CGAN论文解读:Conditional Generative Adversarial Nets
论文链接:Conditional Generative Adversarial Nets
代码解读:Keras-CGAN_MNIST 代码解读
目录
一、前言
二、相关工作
三、网络结构 CGAN NETS
四、实验结果
4.1 单模态 (mnist实验)
4.2 多模态(自动为图片打标签)
五、 Future work
六、小结
一、前言
摘要:

本文做的工作:介绍了GAN 的条件版本-条件GAN。通过简单地为数据增加label y进行构造,G和D 的输入都加上了label。本文做了两个基于条件GAN 的实验:1.根据类标签生成数字,(以类标签作为条件)使用MNIST手写数字体数据集。2.我们还演示了如何使用该模型来学习一个多模态模型,并提供了一个应用于图像标记的初步示例,我们在其中演示了该方法如何生成不属于训练标签的描述性标记。(利用CGAN自动为图像打标签)
前言:简单的介绍GAN的优势;传统的Unconditioned GAN不能控制生成器生成数据的模式(mode),为模型加上额外的信息作为条件,可以引导数据生成过程。条件信息可以基于图像修补的部分,或者数据的多模态信息。CGAN可以应用于图像修补,多模态深度学习。
Notes: 多模态深度学习是深度学习中的一类特殊问题.,多模态是在输入的类型上有了改变,指多个类型的输入。例如: 通过红外,图像,声波等多种形态的输入,来预测场景中是否有人存在,或者做多类型的标注问题。多模态信息融合可以用到目标检测上。
二、相关工作
图像标记的多模式学习的两个挑战及可能的解决方法:
- 庞大的预测输出类别
- 大部分工作集中在输入输出一对一映射(但实际中,存在一对多的映射。比如一张图片由于不同人来标记有不同的注释但是描述的都是同一张图片。)
解决方法:
- One way to help address the first issue is to leverage additional information from other modalities。帮助解决第一个问题的方法之一是利用来自其他模式的额外信息。
- One way to address the second problem is to use a conditional probabilistic generative model, theinput is taken to be the conditioning variable and the one-to-many mapping is instantiated as a conditional predictive distribution.解决第二个问题的一种方法是使用条件概率生成模型,将输入作为条件变量,将一对多映射实例化为条件预测分布。(在后面CGAN的loss函数上可以体现出来。)
作者展示了如何训练一个监督的多模态神经语言模型,并且他们能够为图像生成描述性语句。(是第二个实验的前提。)
三、网络结构 CGAN NETS
传统GAN 的优化目标:
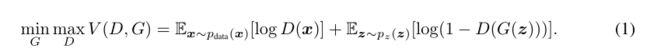
下图是一个简单的CGAN结构:
如果生成器G和鉴别器D都以一些额外的信息y为条件,则生成对抗网络可以扩展到条件模型。y可以是任何类型的辅助信息,例如类标签或来自其他模式的数据。我们可以通过输入y到鉴别器和发生器作为额外的输入层来实现条件设置。在生成器中,先前的输入噪声p(z)和y被组合在联合隐藏表示中。在鉴别器D中,x和y组合在一起作为输入,送到判别函数(图中是MLP模型)。
CGAN的优化目标:
![]()
四、实验结果
4.1 单模态 (mnist实验)
以mnist数据集的lable(0-9)作为条件信息,编码为one-hot向量(独热码)。
G网里,噪声z和label y分别被映射到大小分别为200,1000的隐藏层,激活函数都是Relu。再用大小为1200的隐藏层(combined hidden ReLu layer)拼接这两个层的输出,再接着进行生成784(28*28)图片的过程。
D网也顺从这个思路,结合(combine)img和label,一起判断打分,判断真假,最后一层是sigmoid。
生成图片的效果如下:

在本文开头的链接:代码解读中,G combine z和y,D combine img 和 y的方法与此论文有所不同,更简洁,而且效果也不错。可以尝试一下。
4.2 多模态(自动为图片打标签)
In this section we demonstrate automated tagging of images, with multi-label predictions, using conditional adversarial nets to generate a (possibly multi-modal) distribution of tag-vectors conditional on image features.
在本节中,我们将演示使用多标签预测来自动标记图像,并使用条件对抗网生成基于图像特征的标记向量(可能是多模式的)分布。
首先是数据集的特殊性。像Flickr这样的照片网站是一个丰富的标记数据源,其形式是图像及其相关的用户生成元数据(UGM user-generated metadata ),特别是用户标记。这些标记在语义上更接近人们对图片的描述,而不是简单地进行目标识别。UGM 的另一个特殊之处是近义词,不同人对同一个图片有着不同的描述,但描述的都是同一个对象。因此用一个有效的方法来规范化这些标签变得很重要。概念词嵌入(Conceptual word embeddings)在这里非常有用,因为相关的概念词最终由相似的向量表示。
这个模型的训练分为以下几个步骤:
- pre-train two model to extract image and tag features
- use MIR Flicker 25,000 dataset, use pre-trained models to extract features.

首先分别用两个数据集(ImageNet,YFCC100M)提前训练两个模型,提取图像和tag(词向量)的特征,以便于在GAN中结合(combine)两者特征进行训练。
然后我们用训练好的两个模型来提取 MIR Flickr 25,000 dataset的图像和标签特征。在实验中,去掉了没有标签的图像,一个图像有多个标签的(一张图有多个描述词),我们在训练集中重复它,image 和其中一个标签作为训练数据,重复至用上了它的所有标签。
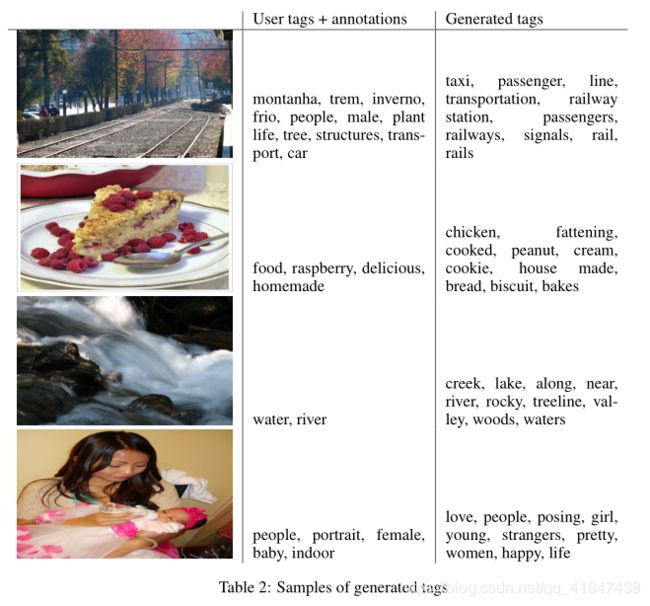
为了进行评估,我们为每幅图像生成100个样本,并使用词汇表中词汇向量表示的余弦相似性来找到最接近的前20个单词。然后我们从100个样本中选出10个最常见的单词。下表显示了用户分配的标记和注释的一些示例,以及生成的标记。
接着简单叙述了D,G的结构。
The best working model’s generator receives Gaussian noise of size 100 as noise prior and maps it to 500 dimension ReLu layer. And maps 4096 dimension image feature vector to 2000 dimension ReLu hidden layer. Both of these layers are mapped to a joint representation of 200 dimension linear layer which would output the generated word vectors.
The discriminator is consisted of 500 and 1200 dimension ReLu hidden layers for word vectors and
image features respectively and maxout layer with 1000 units and 3 pieces as the join layer which is
finally fed to the one single sigmoid unit.
五、 Future work
这篇文章的工作更像是一种准备工作,阐述了CGAN的潜力,和一些应用场景。在将来的探索中,我们希望提出更好的模型。
在当前的实验中,我们只单独使用每个标签。但是如果同时使用多个标签(有效地将生成问题作为“集合生成”问题之一),我们希望获得更好的结果。另一个明显的方向是建立一个共同的训练方案来学习语言模型。以前有工作表明,我们可以学习适合特定任务的语言模型。
六、小结
虽然这是一篇2014年的论文,但可读性很强,在控制生成器生成数据的模式上很有启发。文章简短精炼,实验结果也比较清晰。这之后,还有很多基于CGAN思想的文章和工作,比如自动生成动漫人物图像,并可控制人物特征。