Hadoop和Hbase环境的搭建
起因是测试,使用自己的Hadoop环境下的Hbase的时候,发现hbase不能使用,基于原有环境问题十分复杂的情况下,我对该环境重新进行了部署
要求:三台服务器,分别做zookeeper和Hadoop、hbase
1、需要准备3台linux x64 服务器,一台作为master,2台作为prepare备份机
master 192.168.1.132
prepare1 192.168.1.133
prepare2 192.168.113.134
zookeeper的安装可以参考:ZooKeeper的安装
2、配置所有机器的hostname和hosts
[root@master~]: vim /etc/sysconfig/network
HOSTNAME=master
然后prepare1,prepare2服务器修改为
HOSTNAME=prepare1、HOSTNAME=prepare2 重启后生效
3、修改3台服务器hosts
[root@master~]:vi /etc/hosts
增加如下内容:
192.168.213.132 master
192.168.213.133 prepare1
192.168.213.134 prepare2
在prepare1 ,prepare2 上做相同操作
4、SSH三台机器之间免密码登录
(1)Linux 默认没有开启ssh无密登录,依次编辑每台服务器上 vi /etc/ssh/sshd_config,
去掉以下两行注释,开启Authentication免登陆。
#RSAAuthentication yes 有些系统是没有,需要手动添加
#PubkeyAuthentication yes
如果是root用户下进行操作,
还要去掉 #PermitRootLogin yes注释,允许root用户登录。
分发给两台备份机
scp -r /etc/ssh/sshd_config [email protected]:/etc/ssh/sshd_config
scp -r /etc/ssh/sshd_config [email protected]:/etc/ssh/sshd_config
(2)输入命令,ssh-keygen -t rsa,生成key,一直按回车,
就会在/root/.ssh生成: id_rsa.pub id_rsa 二个文件,
这里要说的是,为了各个机器之间的免登陆,在每一台机器上都要进行此操作。
(3) 接下来,在master服务器,合并公钥到authorized_keys文件,
进入/root/.ssh目录,需要在master主机上输入以下命令
cat id_rsa.pub>> authorized_keys 把master公钥合并到authorized_keys 中
ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
ssh [email protected] cat ~/.ssh/id_rsa.pub>> authorized_keys
以上操作需要输入服务器root密码
把prepare1 、prepare2 公钥合并到master主服务的 authorized_keys 中
完成之后输入命令,把mester 服务器上的authorized_keys文件远程copy到prepare1 和prepare2 之中
scp ~/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
scp ~/.ssh/authorized_keys [email protected]:/root/.ssh/authorized_keys
最好在每台机器上进行chmod 600 authorized_keys操作,使当前用户具有 authorized_keys的读写权限。
拷贝完成后,在每台机器上进行 service sshd restart 操作, 重新启动ssh服务。
之后在每台机器输入 ssh 192.168.213.134/133/132, 或 ssh master/ssh prepare1/ssh prepare2测试能否无需输入密码连接另外两台机器。
5、安装jdk,配置环境变量
jdk可以去网上自行下载,jdk-8u191-linux-x64.tar.gz
环境变量如下:
编辑 vi /etc/profile 文件,添加如下内容:
export JAVA_HOME=/usr/local/java/jdk-8u191(填写自己的jdk安装路径)
export PATH=$PATH:$JAVA_HOME/bin
输入命令,source /etc/profile 使配置生效
分别输入命令,java 、 javac 、 java -version,查看jdk环境变量是否配置成功
分发给两台备份机
scp -r /usr/local/java/jdk-8u191 [email protected]:/usr/local/java/jdk-8u191
scp -r /usr/local/java/jdk-8u191 [email protected]:/usr/local/java/jdk-8u191
6、上传hadoop 安装包解压
修改Hadoop环境变量,HADOOP_HOME、hadoop-env.sh、yarn-env.sh
(1)配置HADOOP_HOME,编辑 vi /etc/profile 文件,添加如下内容:
export HADOOP_HOME=/usr/local/java/hadoop-2.7.3 (Hadoop的安装路径)
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
(2)配置hadoop-env.sh、yarn-env.sh,在Hadoop安装目录下
编辑 vi etc/hadoop/hadoop-env.sh
加入export JAVA_HOME=/usr/local/java/jdk-8u191(jdk安装路径)
编辑 vim etc/hadoop/yarn-env.sh
加入export JAVA_HOME=/usr/local/java/jdk-8u191(jdk安装路径)
保存退出
配置core-site.xml、hdfs-site.xml、mapred-site.xml、mapred-site.xml
修改core-site.xml,在Hadoop安装目录下 编辑 vi etc/hadoop/core-site.xml
修改hdfs-site.xml,在Hadoop安装目录下 编辑 vi etc/hadoop/hdfs-site.xml
修改mapred-site.xml,在Hadoop安装目录下 编辑 vi etc/hadoop/mapred-site.xml
修改yarn-site.xml,在Hadoop安装目录下 编辑 vi etc/hadoop/yarn-site.xml
7、配置slaves文件
在Hadoop安装目录下,编辑vim etc/hadoop/slaves,
删除默认的localhost,加入prepare1 、prepare2,保存退出。
8、通过远程复制命令scp,mester将服务配置好的Hadoop复制到prepare1 、prepare2对应位置
scp -r /usr/local/java/hadoop-2.7.3 [email protected]:/usr/local/java/hadoop-2.7.3
scp -r /usr/local/java/hadoop-2.7.3 [email protected]:/usr/local/java/hadoop-2.7.3
9、Hadoop的启动与停止
1、在Master服务器启动hadoop,从节点会自动启动,进入Hadoop目录下,
输入命令,bin/hdfs namenode -format进行hdfs格式化
输入命令,sbin/start-all.sh,进行启动
也可以分开启动,sbin/start-dfs.sh、sbin/start-yarn.sh
在master 上输入命令:jps, 看到ResourceManager、
NameNode、SecondaryNameNode进程
在prepare1 ,prepare12上输入命令:jps, 看到DataNode、NodeManager进程
出现这5个进程就表示Hadoop启动成功。
在浏览器中输入http://192.168.213.132:50070查看master状态(需先停止防火墙),
输入http://http://192.168.213.132:8088查看集群状态
2、停止hadoop,进入Hadoop目录下,输入命令:sbin/stop-all.sh,
即可停止master和prepare集群的Hadoop进程
10、Hbase安装部署
首先下载hbase
http://archive.apache.org/dist/hbase/1.2.6/hbase-1.2.6-bin.tar.gz
[root@master~]:tar –zxvf hbase-1.2.6-bin.tar.gz
1、在Hadoop配置的基础上,配置环境变量HBASE_HOME、hbase-env.sh
编辑 vim /etc/profile 加入
export HBASE_HOME=/usr/local/java/hbase-1.2.6
export PATH=$HBASE_HOME/bin:$PATH
编辑vi /usr/local/java/hbase-1.2.6/conf/hbase-env.sh 加入
export JAVA_HOME=/usr/local/java/jdk1.8.0_191/(jdk安装路径)
去掉注释 # export HBASE_MANAGES_ZK=true,使用hbase自带zookeeper。
2、配置hbase-site.xml文件
3、修改regionservers
编辑 vi /usr/local/java/hbase-1.2.6/conf/regionservers 删除默认的localhost,
加入prepare1、prepare2,保存退出
然后把在master上配置好的hbase,分发到两台备份机上
scp /usr/local/java/hbase-1.2.6 [email protected]:/usr/local/java/hbase-1.2.6
scp /usr/local/java/hbase-1.2.6 [email protected]:/usr/local/java/hbase-1.2.6
4、启动与停止Hbase
1、在Hadoop已经启动成功的基础上,输入start-hbase.sh,过几秒钟便启动完成,
输入jps命令查看进程是否启动成功,若 master上出现HMaster、HQuormPeer,
prepare1上出现HRegionServer、HQuorumPeer,就是启动成功了。
2、输入hbase shell 命令 进入hbase命令模式
输入命令进入 ./hbase shell
,我实际运行的时候
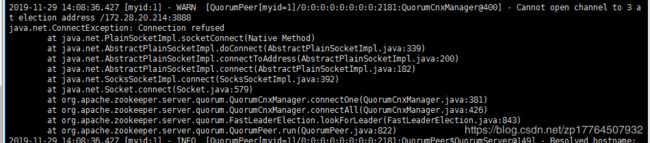
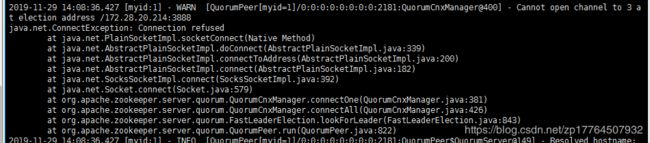
可以判断是zookeeper模块出现了问题,这个时候就要去查zookeeper的问题,发现是slave模块的zk未启动,于是分别去两台服务器的zookeeper的bin目录下,去启动zkserver.sh

具体查看zk的状态,可以通过,zkServer.sh start

完全启动后,就可以建表了