论文阅读——《Conditional Generative Adversarial Nets》
论文阅读之 Conditional Generative Adversarial Nets
Introduction
在上一篇文章中介绍了最简单的GAN模型, GAN模型能够避免很多棘手的概率的估算,能够生成比较真实的图片。而且各种因素和相互作用能够轻易的加入到模型中。这篇文章将介绍CGAN.
我们不能控制非条件的生成模型生成的数据。但是,通过对模型添加条件,就可能可以指导生成过程。这里的添加的条件可以基于类别标签,用于修复的部分数据,甚至是来自不同形式的数据。
在这篇论文中作者展示了如何构建这样的生成对抗网络。
Conditional Adversarial Nets
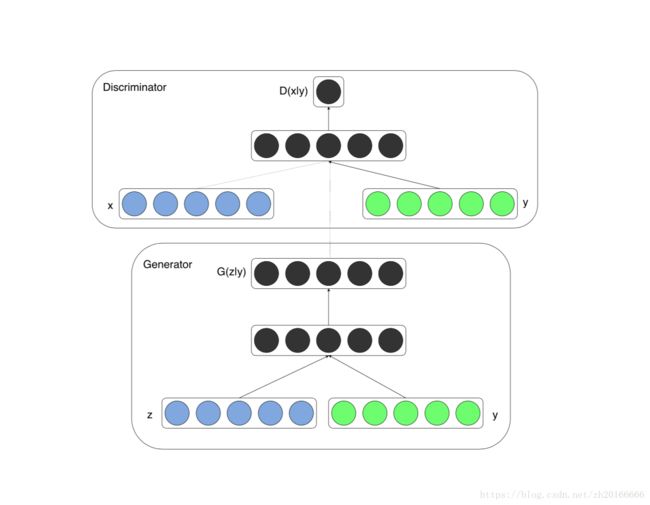
如果在判别器和生成器中都加入一些额外的信息 y y y,GAN模型可以扩展成一个条件模型。 y y y可以是任意的辅助信息,例如类别标签或者来自不同形式的数据。我们可以将 y y y作为额外的输入层送入生成器和判别器来添加条件。
在给定了一定的条件信息的情况下, 模型的目标函数变成了如下形式:
min G max D V ( D , G ) = E x ∼ p d a t a ( x ) [ l o g D ( x ∣ y ) ] + E z ∼ p z ( z ) [ l o g ( 1 − D ( G ( z ∣ y ) ) ) ] \min_G\max_DV(D,G) = \mathbb{E}_{x∼p_{data}(x)}[logD(x|y)]+\mathbb{E}_{z∼p_z(z)}[log(1−D(G(z|y)))] GminDmaxV(D,G)=Ex∼pdata(x)[logD(x∣y)]+Ez∼pz(z)[log(1−D(G(z∣y)))]
CGAN的结构如下:
Experiment
Code
代码参照论文中叙述的结构:
generator:
In the generator net, a noise prior z with dimensionality 100 was drawn from a uniform distribution within the unit hypercube. Both z and y are mapped to hidden layers with Rectified Linear Unit (ReLu) activation, with layer sizes 200 and 1000 respectively, before both being mapped to second, combined hidden ReLu layer of dimensionality 1200. We then have a final sigmoid unit layer as our output for generating the 784-dimensional MNIST samples.
discriminator:
The discriminator maps x to a maxout layer with 240 units and 5 pieces, and y to a maxout layer with 50 units and 5 pieces. Both of the hidden layers mapped to a joint maxout layer with 240 units and 4 pieces before being fed to the sigmoid layer. (The precise architecture of the discriminator is not critical as long as it has sufficient power; we have found that maxout units are typically well suited to the task.)
- Generator
def generator(z, y, training=True):
h1_z = fully_connect(z, 200, name='g_h1_z_fc')
h1_z = tf.nn.relu(tf.layers.batch_normalization(h1_z, training=training, name='g_h1_z_bn'))
h1_y = fully_connect(y, 1000, name='g_h1_y_fc')
h1_y = tf.nn.relu(tf.layers.batch_normalization(h1_y, training=training, name='g_h1_y_bn'))
h1 = tf.concat([h1_z, h1_y], axis=1)
h2 = tf.nn.dropout(h1, keep_prob=0.5)
h2 = fully_connect(h2, 784, name='g_h2_fc')
return tf.nn.sigmoid(h2)
- discriminator
def discriminator(images, y, reuse=False, training=True):
if reuse:
tf.get_variable_scope().reuse_variables()
h1_img = maxout(images, 240, name='d_h1_img_maxout')
h1_y = maxout(y, 50, name='d_h1_y_maxout')
h1 = tf.concat([h1_img, h1_y], axis=1)
h1 = tf.nn.dropout(h1, keep_prob=0.5)
h2 = maxout(h1, 240, name='d_h2_maxout', pieces=4)
h2 = tf.nn.dropout(h2, keep_prob=0.5)
h3 = fully_connect(h2, 1, name='d_h3_fc')
return tf.nn.sigmoid(h3), h3
- maxout layer
def maxout(input, channels_out, name, pieces=5):
channels_in = input.get_shape().as_list()[-1]
with tf.variable_scope(name):
w = weight_variable([channels_in, channels_out, pieces], name='weights')
b = bias_variable([channels_out, pieces], name='bias')
return tf.reduce_max(tf.tensordot(input, w, axes=1) + b, axis=-1)
完整代码
Result
Iter0

Iter1000

Iter10000

Iter45000

Iter49000

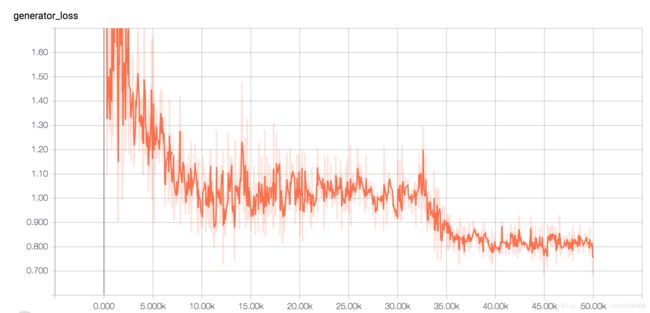
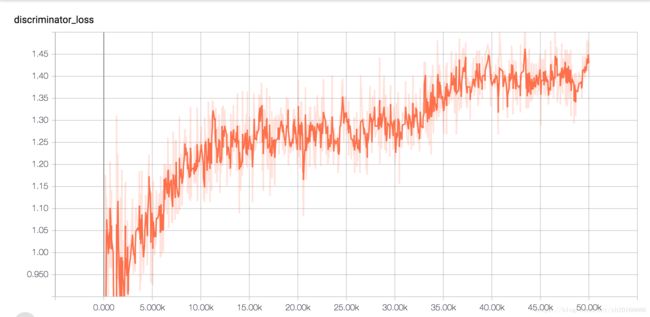
Loss of Generator and Discriminator
Reference
Conditional GAN python 实现