推荐系统学习笔记之三——(基于邻域的)协同过滤算法的公式化、标准化
教材:《推荐系统 技术、评估及高效算法》
目录:基于用户的评分预测
--公式
--例题
--基于用户的分类预测方法
基于物品的推荐
--公式
--例题
基于用户的CF和基于物品的CF比较
评分标准化
符号化、公式化是现实中实际问题通往计算机不可缺少的一道桥梁,对于认知已久的协同过滤,我们如何用公式来表示,又如何对一个实际问题进行计算,这是本小节关注的问题。
基于用户的评分预测
公式
预测用户 对新物品
对新物品 的评分
的评分![]() ,是利用和用户u兴趣相近却对物品i做了评分的用户,这些用户称为近邻用户或相似用户。
,是利用和用户u兴趣相近却对物品i做了评分的用户,这些用户称为近邻用户或相似用户。
那么显然,我们的算法的答题步骤应该分为如下两步:找到所有用户中与用户u相似的用户,然后使用这些近邻用户对物品i 的评分求平均或者加权平均,得到预测值![]() 。
。
第一步找近邻用户需要计算用户与用户之间的相似度,因为计算相似度的方法并不单一,所以这一部分内容在下一节统一叙述。
第二步,就是我们现在要关注的符号了。设![]() 为用户u的近邻用户集合,其集合内数量k在第一步时我们自己决定,此时能得到预测用户对新物品的评分
为用户u的近邻用户集合,其集合内数量k在第一步时我们自己决定,此时能得到预测用户对新物品的评分![]() :
:
 ,换成语言描述,就是将
,换成语言描述,就是将![]() 内的所有用户对物品i的评分取平均。
内的所有用户对物品i的评分取平均。
但是此时有一个小问题,近邻用户中所有人与用户u相似度都是一样的吗?一般都不一样。
加权平均就派上用场了,用![]() 代表和
代表和 之间的相似度权重,公式改良如下(有分母的原因是因为这些权重的和不一定为1,所以加之以标准化。)
之间的相似度权重,公式改良如下(有分母的原因是因为这些权重的和不一定为1,所以加之以标准化。)

例题
下面用一道书中提供的小例题,加深印象。
假设我们使用上式来预测Eric对《Titanic》的评分,这里会用到Lucy和Diane这两个近邻用户对这部电影的评分。进一步我们假设这些近邻与Eric相似权重分别是0.75和0.15。那么这个预测评分为……

![]()
基于用户的分类预测方法
经过前面一轮计算,我们发现其计算的本质是回归问题(求平均嘛……),那么分类问题也应该是有的(比如评分不存在小数,只有好、不好的二元评分)
对于分类问题,方案离不开最基础的投票法、加权投票法。使用![]() 来表示近邻用户中评分为 r 的个数。
来表示近邻用户中评分为 r 的个数。
![]() , 其中,
, 其中,![]() 代表中间相等为1,否则为0.
代表中间相等为1,否则为0.
那么最终的投票结果,也就是预测结果就可以用如下公式来表示:
![]()
基于物品的推荐
基于物品的推荐形式上与基于用户的推荐没有太大区别,步骤:找到与预测物品i相似的近邻物品,然后求用户u对这些近邻物品的平均评分。
将基于用户的几个公式依次改为基于物品的:

 ,
,
![]()
基于用户的CF和基于物品的CF比较
虽然这两种方法在公式上看起来没有太大的差别,但是放在业务中,却有着不小的差异。
user_base CF(基于用户的CF)相较而言,惊喜度比较高,可能推荐到当前用户从未体验过的类型。
除此之外,user_base CF和item_base CF的选择应该基于实际业务的准确性以及稳定性。
如:系统中有1000个用户,物品则是100个,即物品数远小于用户数,这时候应该选择item_base CF,反之亦然。
系统中的物品流动比较大,比如新闻类资讯的推荐,基于物品就可能不太靠谱,过一天的新闻就已经毫无价值了。
评分标准化
在基于邻域的CF算法中,还有三个非常重要的因素需要考虑,1)之前提到过的相似度的计算,2)近邻k的选择,3)评分的标准化。
本小节只考虑第三点,什么是评分的标准化?
每个人都是有着自己行为准则的个体,这种行为准则放在社会中就是个性,而我们需要给某个人预测评分或推荐的时候就需要知道这个人个性、同时在数据抹平其他人的个性。
举个栗子:有些人要求比较高,几乎所有物品评分都不超过3分。而有些人要求比较低,觉得还可以都给了5分,而实际上,抛出这个个人要求的标准,这两种人对这个物品的兴趣度或评价是一样的。
标准化要做的,就是将这种行为准则不一的人拉回同一条线上来。
a、均值中心化
(1)、对于user-base CF,可以通过减去他评价的物品集 ![]() 的平均评分
的平均评分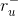 来标准化(均值标准化):
来标准化(均值标准化):

(2)、同样,对于item-base CF,有:

item-base CF 与user-base CF相比理解上有些绕,我是这样理解的:大家对物品 i 的平均评分加上 (我对其他物品的评分)与(大家对其他物品的评分)的偏差。
b、Z-score标准化
均值中心化考虑了个人行为准则的偏差(即个人评分均值),但是并没有考虑到个人评分范围的影响(即个人评分方差,如很情绪化的小红,有一点瑕疵就直接0分,没有瑕疵就直接5分,而沉稳的小明的分数往往在3-4之间徘徊)。
Z-score标准化通过在均值中心化的基础上除以评分标准差来去除这种方差的影响。
(1)、基于用户:
 ,其中
,其中![]() 代表用户v对物品评分标准差。
代表用户v对物品评分标准差。
(2)、基于物品:
 ,其中
,其中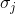 代表大家对物品j的评分的标准差。
代表大家对物品j的评分的标准差。
本小节内容到此为止,下一小节继续 相似度的计算以及权重的重要性。