SPI机制的原理和应用
前言
SPI ,全称为 Service Provider Interface,是一种服务发现机制。它通过在ClassPath路径下的 META-INF/services 文件夹查找文件,自动加载文件里所定义的类。
这一机制为很多框架的扩展提供了可能,比如在 Dubbo、JDBC、SpringBoot 中都使用到了SPI机制。虽然他们之间的实现方式不同,但原理都差不多。今天我们就来看看,SPI到底是何方神圣,在众多开源框架中又扮演了什么角色。
一、JDK中的SPI
我们先从JDK开始,通过一个很简单的例子来看下它是怎么用的。
1、小栗子
首先,我们需要定义一个接口,SpiService
public interface SpiService {
void println();
}
然后,定义一个实现类,没别的意思,只做打印。
public class SpiServiceImpl implements SpiService {
@Override
public void println() {
System.out.println("------SPI DEMO-------");
}
}
最后呢,要在resources路径下配置添加一个文件。文件名字是接口的全限定类名,内容是实现类的全限定类名,多个实现类用换行符分隔。

文件内容就是实现类的全限定类名:
com.jcc.java.spi.SpiInterfaceImpl
2、测试
然后我们就可以通过 ServiceLoader.load 方法拿到实现类的实例,并调用它的方法。
public static void main(String[] args){
ServiceLoader<SpiService> load = ServiceLoader.load(SpiService.class);
Iterator<SpiService> iterator = load.iterator();
while (iterator.hasNext()){
SpiService service = iterator.next();
service.println();
}
}
3、源码分析
首先,我们先来了解下 ServiceLoader,看看它的类结构。
public final class ServiceLoader<S> implements Iterable<S>{
//配置文件的路径
private static final String PREFIX = "META-INF/services/";
//加载的服务类或接口
private final Class<S> service;
//已加载的服务类集合
private LinkedHashMap<String,S> providers = new LinkedHashMap<>();
//类加载器
private final ClassLoader loader;
//内部类,真正加载服务类
private LazyIterator lookupIterator;
}
当我们调用 load 方法时,并没有真正的去加载和查找服务类。而是调用了 ServiceLoader 的构造方法,在这里最重要的是实例化了内部类 LazyIterator ,它才是接下来的主角。
private ServiceLoader(Class<S> svc, ClassLoader cl) {
//要加载的接口
service = Objects.requireNonNull(svc, "Service interface cannot be null");
//类加载器
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
//访问控制器
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
//先清空
providers.clear();
//实例化内部类
LazyIterator lookupIterator = new LazyIterator(service, loader);
}
查找实现类和创建实现类的过程,都在 LazyIterator 完成。当我们调用 iterator.hasNext和iterator.next 方法的时候,实际上调用的都是 LazyIterator 的相应方法。
public Iterator<S> iterator() {
return new Iterator<S>() {
public boolean hasNext() {
return lookupIterator.hasNext();
}
public S next() {
return lookupIterator.next();
}
.......
};
}
所以,我们重点关注 lookupIterator.hasNext() 方法,它最终会调用到 hasNextServicez ,在这里返回实现类名称。
private class LazyIterator implements Iterator<S>{
Class<S> service;
ClassLoader loader;
Enumeration<URL> configs = null;
Iterator<String> pending = null;
String nextName = null;
private boolean hasNextService() {
//第二次调用的时候,已经解析完成了,直接返回
if (nextName != null) {
return true;
}
if (configs == null) {
//META-INF/services/ 加上接口的全限定类名,就是文件服务类的文件
//META-INF/services/com.viewscenes.netsupervisor.spi.SPIService
String fullName = PREFIX + service.getName();
//将文件路径转成URL对象
configs = loader.getResources(fullName);
}
while ((pending == null) || !pending.hasNext()) {
//解析URL文件对象,读取内容,最后返回
pending = parse(service, configs.nextElement());
}
//拿到第一个实现类的类名
nextName = pending.next();
return true;
}
}
然后当我们调用 next() 方法的时候,调用到 lookupIterator.nextService 。它通过反射的方式,创建实现类的实例并返回。
private S nextService() {
//全限定类名
String cn = nextName;
nextName = null;
//创建类的Class对象
Class<?> c = Class.forName(cn, false, loader);
//通过newInstance实例化
S p = service.cast(c.newInstance());
//放入集合,返回实例
providers.put(cn, p);
return p;
}
到这为止,已经获取到了类的实例。
二、JDBC中的应用
我们开头说,SPI机制为很多框架的扩展提供了可能,其实JDBC就应用到了这一机制。
在以前,需要先设置数据库驱动的连接,再通过 DriverManager.getConnection 获取一个 Connection 。
String url = "jdbc:mysql:///consult?serverTimezone=UTC";
String user = "root";
String password = "root";
Class.forName("com.mysql.jdbc.Driver");
Connection connection = DriverManager.getConnection(url, user, password);
而现在,设置数据库驱动连接,这一步骤就不再需要,那么它是怎么分辨是哪种数据库的呢?答案就在SPI。
1、加载
我们把目光回到 DriverManager 类,它在静态代码块里面做了一件比较重要的事。很明显,它已经通过SPI机制, 把数据库驱动连接初始化了。
public class DriverManager {
static {
loadInitialDrivers();
println("JDBC DriverManager initialized");
}
}
具体过程还得看 loadInitialDrivers ,它在里面查找的是Driver接口的服务类,所以它的文件路径就是:
META-INF/services/java.sql.Driver
private static void loadInitialDrivers() {
AccessController.doPrivileged(new PrivilegedAction<Void>() {
public Void run() {
//很明显,它要加载Driver接口的服务类,Driver接口的包为:java.sql.Driver
//所以它要找的就是META-INF/services/java.sql.Driver文件
ServiceLoader<Driver> loadedDrivers = ServiceLoader.load(Driver.class);
Iterator<Driver> driversIterator = loadedDrivers.iterator();
try{
//查到之后创建对象
while(driversIterator.hasNext()) {
driversIterator.next();
}
} catch(Throwable t) {
// Do nothing
}
return null;
}
});
}
那么,这个文件哪里有呢?我们来看MySQL的jar包,就是这个文件,文件内容为: com.mysql.cj.jdbc.Driver 。
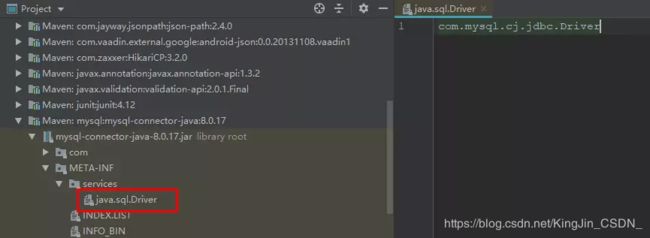
2、创建实例
上一步已经找到了MySQL中的 com.mysql.cj.jdbc.Driver 全限定类名,当调用next方法时,就会创建这个类的实例。它就完成了一件事,向 DriverManager 注册自身的实例。
public class Driver extends NonRegisteringDriver implements java.sql.Driver {
static {
try {
//注册、调用DriverManager类的注册方法
//往registeredDrivers集合中加入实例
DriverManager.registerDriver(new Driver());
} catch (SQLException var1) {
throw new RuntimeException("Can't register driver!");
}
}
}
3、创建Connection
DriverManager.getConnection() 方法就是创建连接的地方,它通过循环已注册的数据库驱动程序,调用其connect方法,获取连接并返回。
private static Connection getConnection(String url, Properties info, Class<?> caller) throws SQLException {
//registeredDrivers中就包含com.mysql.cj.jdbc.Driver实例
for(DriverInfo aDriver : registeredDrivers) {
if(isDriverAllowed(aDriver.driver, callerCL)) {
try {
//调用connect方法创建连接
Connection con = aDriver.driver.connect(url, info);
if (con != null) {
return (con);
}
}catch (SQLException ex) {
if (reason == null) {
reason = ex;
}
}
} else {
println("skipping: " + aDriver.getClass().getName());
}
}
}
4、扩展
既然我们知道JDBC是这样创建数据库连接的,我们能不能再扩展一下呢?如果我们自己也创建一个 java.sql.Driver 文件,自定义实现类MySQLDriver,那么,在获取连接的前后就可以动态修改一些信息。
还是先在项目resources下创建文件,文件内容为自定义驱动类 com.jcc.java.spi.domyself.MySQLDriver
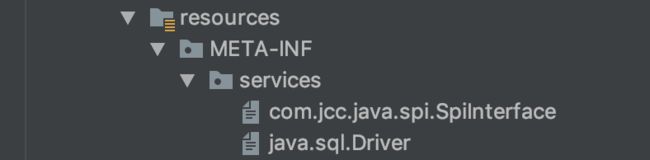
我们的 MySQLDriver 实现类,继承自MySQL中的 NonRegisteringDriver ,还要实现 java.sql.Driver 接口。这样,在调用connect方法的时候,就会调用到此类,但实际创建的过程还靠MySQL完成。
public class MySQLDriver extends NonRegisteringDriver implements Driver{
static {
try {
DriverManager.registerDriver(new MySQLDriver());
} catch (SQLException e) {
e.printStackTrace();
}
}
public MySQLDriver() throws SQLException {}
@Override
public Connection connect(String url, Properties info) throws SQLException {
System.out.println("准备创建数据库连接.url:"+url);
System.out.println("JDBC配置信息:"+info);
//重置配置
info.setProperty("user", "root");
Connection connection = super.connect(url, info);
System.out.println("数据库连接创建完成!"+connection.toString());
return connection;
}
}
这样的话,当我们获取数据库连接的时候,就会调用到这里。
--------------------输出结果---------------------
准备创建数据库连接.url:jdbc:mysql:///consult?serverTimezone=UTC
JDBC配置信息:{user=root, password=root}
数据库连接创建完成!com.mysql.cj.jdbc.ConnectionImpl@7cf10a6f
三、SpringBoot中的应用
Spring Boot提供了一种快速的方式来创建可用于生产环境的基于Spring的应用程序。它基于Spring框架,更倾向于约定而不是配置,并且旨在使您尽快启动并运行。
即便没有任何配置文件,SpringBoot的Web应用都能正常运行。这种神奇的事情,SpringBoot正是依靠自动配置来完成。
说到这,我们必须关注一个东西: SpringFactoriesLoader,自动配置就是依靠它来加载的。
1、配置文件
SpringFactoriesLoader 来负责加载配置。我们打开这个类,看到它加载文件的路径是: META-INF/spring.factories

笔者在项目中搜索这个文件,发现有4个Jar包都包含它:
- List itemspring-boot-2.1.9.RELEASE.jar
- spring-beans-5.1.10.RELEASE.jar
- spring-boot-autoconfigure-2.1.9.RELEASE.jar
- mybatis-spring-boot-autoconfigure-2.1.0.jar
那么它们里面都是些啥内容呢?其实就是一个个接口和类的映射。在这里笔者就不贴了,有兴趣的小伙伴自己去看看。
比如在SpringBoot启动的时候,要加载所有的 ApplicationContextInitializer ,那么就可以这样做:
SpringFactoriesLoader.loadFactoryNames(ApplicationContextInitializer.class, classLoader)
2、加载文件
loadSpringFactories 就负责读取所有的 spring.factories 文件内容。
private static Map<String, List<String>> loadSpringFactories(@Nullable ClassLoader classLoader) {
MultiValueMap<String, String> result = cache.get(classLoader);
if (result != null) {
return result;
}
try {
//获取所有spring.factories文件的路径
Enumeration<URL> urls = lassLoader.getResources("META-INF/spring.factories");
result = new LinkedMultiValueMap<>();
while (urls.hasMoreElements()) {
URL url = urls.nextElement();
//加载文件并解析文件内容
UrlResource resource = new UrlResource(url);
Properties properties = PropertiesLoaderUtils.loadProperties(resource);
for (Map.Entry<?, ?> entry : properties.entrySet()) {
String factoryClassName = ((String) entry.getKey()).trim();
for (String factoryName : StringUtils.commaDelimitedListToStringArray((String) entry.getValue())) {
result.add(factoryClassName, factoryName.trim());
}
}
}
cache.put(classLoader, result);
return result;
}
catch (IOException ex) {
throw new IllegalArgumentException("Unable to load factories from location [" +
FACTORIES_RESOURCE_LOCATION + "]", ex);
}
}
可以看到,它并没有采用JDK中的SPI机制来加载这些类,不过原理差不多。都是通过一个配置文件,加载并解析文件内容,然后通过反射创建实例。
3、参与其中
假如你希望参与到 SpringBoot 初始化的过程中,现在我们又多了一种方式。
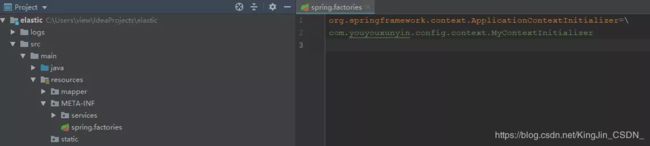
我们也创建一个 spring.factories 文件,自定义一个初始化器。
org.springframework.context.ApplicationContextInitializer=com.youyouxunyin.config.context.MyContextInitializer
然后定义一个MyContextInitializer类
public class MyContextInitializer implements ApplicationContextInitializer {
@Override
public void initialize(ConfigurableApplicationContext configurableApplicationContext) {
System.out.println(configurableApplicationContext);
}
}
四、Dubbo中的应用
我们熟悉的Dubbo也不例外,它也是通过 SPI 机制加载所有的组件。同样的,Dubbo 并未使用 Java 原生的 SPI 机制,而是对其进行了增强,使其能够更好的满足需求。在 Dubbo 中,SPI 是一个非常重要的模块。基于 SPI,我们可以很容易的对 Dubbo 进行拓展。
关于原理,如果有小伙伴不熟悉,可以参阅笔者文章:
Dubbo中的SPI和自适应扩展机制
它的使用方式同样是在 META-INF/services 创建文件并写入相关类名。
关于使用场景,可以参考: SpringBoot+Dubbo集成ELK实战
转载地址
Dubbo地址