利用 Python 爬取了近 3000 条单身女生的数据,究竟她们理想的择偶标准是什么?
灵感来源与学习:利用 Python 爬取了 13966 条运维招聘信息,我得出了哪些结论?
本文原创作者:壹加柒
本文来源链接:https://blog.csdn.net/yu1300000363/article/details/107316568
前几天手机上CSDN推荐了一篇文章《利用 Python 爬取了 13966 条运维招聘信息,我得出了哪些结论?》,恰好最近也在学习爬虫相关知识,打开一看,从数据的爬取——》数据的清洗——》数据的可视化,涵盖的知识是很多我从前没有尝试过的。之前一直的实战一直停留在数据的爬取,没有对数据进行分析使得数据在我手上似乎失去了价值。
于是我想着跟着这篇文章的思路,爬取个有意思的网站。本来想着爬取学校的数据,但学校也没啥好爬的,而且稍不注意爬取到私密数据,也有可能会凉凉,然后送上一副银手镯。现在的单身(多的吧,哈哈,那就爬取婚恋网站的数据,分析样本来祝你脱单一臂之力!)
说干就干,没想到一干就花了整整三天,如果觉得文章对你有帮助,那就点个赞吧。下面正式开始。
- 先把结果晒一下,不知道会不会影响大家的心情哈哈哈

- 你达到均值了吗?
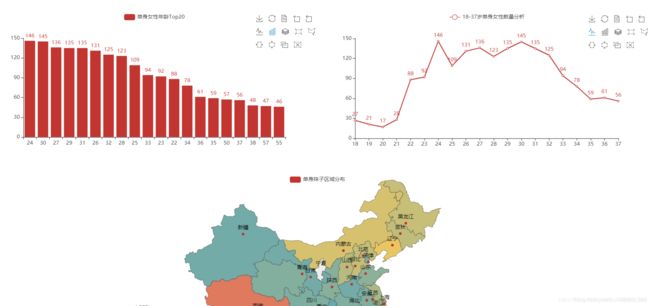
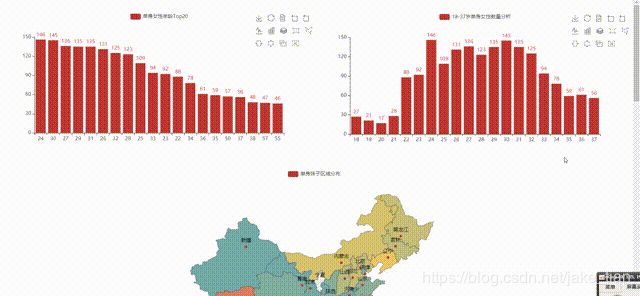
这里展示了可视化后的一部分数据, 看第二张表可以看出,在百合网发布相亲的女性集中在22-34岁,有点符合正态分布哈哈哈
1、目标分析
我在分析了 世纪佳缘、有缘网、百合网后发现,出百合网外,其余两个网站非会员限制查看匹配求偶信息数,一般只有10多条数据,不充钱,你依旧是那单身的少年。可能有些接口会没进行处理,大家可自行摸索(我在分析百合网的时候发现了一些有意思的接口)。于是我为了方便决定爬取百合网。
| 爬取目标 | 百合网 |
|---|---|
| 网站地址 | https://www.baihe.com/ |
| 样本大小 | 2875条 |
| 爬取对象 | 单身女性 |
| 分析数据 | 年龄、身高、地区、择偶要求等 |
2、爬取数据
在爬取数据这一块整整花了一天多的时间,遇到了很多问题,比如相应到的非JSON格式数据、分析了很多接口等等。有些细节忘记了,因为实战比较少,所以对于有些反爬机制没有点头绪。
2.1、动态加载
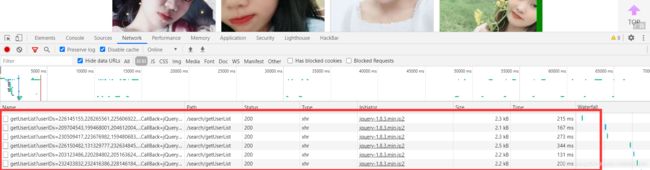
分析了搜索页,这里默认了地区和年龄作为搜索条件。在下拉时候数据是动态加载的,抓包发现动态加载的数据是通过发送Post请求。
-
很有意思的是Post的Data域中携带了两个参数:userIDs、jsonCallBack
-
userIDs:包含了8个用户的ID,查询用户信息时可以通过添加用户ID。
-
jsonCallBack:这个参数很诡异(如:jQuery18303820131843585586_1594609772504),后面的可以看出是时间戳,前面的是啥?这个参数重不重要?
经过翻阅资料以及无携带参数访问,发现这个参数是重要的:
https://www.runoob.com/json/json-jsonp.html
https://www.cnblogs.com/xmaomao/p/3360989.html
2.2、获得userID集合
-
在上一个动态加载数据时发送请求的参数很奇怪,这些参数是哪来的呢?
-
在访问搜索这一页面的初次时,已经首次加载了userID集合,请求参数包括年龄、城市、身高等等10多个呢~
这边有个page的参数,到时候换页需要用上

这边存放了100多个user的ID

再看看这段js代码,原来是从上边取出了8个UID,这也就解释了这些参数的来源
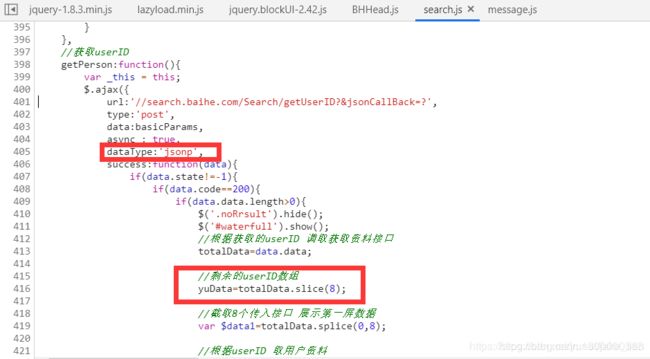
- 上边我把dataType也圈了出来,因为相应的参数非正常JSON格式,我在这里花了很久,也发现了一些蛮好玩的接口。
我把响应的数据进行了格式化,最终通过正则,又变成了我熟悉的JSON字符串~ 这样提取也就方便了
url_tails = session.post(url=url_base, headers=HEADERS, data=data).content.decode('utf-8')
json_data = re.search(r'jQuery1830923921797491073_1594465799055\((.*)\);', url_tails, flags=0)
2.3、获得个人信息页数据
- URL分析:
https://profile1.baihe.com/?oppID=229672724
由此可见,个人信息页数据结构是 https://profile1.baihe.com/?oppID= + 上边的解析出的UID
通过循环遍历每个UID提取到个人信息页我们所需要的的数据
个人信息页面分析
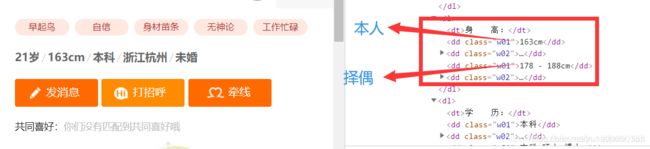
分析了下这几个参数,发现第一个是女生的信息,第二个是理想伴偶的标准
这样大致知道了页面结构,接下来给爷爬!
# 需要获得的数据,通过xpath解析
# 女生年龄
me_age.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[2]/dd[1]/text()')[0])
# 女生身高
me_height.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[3]/dd[1]/text()')[0])
# 女生教育
me_education.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[4]/dd[1]/text()')[0])
# 女生薪水
me_salary.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[5]/dd[1]/text()')[0])
# 女生家乡
me_location.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[8]/dd[1]/text()')[0])
# 女生婚姻
me_marriage.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[6]/dd[1]/text()')[0])
# 女生购房
me_home.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[7]/dd[1]/text()')[0])
# 女生介绍
me_introduce.append(tree.xpath('//*[@id="profileCommon"]/div[1]/div[2]/div[1]/text()')[0])
# 择偶年龄
he_age.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[2]/dd[3]/text()')[0])
# 择偶身高
he_height.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[3]/dd[3]/text()')[0])
# 择偶教育
he_education.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[4]/dd[3]/text()')[0])
# 择偶薪水
he_salary.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[5]/dd[3]/text()')[0])
# 择偶家乡
he_location.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[8]/dd[3]/text()')[0])
# 择偶婚姻
he_marriage.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[6]/dd[3]/text()')[0])
# 择偶购房
he_home.append(tree.xpath('//*[@id="matching_detail"]/div/div/dl[7]/dd[3]/text()')[0])
他来了,他来了
因为部分数据涉及隐私,所以我没有对对应的UID进行爬取。
这边没有进行模拟登陆,而是直接携带Cookie
本来想爬取个至少1万条数据,后来因为一个异常,中断在了不到3000条,时间关系,我没有继续处理
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KBrBCzYL-1594628689475)(C:\Users\yujiaqi\Desktop\爬取百合\pic\excel.png)]](http://img.e-com-net.com/image/info8/b00115e517d946fbbf637487319a75e2.jpg)
- 我想静静~
3、数据清洗
这边还是有很多需要处理的数据,我就展示一部分吧
3.1、导入相关模块
import pandas as pd
import numpy as np
import re
import jieba
df = pd.read_csv("sample.csv",encoding="gbk",header=None)
df.head()
3.2、设置行列索引
# 指定行索引
df.index = range(len(df))
# 指定列索引
df.columns = ['年龄', '身高', '学历', '工资', '家乡', '婚姻', '住房', '自我介绍', '对象年龄', '对象身高', '对象学历', '对象薪水', '对象家乡', '对象婚姻', '对象住房']
df.head()
3.3、查看是否有空值
df.isnull().any(axis = 0)
- 这边很奇怪,显示木有,但我后续处理的时候出现了很多
3.4、去重
print('去重前数据量:', df.shape)
# 去重
df.drop_duplicates(inplace=True)
print('去重后数据量:', df.shape)
3.5、把年龄中的岁去掉
df['年龄'] = df['年龄'].str[0:2]
df.head()
3.6、分离最低最高工资
# 对工资进行处理
def get_salary_max_min(salary):
try:
result = re.split('-', salary)
return result
except:
return salary
salary = df['工资'].apply(get_salary_max_min)
df['最低工资'] = salary.str[0]
df['最高工资'] = salary.str[1]
3.6.1、把工资中含有中文及特殊字符的去掉
indexs = df[df['最低工资'] == '2000以下'].index
df.loc[indexs, '最低工资'] = '2000'
df.loc[indexs, '最高工资'] = '2000'
df.head()
3.6.2、把工资类型转化为数字类型
df['最高工资'] = pd.to_numeric(df['最高工资'])
df['最低工资'] = pd.to_numeric(df['最低工资'])
df.info()
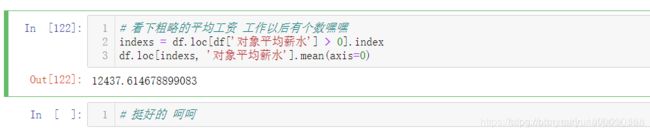
3.6.3、求平均工资
df['平均工资'] = df[['最低工资', '最高工资']].mean(axis=1)
3.7、保存处理后的文件
feature = ['年龄', '身高', '学历', '工资', '家乡', '婚姻', '住房', '自我介绍', '对象年龄', '对象身高',
'对象学历', '对象薪水', '对象家乡', '对象婚姻', '对象住房', '最低工资', '最高工资', '平均工资',
'对象最低年龄', '对象最高年龄', '对象平均年龄', '对象最低身高', '对象最高身高', '对象平均身高', '对象最低薪水',
'对象最高薪水', '对象平均薪水']
final_df = df[feature]
final_df.to_excel(r"可视化.xlsx",encoding="gbk",index=None)
3.8、展示下哈哈哈
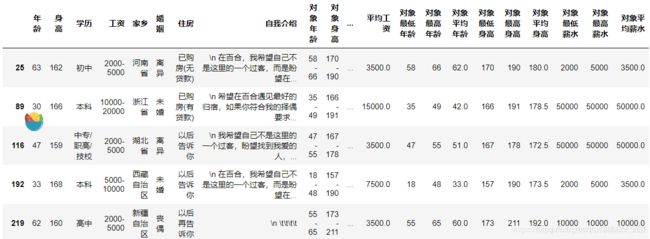
4、数据可视化
数据可视化这一部分我是最陌生的,所以很多样式都和杰哥(开头提到CSDN推荐文章的作者)类似的,学着学着对echarts有了些了解,认识到了pyecharts更是非常强大。
这里我将放出部分数据可视化源码。
4.1、读取下清洗好的文件
import pandas as pd
df = pd.read_excel("可视化.xlsx",encoding="gbk")
df.head()
4.2、18-37岁女性求伴数量分析
import pyecharts.options as opts
from pyecharts import options
from pyecharts.charts import Bar
name = sort_age.index.tolist()
value = sort_age.values.tolist()
bar3 = (
Bar(init_opts=opts.InitOpts(width='1000px', height='420px')).add_xaxis(xaxis_data=name)
.add_yaxis(series_name='18-37岁单身女性数量分析', y_axis=value)
.set_global_opts(title_opts=opts.TitleOpts(title="可切换查看曲线图"),
legend_opts=opts.LegendOpts(is_show=True))
)
bar3.set_global_opts(toolbox_opts=opts.ToolboxOpts(is_show=True))
bar3.render_notebook()
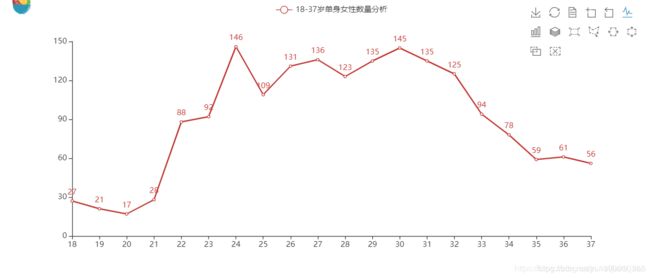
似乎明白了点什么?
4.3、最被女生喜欢的男生平均升高TOP10
import pyecharts.options as opts
from pyecharts import options
from pyecharts.charts import Line
line_man1 = (
Bar(init_opts=opts.InitOpts(width='750px', height='350px'))
.add_xaxis(xaxis_data=name)
.add_yaxis(series_name='对象男性身高均值Top10(样本整体均值:178cm)', y_axis=value)
# 下面两行代码,用于旋转坐标轴
.reversal_axis()
.set_series_opts(label_opts=opts.LabelOpts(position="right"))
)
# line_man1.set_global_opts(toolbox_opts=opts.ToolboxOpts(is_show=True))
line_man1.render_notebook()
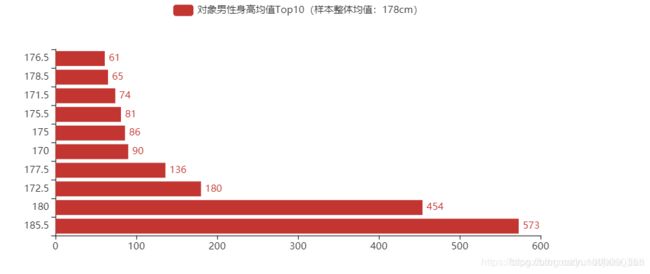
我哭了,我连平均值都没达到,呜呜呜
4.4、女生对另一半男生薪资平均要求
from pyecharts.charts import Pie
import pyecharts.options as opts
num = avg_salary.values.tolist()
lab = avg_salary.index.tolist()
x = [(i, j)for i, j in zip(lab, num)]
pie = (Pie(init_opts=opts.InitOpts(width='750px', height='350px'))
.add(series_name='目标对象男性平均工资粗略分布(样本均值:12437)',data_pair=[(i, j)for i, j in zip(lab, num)],radius = ['40%','75%'])
.set_global_opts(title_opts=opts.TitleOpts(title="全样本均值:12437元"),
legend_opts=opts.LegendOpts(is_show=True))
)
pie.render_notebook()
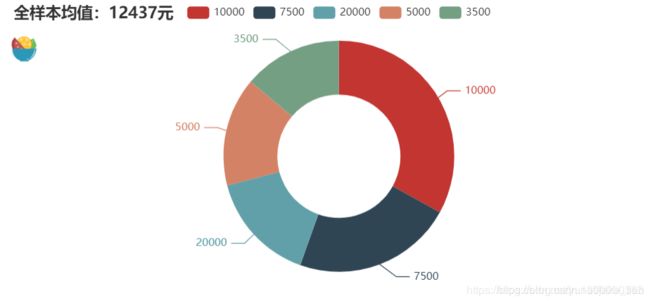
平均值月薪12437元,小伙伴你达到平均值了吗?
4.5、词云
这个词云不是很准,很多语句都是官方默认的,大家看看就好。

5、总结
-
还是挺感谢杰哥以及CSDN的,有着他们的指引,我才完成了此次爬取+数据分析的整个过程。
-
学习到了蛮多的,在三天时间里,更进一步理解了些反爬机制,对于数据清洗也能进一步运用在实战上,对于pycharts,一个全新的知识,也是GET到了不少。
-
我把全部的源码开放在了Github上,里面有这详细的注释,如果对你学习有帮助,记得点赞 + star~
https://github.com/ujiaqi/crawler-baihe
- 如果遇到疑问可以留言,喜欢与Learner交流。
最后,祝单身的你早日脱单,遇见更好的她,留住更好的自己!
推荐阅读:
- 我精心整理的 136 页 Excel 数据透视表 PDF 文件!【附获取方式】
- 100天从 Python 小白到大神的学习资源,都在这了。
- 不吹不黑!GitHub 上帮助人们学习编码的 12 个资源,错过血亏…
- 我花了五个小时的时间,将全部文章详细整理出来了,千万不要错过!
关注微信公众号『杰哥的IT之旅』,后台回复“1024”查看更多内容,回复“微信”添加我微信。
