前端在几乎所有条件下都是优越的,即使Pix2Pix前端在某些情况下达到相同或非常接近的结果,例如: Cantine和市场噪音的低信噪比。 在20 dB时,我们观察到与PESQ分数相同的行为,其中对未增强信号的评估给出了更好的结果。

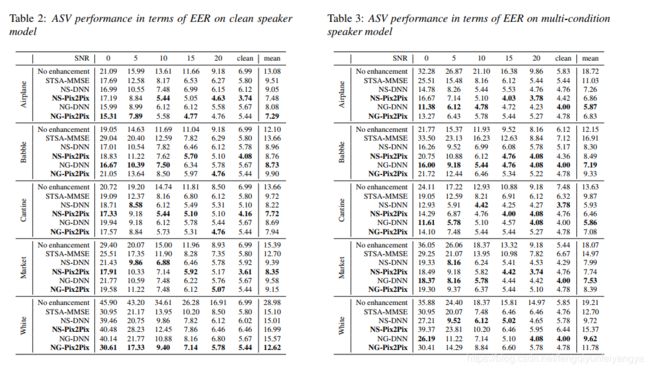
表2和表3报告了ASV性能(试验2和3),其中基线系统的结果来自[38]。 对于干净的扬声器型号,Pix2Pix前端通常优于基线方法。 Babble噪声有一个例外,其中NG-DNN前端的EER为8.73%,略高于NS-Pix2Pix(8.76%)。 在低SNR时,DNN-SE前端有时会显示出比Pix2Pix更好的结果,但总的来说我们的方法可以被认为是优越的。
另一方面,DNN-SE前端在多条件训练中的表现通常更好,与清洁扬声器模型情况相比,这显着改善。 我们的方法通常比STSAMMSE更好,尽管NS-Pix2Pix前端在处理白噪声时表现出较低的性能。

一般来说,Pix2Pix可以被认为与DNN-SE竞争(在干净的扬声器型号上更好的PESQ和EER,但在多条件训练中更差的STOI和EER)并且总体上优于STSA-MMSE。
图2显示了噪声语音(0 dB信噪比下的白噪声)的频谱图,以及使用NG-Pix2Pix、NG-DNN和STSA-MMSE的清晰和增强版本。结果表明,与其它SE方法相比,cGAN方法增强后的谱图较好地保留了原始信号的结构,同时,与NG-DNN相比,在高频区保留了更多的噪声。经STSA-MMSE增强后的谱图存在大量残留物(类似于雪花分布在频谱图上)。
5、结论
在本文中,我们研究了条件生成对抗网络(cGAN)在语音增强中的应用。 我们采用了Pix2Pix框架,旨在解决一般的图像到图像转换问题,并根据估计的语音感知质量和语音清晰度评估该方法的性能,以及高斯混合模型的相同错误率 - 通用背景模型 基于说话人验证系统。 我们得到的结果使我们得出结论,cGAN是一种很有前景的语音去噪技术,在全球范围内优于传统的STSA-MMSE算法,并且与DNN-SE算法相当。
未来的工作包括在更关键的SNR情况下对框架进行更广泛的评估,以及旨在使其特定于任务的修改。 例如,可以构建具有G从固定数量的连续帧生成小尺寸输出窗口的模型,因为它通常在用于语音处理的深度神经网络中完成,并且要添加到cGAN损失的特定感知损失可以是设计的。