语音特征提取学习笔记--对比kaldi、htk、w2l的语音提取过程。
前言
任何模式识别系统的第一个问题都是选择什么样的特征作为系统的输入,与语音识别也不例外,为了准确地反映待测系统的特性,并且让识别系统本身容易处理和分类,语音专家经过了几十年的研究,各种各样的语音特性提取也被提出来,而在经典的GMM-HMM模型中,MFCC是绝对的C位。不过在KALDI和HTK软件中,除了MFCC,其实还提供了其他一些特性提取方法,其中就包括PLP和FilterBank。本文又加入了w2l,目前最流行的开源人工智能网络ASR工具集,横向比较中,了解和学习一下语音提取技术的特点和发展。
基本概念
Cepstrum
倒谱,这个单词就是从spectrum的前四个字母反过来写衍生的,数学上定义为信号的傅里叶变换谱经对数运算后再进行的傅里叶反变换。由于一般傅里叶谱是复数谱,因而又称复倒谱。倒谱分析有时也被称为逆频率分析(quefrency 阿nalysis),属于同态滤波的范畴(liftering)。但这个mel倒谱和MFCC还不是一个概念。本段落剩下部分主要翻译网文[8]的内容,阐述倒谱的一些特征。
假设x(n)为时间域信号,X(k)是复数频谱,P(k)是功率谱 ,A(n)是自相关序列,C(n)为倒谱。省却复杂的数学运算,用 D F T DFT DFT和 I D F T IDFT IDFT表示傅立叶的正反变换,那么复频谱可以如下表示
D F T ( x ( n ) ) ⇒ X ( k ) DFT(x(n))\Rightarrow X(k) DFT(x(n))⇒X(k)
逆变换则表示为:
I D F T ( X ( K ) ) ⇒ x ( n ) IDFT(X(K))\Rightarrow x(n) IDFT(X(K))⇒x(n)
周期性的功率谱概念是有一个历史的,傅立叶级数提出后,首先在人们观测自然界中的周期现象时得到应用。19世纪末,Schuster提出用傅立叶级数的幅度平方作为函数中功率的度量,并将其命名为“周期图”(periodogram)。这是经典谱估计的最早提法,这种提法至今仍然被沿用,只不过现在是用快速傅立叶变换(FFT)来计算离散傅立叶变换(DFT),用DFT的幅度平方作为信号中功率的度量。
∣ D F T ( x ( n ) ) ∣ 2 ⇒ P ( k ) |DFT(x(n))|^2\Rightarrow P(k) ∣DFT(x(n))∣2⇒P(k)
功率谱的傅立叶逆变换实际上是一个自相关序列[Wiener–Khinchin theorem]。
I D F T ( P ( k ) ) ⇒ A ( n ) IDFT(P(k))\Rightarrow A(n) IDFT(P(k))⇒A(n)
而在逆变换之前先做一个对数,那么逆变换的结果就是倒谱。
I D F T ( l o g ( P ( k ) ) ) ⇒ C ( n ) IDFT(log(P(k)))\Rightarrow C(n) IDFT(log(P(k)))⇒C(n)
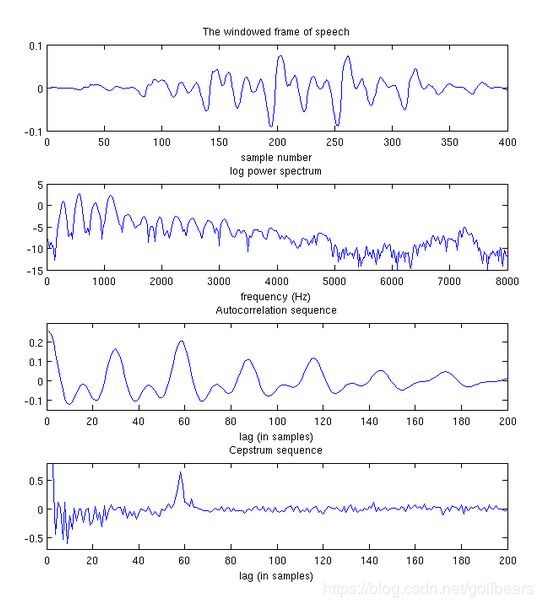 在上述图片中,展示了原始语音信号的一帧数据、对数功率谱、自相关序列和倒谱。倒谱当中的峰值对应自相关序列当中的一个峰值,但是更为清晰。这个峰值的位置在58sample位置处,对应的基音频率为(16000/58)=275Hz (信号采样率为16kHz)。这是一个相当高的基音频率,原始语音信号是从一位女性说话人得到的。因为倒谱的强峰值,所以经常被用于基音检测。
在上述图片中,展示了原始语音信号的一帧数据、对数功率谱、自相关序列和倒谱。倒谱当中的峰值对应自相关序列当中的一个峰值,但是更为清晰。这个峰值的位置在58sample位置处,对应的基音频率为(16000/58)=275Hz (信号采样率为16kHz)。这是一个相当高的基音频率,原始语音信号是从一位女性说话人得到的。因为倒谱的强峰值,所以经常被用于基音检测。
LPCC(Linear Predictive Cepstral Coefficient)
这种所谓的线性预测倒谱系数几乎和计算倒谱的方法一致,除了利用平滑自回归(smoothed Auto-Regression)功率谱代替了前文提到的周期图谱估计。对于一个10阶的AR谱估计过程,利用Levinson Durbin algorithm计算前10个自相关系数得到10个线性预测系数。另外还有一种直接通过LPC码来得到LPCC的办法,可以参考[8],不是本篇重点,不做深入研究。需要提到的一点是Linear Prediction Coefficients (LPCs) and Linear Prediction Cepstral Coefficients (LPCCs)曾经是基于HMM模型ASR系统主流的语音特征提取方式,后来才被MFCC取代的。
MFCC
Mel Frequency Cepstral Ceofficient目前最主流的语音信号特征提取方式,相比ceptrum的流程,主要是增加了mel滤波,另外用DCT替换了IFFT。网上介绍的文章太多,流程列一下,详细略。[9]
preemphasis( y ( t ) = x ( t ) − α x ( t − 1 ) y(t)=x(t)-\alpha x(t-1) y(t)=x(t)−αx(t−1))
Frame the signal into short frames.(typical size 25ms, stripe 10ms)
For each frame calculate the periodogram estimate of the power spectrum.
Apply the mel filterbank to the power spectra, sum the energy in each filter.
Take the logarithm of all filterbank energies.
Take the DCT of the log filterbank energies.
Keep DCT coefficients 2-13, discard the rest.
MFSC
log mel-frequency spectral Coefficients比MFCC要简单,其实就是将MFCC的最后DCT部分省掉,只分析fiterbanks energies的对数,所以有的文献也将其称为Filter Banks。又因为这里也是对谱分析,所以不准确的说法也被称作spectrogram(语谱图),确切地说法可以叫做。mel对数语谱图。因为据说在人工智能神经网络的训练中,有证据[11]显示这个语音特征要比MFCC表现的优秀,所以在三种平台都支持MFSC(Filter Banks)的提取。
Spectrogram
经典的语谱图[12]是指经过短时傅立叶变换之后,将频域的能量信号影射成灰度(颜色)直方图,按照时间顺序绘制的二维图形,其中横轴为时间,纵轴为频率,每个频率线段的灰度深浅(颜色亮暗)表示该时刻对应的频谱分量的能量强弱。下图是经过mel滤波器组的log 功率谱,在语音识别过程往往更关注这个声谱图。

PLP:Perceptual Linear Predictive,感知线性预测)
是一种基于听觉模型的特征参数。简单的说,就是通过在不同的说话者之间变换他们语音频谱到最小的差别,同时又保留了重要的话音信息。该特征参数是全极点模型预测多项式的一组系数,等效于一种LPC( Linear Prediction Coefficient , 线性预测系数) 特征, 它们的不同之处是PLP 技术将人耳听觉试验获得的一些结论, 通过近似计算的方法进行了工程化处理, 应用到频谱分析中, 将输入的语音信号经听觉模型处理后所得到的信号替代传统的LPC 分析所用的时域信号。经过这样处理后的语音频谱考虑到了人耳的听觉特点, 因而有利于抗噪语音特征提取。[1] 其中,PLP和MFCC一个明显的区别是PLP选择了Bark频率尺度,MFCC则采用的mel频率尺度。
RASTA:Relative Spectral Transform
这是在语音信道中,一项针对频率子带的带同滤波分离技术,其目的是消除短期噪声波动,以及去除由于静态频谱污染而导致的频率固定偏移。经常将RASTA-PLP一起来使用。有两篇论文可以学习,H. Hermansky, “Perceptual linear predictive (PLP) analysis of speech”, H. Hermansky and N. Morgan, “RASTA processing of speech”。
Mel频率定标
暂略。
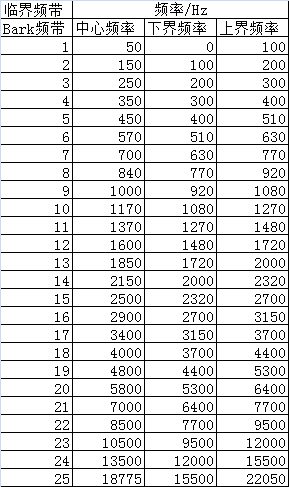
Bark频率
Bark(巴克)频率尺度是以Hz为单位,把频率映射到心理声学的24个临界频带上,第25个临界频带占据约:16K~20kHz的频率,1个临界频带的宽度等于一个Bark,简单的说,Bark尺度是把物理频率转换到心理声学的频率。
CMVN(Cepsturm Mean and Variance Normalization)
VTLN (特征级声道长度归一化)[3]
Kaldi 程序compute-mfcc-feats和compute-plp-feats接收一个VTLN(vocal tract length normalization )弯折因子选项。在目前的脚本中,这仅用作线性版的VTLN的初始化线性转换的一种方法。VTLN通过移动三角频率箱的中心频率的位置来实现。移动频率箱的弯折函数是一个在频域空间分段线性的函数。为理解它,记住以下数量关系:
0 <= low-freq <=vtln-low < vtln-high < high-freq <= nyquist
此处,low-freq和high-freq分别是用于标准MFCC或PLP计算的最低和最高频率(忽略更低和更高的频率)。vtln-low和vtln-high是用于VTLN的截止频率,它们的功能是确保所有梅尔滤波器有合适的宽度。
我们实现的VTLN弯折函数是一个分段线性函数,三个部分映射区间[low-freq,high-freq]至[low-freq, high-freq]。记弯折函数为W(f),f是频率。中段映射f到f/scale,scale是VTLN弯折因子(通常范围为0.8到1.2)。x轴上低段和中段的连接点是满足min(f,W(f)) = vtln-low的f点。x轴上中段和高端的连接点是满足max(f, W(f)) = vtln-high的f点。要求低段和高段的斜率和偏移是连续的且W(low-freq)=low-freq, W(high-freq)=high-freq。这个弯折函数和HTK的不同;HTK的版本中,"vtln-low"和"vtln-high"的数量关系是x轴上可以不连续的点,这意味着变量"vtln-high"必须基于弯折因子的可能范围的先验知识谨慎选择(否则梅尔滤波器可能为空)。
一个合理的设置如下(以16kHz采样的语音为例);注意这反映的是我们理解的合理值,并非任何非常细致的调试实验的结果。
low-freq vtln-low vtln-high high-freq nyquist
40 60 7200 7800 8000
HTK 的语音提取过程
HTK的代码是C语言,语音提取是一个集成工具HCopy实现的,这个工具可以利用配置文件和脚本文件(文件名)实现批处理。 HTK支持FFT和LPC两种语音信号的的分析,MFCC是基于FFT变换的对数谱分析,目前主流的选择。
 HCopy配置文件内容:
HCopy配置文件内容:
# Coding parameters
TARGETKIND = MFCC_0
TARGETRATE = 100000.0
SAVECOMPRESSED = T
SAVEWITHCRC = T
WINDOWSIZE = 250000.0
USEHAMMING = T
PREEMCOEF = 0.97
NUMCHANS = 26
CEPLIFTER = 22
NUMCEPS = 12
ENORMALISE = F
MFCC_0表示MFCC 用C0作为功率分量,10ms的帧周期(HTK 采用100ns单位),25ms的采样窗,以为着15ms的overlap。输出采用带crc检验的压缩格式,汉明窗,系数为0.97的一阶预加重,滤波器池有16个通道,产生12个MFCC系数,cep滤波系数22。如果处理静态文件ENORMALISE 默认是TRUE,因为最好对音频文件做归一化。实时数据处理需要关闭。[4]
具体阅读代码,涉及HCopy.c,HParms.c两级文件OpenSpeechFile->OpenParmFile->OpenBuffer->OpenAsChannel->FillBufFromChannel->GetFrameFromChannel->ConvertFrame, 在ConvertFrame函数里可以了解htk支持的语音特征
switch(btgt){
case LPC:
Wave2LPC(cf->s,cf->a,cf->k,&re,&te);
v = cf->a; bsize = cf->lpcOrder;
break;
case LPREFC:
Wave2LPC(cf->s,cf->a,cf->k,&re,&te);
v = cf->k; bsize = cf->lpcOrder;
break;
case LPCEPSTRA:
Wave2LPC(cf->s,cf->a,cf->k,&re,&te);
LPC2Cepstrum(cf->a,cf->c);
if (cf->cepLifter > 0)
WeightCepstrum(cf->c, 1, cf->numCepCoef, cf->cepLifter);
v = cf->c; bsize = cf->numCepCoef;
break;
case MELSPEC:
case FBANK:
Wave2FBank(cf->s, cf->fbank, rawE?NULL:&te, cf->fbInfo);
v = cf->fbank; bsize = cf->numChans;
break;
case MFCC:
Wave2FBank(cf->s, cf->fbank, rawE?NULL:&te, cf->fbInfo);
FBank2MFCC(cf->fbank, cf->c, cf->numCepCoef);
if (cf->cepLifter > 0)
WeightCepstrum(cf->c, 1, cf->numCepCoef, cf->cepLifter);
v = cf->c; bsize = cf->numCepCoef;
break;
case PLP:
Wave2FBank(cf->s, cf->fbank, rawE ? NULL : &te, cf->fbInfo);
FBank2ASpec(cf->fbank, cf->as, cf->eql, cf->compressFact, cf->fbInfo);
ASpec2LPCep(cf->as, cf->ac, cf->lp, cf->c, cf->cm);
if (cf->cepLifter > 0)
WeightCepstrum(cf->c, 1, cf->numCepCoef, cf->cepLifter);
v = cf->c;
bsize = cf->numCepCoef;
break;
default:
HError(6321,"ConvertFrame: target %s is not a parameterised form",
ParmKind2Str(cf->tgtPK,buf));
}
上述格式的简单解释如下:
0 WAVEFORM sampled waveform
1 LPC linear prediction filter coefficients
2 LPREFC linear prediction reflection coefficients
3 LPCEPSTRA LPC cepstral coefficients
4 LPDELCEP LPC cepstra plus delta coefficients
5 IREFC LPC reflection coef in 16 bit integer format
6 MFCC mel-frequency cepstral coefficients
7 FBANK log mel-filter bank channel outputs
8 MELSPEC linear mel-filter bank channel outputs
9 USER user defined sample kind
10 DISCRETE vector quantised data
11 PLP PLP cepstral coefficients
对于语音识别来说,最主流的LPC,MFCC,FBANK(MFSC)和PLP都是支持的。语音特征提取的实现代码在HSig.c文件实现,函数实现非常简洁,按功能分如下类别:
1.Initialisation
2.Windowing and PreEmphasis
3.Linear Prediction Coding Operations
4.FFT Based Operations
5.MFCC Related Operations
6.PLP Related Operations
7.Feature Level Operations
Kaldi 语音提取过程
HTK实现简单,Kaldi相比之下要复杂很多,当然也实现了很多扩展功能,另外是C++代码实现的,学习起来难度也大一点。现粗略的研究一下kaldi的文件系统,关于语音提取的核心代码都存放在src/feat目录下面,摘取目录下的文件:
-rw-rw-r-- 1 6961 2月 25 2019 feature-common.h
-rw-rw-r-- 1 3552 2月 25 2019 feature-common-inl.h
-rw-rw-r-- 1 4654 2月 25 2019 feature-fbank.cc
-rw-rw-r-- 1 5738 2月 25 2019 feature-fbank.h
-rw-rw-r-- 1 602408 2月 26 2019 feature-fbank.o
-rw-rw-r-- 1 14375 2月 25 2019 feature-fbank-test.cc
-rw-rw-r-- 1 14081 2月 25 2019 feature-functions.cc
-rw-rw-r-- 1 8240 2月 25 2019 feature-functions.h
-rw-rw-r-- 1 641416 2月 26 2019 feature-functions.o
-rw-rw-r-- 1 3473 2月 25 2019 feature-functions-test.cc
-rw-rw-r-- 1 5751 2月 25 2019 feature-mfcc.cc
-rw-rw-r-- 1 5992 2月 25 2019 feature-mfcc.h
-rw-rw-r-- 1 623984 2月 26 2019 feature-mfcc.o
-rw-rw-r-- 1 21832 2月 25 2019 feature-mfcc-test.cc
-rw-rw-r-- 1 7092 2月 25 2019 feature-plp.cc
-rw-rw-r-- 1 6682 2月 25 2019 feature-plp.h
-rw-rw-r-- 1 739936 2月 26 2019 feature-plp.o
-rw-rw-r-- 1 4842 2月 25 2019 feature-plp-test.cc
-rw-rw-r-- 1 6183 2月 25 2019 feature-sdc-test.cc
-rw-rw-r-- 1 3085 2月 25 2019 feature-spectrogram.cc
-rw-rw-r-- 1 3990 2月 25 2019 feature-spectrogram.h
-rw-rw-r-- 1 463488 2月 26 2019 feature-spectrogram.o
-rw-rw-r-- 1 8552 2月 25 2019 feature-window.cc
-rw-rw-r-- 1 9226 2月 25 2019 feature-window.h
-rw-rw-r-- 1 452104 2月 26 2019 feature-window.o
-rw-rw-r-- 1 12811 2月 25 2019 mel-computations.cc
-rw-rw-r-- 1 6326 2月 25 2019 mel-computations.h
-rw-rw-r-- 1 580752 2月 26 2019 mel-computations.o
-rw-rw-r-- 1 23051 2月 25 2019 online-feature.cc
-rw-rw-r-- 1 22674 2月 25 2019 online-feature.h
-rw-rw-r-- 1 1377288 2月 26 2019 online-feature.o
-rw-rw-r-- 1 12798 2月 25 2019 online-feature-test.cc
-rw-rw-r-- 1 69223 2月 25 2019 pitch-functions.cc
-rw-rw-r-- 1 20893 2月 25 2019 pitch-functions.h
-rw-rw-r-- 1 1279120 2月 26 2019 pitch-functions.o
-rw-rw-r-- 1 23617 2月 25 2019 pitch-functions-test.cc
-rw-rw-r-- 1 15836 2月 25 2019 resample.cc
-rw-rw-r-- 1 12167 2月 25 2019 resample.h
-rw-rw-r-- 1 608376 2月 26 2019 resample.o
-rw-rw-r-- 1 10045 2月 25 2019 resample-test.cc
-rw-rw-r-- 1 4797 2月 25 2019 signal.cc
-rw-rw-r-- 1 2048 2月 25 2019 signal.h
-rw-rw-r-- 1 482464 2月 26 2019 signal.o
-rw-rw-r-- 1 2013 2月 25 2019 signal-test.cc
-rw-rw-r-- 1 12372 2月 25 2019 wave-reader.cc
-rw-rw-r-- 1 7544 2月 25 2019 wave-reader.h
-rw-rw-r-- 1 286704 2月 26 2019 wave-reader.o
-rw-rw-r-- 1 6902 2月 25 2019 wave-reader-test.cc
可以看出支持fbank,mfcc,spectrogram,pitch和mel单独实现,做的事情要比htk多,而且工具包有兼容HTK的选项,说明kaldi在语音特征提取方面更丰富,扩展性更好。
W2l语音提取过程
w2l给予人工智能神经网络的ASR平台,语音特征提取的代码在/src/libraries/features目录,文件组织也比较清晰:
-rw-rw-r-- 1 1251 9月 18 15:51 Ceplifter.cpp
-rw-rw-r-- 1 841 9月 18 15:51 Ceplifter.h
-rw-rw-r-- 1 1392 9月 18 15:51 CMakeLists.txt
-rw-rw-r-- 1 949 9月 18 15:51 Dct.cpp
-rw-rw-r-- 1 781 9月 18 15:51 Dct.h
-rw-rw-r-- 1 2669 9月 18 15:51 Derivatives.cpp
-rw-rw-r-- 1 1016 9月 18 15:51 Derivatives.h
-rw-rw-r-- 1 854 9月 18 15:51 Dither.cpp
-rw-rw-r-- 1 991 9月 18 15:51 Dither.h
-rw-rw-r-- 1 4519 9月 18 15:51 FeatureParams.h
-rw-rw-r-- 1 2284 9月 18 15:51 Mfcc.cpp
-rw-rw-r-- 1 2420 9月 18 15:51 Mfcc.h
-rw-rw-r-- 1 3475 9月 18 15:51 Mfsc.cpp
-rw-rw-r-- 1 1121 9月 18 15:51 Mfsc.h
-rw-rw-r-- 1 4742 9月 18 15:51 PowerSpectrum.cpp
-rw-rw-r-- 1 1603 9月 18 15:51 PowerSpectrum.h
-rw-rw-r-- 1 1488 9月 18 15:51 PreEmphasis.cpp
-rw-rw-r-- 1 688 9月 18 15:51 PreEmphasis.h
-rw-rw-r-- 1 2514 9月 18 15:51 SpeechUtils.cpp
-rw-rw-r-- 1 638 9月 18 15:51 SpeechUtils.h
-rw-rw-r-- 1 2979 9月 18 15:51 TriFilterbank.cpp
-rw-rw-r-- 1 1322 9月 18 15:51 TriFilterbank.h
-rw-rw-r-- 1 1631 9月 18 15:51 Windowing.cpp
-rw-rw-r-- 1 730 9月 18 15:51 Windowing.h
可以看出w2l支持MFCC和MFSC两种语音特征提取,其他的暂时没有支持。
小结
本文对三种平台的语音提取简单对比学习了一下。因为HTK是c代码实现,可以非常好的为嵌入式平台移植提供参考,但license受保护,学习和移植的时候需要遵守和注意。另外两个平台是用C++实现的,阅读和移植参考稍微麻烦,但是license比较友好,可以这个代码移植来使用,只能说各有所长吧。
参考文献
1.《噪声条件下的语音特征PLP 参数的提取》魏艳,张雪英, 太原理工大学 信息工程学院
2. 《基于Mel倒谱和Bark谱失真距离的汉语音质客观评价研究》云霞,西南交通大学,硕士论文
3. 《kaldi中的特征提取》https://blog.csdn.net/wbgxx333/article/details/25778483
4. 《htkbook-3.5.alpha-1》
5. 《音频处理中的尺度–Bark尺度与Mel尺度》https://blog.csdn.net/icoolmedia/article/details/51594776
6. 《【自动语音识别课程】第二课 语音信号分析》https://blog.csdn.net/joey_su/article/details/36414877
7. 《Speech Processing for Machine Learning: Filter banks, Mel-Frequency Cepstral Coefficients (MFCCs) and What’s In-Between》https://haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html
8. 《A Tutorial on Cepstrum and LPCCs》http://www.practicalcryptography.com/miscellaneous/machine-learning/tutorial-cepstrum-and-lpccs/
9. 《Mel Frequency Cepstral Coefficient (MFCC) tutorial》http://www.practicalcryptography.com/miscellaneous/machine-learning/guide-mel-frequency-cepstral-coefficients-mfccs/
10. https://github.com/jameslyons/python_speech_features
11. 《Deep Neural Network acoustic models for ASR》Abdel-rahman Mohamed
12. 《Theory and Applications of Digital Speech Processing》Lawrence R. Rabiner,Ronald W. Schafer