python爬虫练习--爬上海法院开庭公告信息
本次练习的对象是上海法院开庭公告信息。数据来源如下:
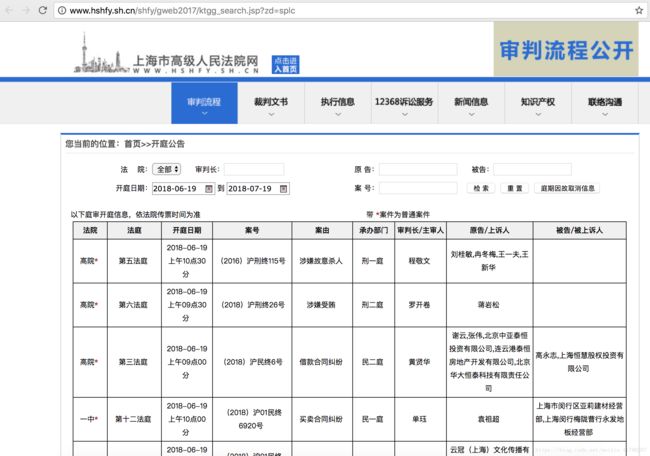
该网站是上海法院的官方网站,网站内会公示未来已确定的开庭信息。

如上图所示,网站显示共有数据30528条。这些数据就是本次爬虫的目标。
(一)分析页面
1. 打开google浏览器开发者工具,点击页面下一页,观察网络请求可以发现,目标数据是这个请求返回的:

2. 下一步,观察上面这个请求的具体内容:
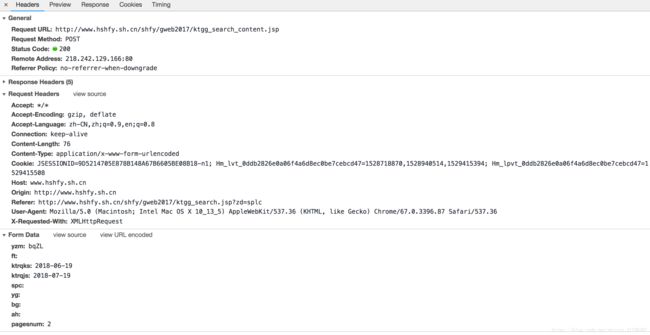
观察得出以下结论,这是一个post请求,具体参数含义为:
yzm 暂时不清楚来源
ktrqks: 2018-06-19 这是查询的起始时间,也就是当天
ktrqjs: 2018-07-19 这是查询的结束时间
pagesnum:2 猜测可知,这是页面所在页数
3. 寻找参数yzm的来源
在网页源代码中搜索,可以看到,yzm的值是写死到js里面的。
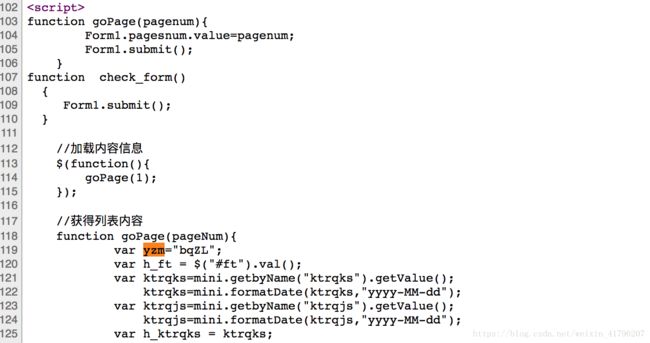
此时,还需要确定,该参数的值是固定的,还是会变化。
多次刷新页面可知,该参数值每次都不一样。
4. 至此,页面基本分析完毕。只需要首先请求页面拿到参数yzm的值,然后构造post参数,不断翻页请求数据即可。
(二)核心代码实现
import requests
from requests.exceptions import RequestException
from pyquery import PyQuery as pq
from lxml.etree import XMLSyntaxError
import re
import csv
from concurrent.futures import ThreadPoolExecutor1. 获取参数yzm的部分
s = requests.Session()
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36",
"Referer": "http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search.jsp?zd=splc",
"Upgrade-Insecure-Requests":"1",
"Connection":"keep-alive",
"Host":"www.hshfy.sh.cn"
}
def get_yzm_html():
url = "http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search.jsp?zd=splc"
r = s.get(url, headers=headers)
return r.text
def find_yzm(html):
try:
if re.findall(r'(?:var yzm=")(\w+)(?:";)', html):
return re.findall(r'(?:var yzm=")(\w+)(?:";)', html)[0]
except XMLSyntaxError:
return None2. 获取目标数据的部分
def get_data_html(yzm, num):
form_data = {
"yzm": yzm,
"ft":"",
"ktrqks": "2018-06-19",
"ktrqjs": "2020-07-11",
"spc":"",
"yg":"",
"bg":"",
"ah":"",
"pagesnum": str(num)
}
url = "http://www.hshfy.sh.cn/shfy/gweb2017/ktgg_search_content.jsp"
try:
response = s.post(url, headers=headers, json=form_data)
if response.status_code == 200:
parse_data(response.text)
print("解析第{}页".format(num))
return None
except RequestException:
print("请求发生错误:", url)
return None3. 解析目标数据的部分
def parse_data(html):
try:
doc = pq(html)
for i in range(2, 17):
row = []
for j in range(1, 10):
td = doc("#report > tbody > tr:nth-child("+str(i)+") > td:nth-child("+str(j)+")")
if td:
row.append(td.text().strip(" *\n"))
return row
except:
print("解析页面发送错误")
return None(三) 结果展示
本次练习共拿到2万多条数据,可是页面显示数据有30528条。经多方推测,应该是页面显示数据量有误。
