儿子的复习笔记
http://blog.csdn.net/dango_miracle/article/details/79076562
98帖子
http://www.cc98.org/topic/4320324/1#1
语音部分知识点
– 语音技术引言(语音链,语音产生数字模型,重要假设【短时平稳?】)
语音链
发声 - 传递 - 感知 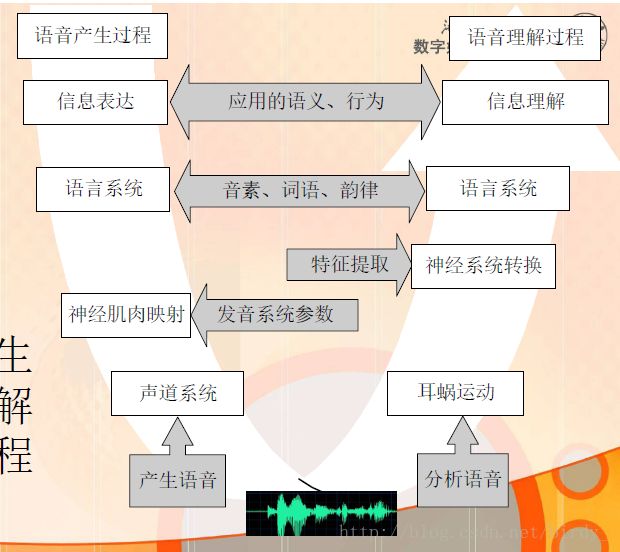
语音产生数字模型 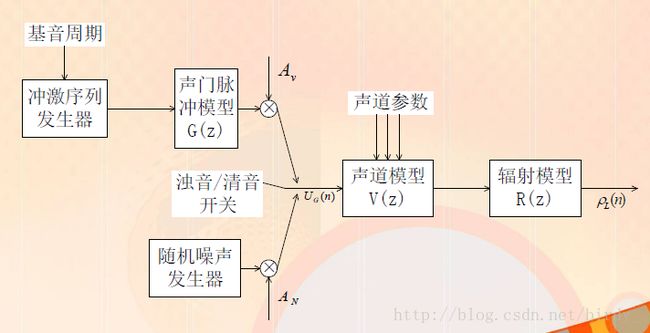
我真不知道先人是怎么弄出那么复杂的表达式的orz
然后就每一个阶段都会有一个式子然后最后得到最终结果
U之前是产生,激励模型
之后是声道模型,分为声管模型和共振峰模型
短时平稳假设
语音信号特性是随时间而变化的,本质上是一个非平稳过程。但不同的语音是由人的口腔肌肉运动构成声道的某种形状而产生的响应,而这种肌肉运动频率相对于语音频率来说是缓慢的,因而在一个短时间范围内,其特性基本保持不变,即相对稳定,可以视作一个准稳态过程。基于这样的考虑,对语音信号进行分段考虑,每一段称为一帧(frame).一般假设为10-30ms的短时间隔。
– 语音分析(时域特征,端点检测,语图,频域特征,MFCC )
时域特征 时域波形很难反映语音感知特性,且易受环境变化影响。
音量 Volume
过零率 Zero Crossing Rate
音高/基音周期 Pitch
频域
共振峰Formant
音高/基音周期 Pitch
特征提取
预加重
分帧
加窗
特征参数
倒谱归一化
特征参数:静态参数 MFCC
DCT
Mel (24-40个滤波器)
Log 对数能量
DCT
帧能量
动态参数
– 语音模型(DTW、VQ、HMM、GMM)
动态时间规整(DTW)
语音配准,对线性调整的优化
• 适用场合
– DTW适合于特定人、基元较少的场合
– 多用于孤立词识别
• DTW的问题:
– 运算量较大;
– 识别性能过分依赖于端点检测;
– 太依赖于说话人的原来发音;
– 不能对样本作动态训练;
– 没有充分利用语音信号的时序动态特性;
矢量量化(VQ)
这个和常见的聚类差不多啊……为啥词汇完全不一样……
通常把一帧(短时窗)语音对应的特征参数(LPCC,MFCC…)
用矢量表示,并称为特征矢量或特征向量;
聚类 - 生成码本
归类 - 量化 最小失真原则
量化失真 - 量化起最优是说平均/期望量化失真最小
隐马尔科夫模型(HMM)
• MM
– 状态可见,状态即观测结果
• HMM
– 状态不可见,但状态之间的转移仍然是概率的
– 观测/输出结果是状态的概率函数
离散HMM - DHMM
– 说话人识别
VQ 和 GMM
好奇为啥特意把这两种拎出来别的不行吗
然后我放弃下面这个文档了
Ch1 Introduction
语音是如何在wave中code的
讲了语音链的一些概览性的东西,然后讲了一下几个方向
1.1 The Speech Chain 语音链
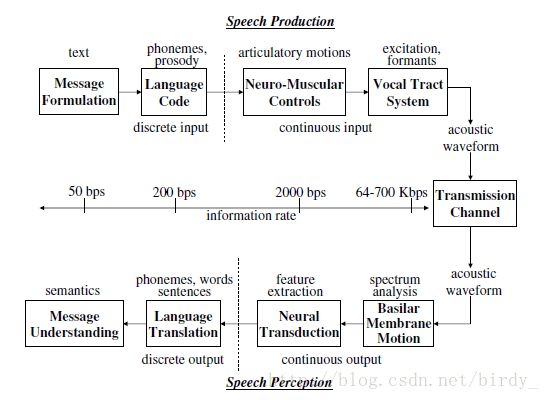
上面一条:语言产生
文本-语言-神经肌肉运动【舌头啥的】-vocal tract system【声源】
各自的bps 所以可以有各种sample rate
下面一条:语言理解
内耳 acoustic waveform to a spectral representation
the spectral features into a set of sound features
大脑的语言理解进程 the sound features into the set of phonemes,words and sentences
常认为在大脑内部
右边:
最简单的是开放空间 
语言理解的应用
语言的编码 MP3啥的 传输格式
文本-语言
语言识别和其他的匹配问题
Ch2 The Speech Signal
前面的应用大多是把信息的数字信号转回语音链中
这一章讲语音学概览并且介绍语音信号模型
语言特征
语言产生模型
Ch3 Hearing and Auditory Perception
3.2 Perception of Loudness
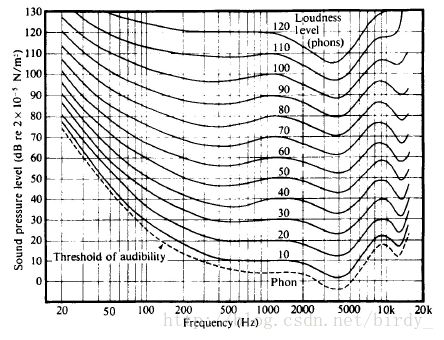
3.3 Critical Bands
临界带宽 
在一定区域内会相互干扰 ![]()
3.4 Pitch Perception 音高
Ch4 Short-Time Analysis of Speech
4.1 Short-Time Energy and Zero-Crossing Rate
短时能量和过零率
4.2 Short-Time Autocorrelation Function (STACF)
4.3 Short-Time Fourier Transform (STFT)
4.4 Sampling the STFT in Time and Frequency
4.5 The Speech Spectrogram
Ch5 Homomorphic Speech Analysis
5.1 Definition of the Cepstrum and Complex Cepstrum
5.6.3 Mel-Frequency Cepstrum Coefficients
5.7 The Role of the Cepstrum
Ch9 Automatic Speech Recognition
9.1 The Problem of Automatic Speech Recognition
9.2 Building a Speech Recognition System
9.3.1 Mathematical Formulation of the ASR Problem
9.3.2 The Hidden Markov Model
下图@Sunn.

视频
三种帧类型
IF——I-frame的缩写,即关键帧。关键帧是构成一个帧组(GOP,Group of Picture)的第一个帧。IF保留了一个场景的所有信息。压缩比为1:7。
PF——P-frame的缩写,即未来单项预测帧,只储存与之前一个已解压画面的差值。压缩比为1:20。
BF——B-frame的缩写,即双向预测帧,除了参考之前解压过了的画面外,亦会参考后面一帧中的画面信息。压缩比为1:50。
B-Frame(在 MPEG-4 里面正确的名称是 B-VOP)的预测模式有四种:
a. Forward 顺向预测,参考前一张画面,记录和前一张画面的差距。和 P-Frame 的预测方法一样。
b. Backward 逆向预测,参考下一张画面,记录和下一张画面的的差距。
c. Bi-Directionally 双向预测,参考前面和后面两张画面,记录的是和「前后两张画面的平均值」的差距。也叫做内插预测,压缩率最高。
d. Direct Mode,不搜寻、纪录动作向量,直接由下一张的 P Frame推导出动作向量。譬如说 I B P,我们可以预测 B画面的动作必然是介于 I 和 P 两个画面之间,所以我们可以直接用 P 的 MV/2 作为B 的动作向量,这样可以省去记录 MV 的空间。
压缩 B-Frame 的时候会从上面几种预测模式中选压出来最小的一个模式来使用。