第1131期AI100_机器学习日报(2017-10-23)
AI100_机器学习日报 2017-10-23
- 从CNN视角看在自然语言处理上的应用
- GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用
- 谷歌发布电影动作数据集AVA,57600精准标注视频教AI识别人类行为
- 浅谈深度学习中的代码效率问题
- 深度学习文档分类最佳实践
@好东西传送门 出品,由@AI100运营, 过往目录 见http://geek.ai100.com.cn
订阅:关注微信公众号 AI100(ID:rgznai100,扫二维码),回复“机器学习日报”,加你进日报群

本期话题有:
全部20 深度学习13 算法12 视觉9 自然语言处理8 资源7 应用6 公告板5 会议活动5 入门4
用日报搜索找到以前分享的内容: http://ml.memect.com/search/
今日焦点 (5)
 爱可可-爱生活 网页版 2017-10-23 10:00
爱可可-爱生活 网页版 2017-10-23 10:00
深度学习 资源 自然语言处理 卞书青 书籍
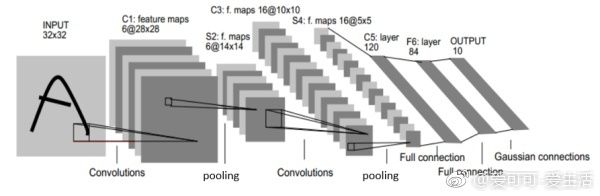
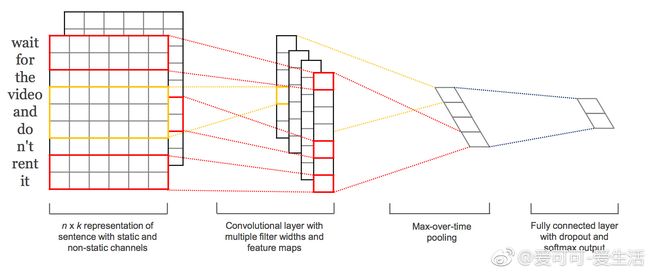
《从CNN视角看在自然语言处理上的应用》by 卞书青 http://t.cn/RWqrk0z
wx:专知内容组 网页版 2017-10-24 06:44
会议活动 经验总结 入门 视觉 算法 应用 资源 Chen Chen CVPR Elon Must Gan Slide Ian Goodfellow ICCV NIPS Sam Altman 博客 分类 广告系统 行业动态 幻灯片 会议 课程 论文 语言学
「【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用」【导读】当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开幕。Google Brain 研究科学家 Ian Goodfellow 在会上作为主题为《生成对抗网络(Generative Adversarial Networks)》的Tutorial 最新演讲, 介绍了GAN的原理和最新的应用。为此,专知内容组整理了的Goodfellow的slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新ICCV 2017 GAN slide。GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial Networks),这几年,他每到大会就会讲 GAN,毕竟对抗生成网络之父的头衔在呢,这块也是这几年机器学习、计算机视觉等方向的研究热点之一。Ian Goodfellow 是世界上最重要的 AI 研究者之一,他在 OpenAI(谷歌大脑的竞争对手,由 Elon Must 和 Sam Altman 创立)工作过不长的一段时间,今年3月重返 Google Brain, 加入Google Brain,其正在建立了一个探索“生成模型”(generative models)的新研究团队。生成模型的概念大家应该都很熟悉,大概有两种玩法:· 密度(概率)估计:就是说在不了解事件概率分布的情况下,先假设随机分布,然后通过数据观测来确定真正的概率密度是怎样的。· 样本生成:这个就更好理解了,就是手上有一把训练样本数据,通过训练后的模型来生成类似的「样本」。在生成模型这一过程中,首先需要提到概率领域一个方法:最大似然估计,现实生活中,我们可能并不知道每个 P(概率分布模型)到底是什么,我们已知的是我们可以观测到的源数据。所以,最大似然估计就是这种给定了观察数据以评估模型参数(也就是估计出分布模型应该是怎样的)的方法。我们在理解生成对抗模型(GAN),首先要知道生成对抗模型拆开来是两个东西:一个是判别模型,一个是生成模型。就需要提及Ian Goodfellow在2014发表的文章。文章标题:Generative Adversarial Networks。文章链接: https://arxiv.org/abs/1406.2661。具体如下:简单打个比方就是:两个人比赛,看是 A 的矛厉害,还是 B 的盾厉害。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。A 拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。B 则拼命地想把真实数据和假数据区分开。这里,A 就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 B。而 B 则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出 A 的骗人技巧。如此这般,随着 B 的鉴别技巧的越来越牛,A 的骗人技巧也是越来越纯熟。一个造假一流的 A,就是我们想要的生成模型!我们现在能使用GANs做什么,这几年各种围绕关于GANs的研究应用很多很多。· 学习训练数据的分布;· 在更多的情况是,我们会面临缺乏数据的情况,我们可以通过生成模型来补足。比如,用在半监督学习中;· 多标签预测(同时完成real/fake, 样本类别等的预测);· 根据环境需要生成相应数据(比如,看到一个美女的背影,猜她正面是否会让你失望……)· 可以模拟预测未来数据(用于具有时序关系的图像)· 解决模型推断问题· 学习不错的embedding(特征表示)信息以保密为文化传统的苹果一贯不喜欢对外公布自己的研究成果。但2016年在机器学习的顶级大会NIPS上,苹果AI团队的负责人RussSalakhutdinov宣布,公司已经允许自己的AI研发人员对外公布论文成果。这则消息刚刚宣布没多久,苹果就发表了自己的第一篇论文,题目叫做《通过对抗训练从模拟与无监督图像中学习》,论文描述了如何利用计算机生成的图像而不是真实图像改进算法识别图像能力的训练。此举一方面可以提高苹果在AI界的存在感,同时如果其研究成果出色的话,也能在学术界赢得同行认可,并吸引到AI方面的人才。苹果第一篇AI论文一经投放,便在2017年7月22日,斩获CVPR 2017最佳论文。谷歌新论文使用生成对抗网络的无监督像素级域适应, 发表在CVPR 2017Unsupervised Pixel-Level Domain Adaptation WithGenerative Adversarial Networks对于许多任务而言,收集标注良好的数据集去训练现代的机器学习算法是极其昂贵的。渲染合成数据倒是一个吸引人的选择,本文的方法能以无监督的方式学习一个像素空间中从一个域到另一个域的变换。基于生成对抗网络(GAN)的方法能够使源域(source-domain)图像看起来就像是来自目标域(target domain)的一样。这个模型不仅能生成看似可信的样本,而且表现还极大超越了许多当前最佳的无监督域适应情况。开始介绍面临缺乏数据的情况,我们可以通过生成模型来补足。内容识别填充(: Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。在这篇博客中,我会介绍 RaymondYeh 和 Chen Chen 等人的一篇论文,“基于感知和语境损失的图像语义修补(Semantic Image Inpainting with Perceptual and ContextualLosses)”。论文在2016年7月26号发布于 arXiv 上,介绍了如何使用 DCGAN 网络来进行图像补全。体验一下半监督学习。将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类别标签。我们在一个数据集上训练一个产生式模型 G 以及 一个判别器 D,输入是N类当中的一个。在训练的时候,D被用于预测输入是属于 N+1的哪一个,这个+1是对应了G的输出。这种方法可以用于创造更加有效的分类器,并且可以比普通的GAN 产生更加高质量的样本。文章标题:Semi-Supervised Learning with Generative Adversarial Networks;文章链接: https://arxiv.org/abs/1606.01583。文章标题:Improved Techniques for Training GANs文章链接: https://arxiv.org/abs/1606.03498开始介绍多标签预测(同时完成real/fake, 样本类别等的预测); 转自:专知 完整内容请点击“阅读原文” via: http://mp.weixin.qq.com/s?__biz=MzA4NDEyMzc2Mw==&mid=2649678266&idx=3&sn=b0a9752921c710ce52c46d10bc6e62b9&scene=0#wechat_redirect
会议活动 经验总结 入门 视觉 算法 应用 资源 Chen Chen CVPR Elon Must Gan Slide Ian Goodfellow ICCV NIPS Sam Altman 博客 分类 广告系统 行业动态 幻灯片 会议 课程 论文 语言学
「【干货】Google GAN之父Ian Goodfellow ICCV2017演讲:解读生成对抗网络的原理与应用」【导读】当地时间 10月 22 日到10月29日,两年一度的计算机视觉国际顶级会议 International Conference on Computer Vision(ICCV 2017)在意大利威尼斯开幕。Google Brain 研究科学家 Ian Goodfellow 在会上作为主题为《生成对抗网络(Generative Adversarial Networks)》的Tutorial 最新演讲, 介绍了GAN的原理和最新的应用。为此,专知内容组整理了的Goodfellow的slides,进行了解读,请大家查看,并多交流指正! 此外,请查看本文末尾,可下载最新ICCV 2017 GAN slide。GANs「对抗生成网络之父」Ian Goodfellow 在 ICCV 2017 上的 tutorial 演讲是聊他的代表作生成对抗网络(GAN/Generative Adversarial Networks),这几年,他每到大会就会讲 GAN,毕竟对抗生成网络之父的头衔在呢,这块也是这几年机器学习、计算机视觉等方向的研究热点之一。Ian Goodfellow 是世界上最重要的 AI 研究者之一,他在 OpenAI(谷歌大脑的竞争对手,由 Elon Must 和 Sam Altman 创立)工作过不长的一段时间,今年3月重返 Google Brain, 加入Google Brain,其正在建立了一个探索“生成模型”(generative models)的新研究团队。生成模型的概念大家应该都很熟悉,大概有两种玩法:· 密度(概率)估计:就是说在不了解事件概率分布的情况下,先假设随机分布,然后通过数据观测来确定真正的概率密度是怎样的。· 样本生成:这个就更好理解了,就是手上有一把训练样本数据,通过训练后的模型来生成类似的「样本」。在生成模型这一过程中,首先需要提到概率领域一个方法:最大似然估计,现实生活中,我们可能并不知道每个 P(概率分布模型)到底是什么,我们已知的是我们可以观测到的源数据。所以,最大似然估计就是这种给定了观察数据以评估模型参数(也就是估计出分布模型应该是怎样的)的方法。我们在理解生成对抗模型(GAN),首先要知道生成对抗模型拆开来是两个东西:一个是判别模型,一个是生成模型。就需要提及Ian Goodfellow在2014发表的文章。文章标题:Generative Adversarial Networks。文章链接: https://arxiv.org/abs/1406.2661。具体如下:简单打个比方就是:两个人比赛,看是 A 的矛厉害,还是 B 的盾厉害。比如,我们有一些真实数据,同时也有一把乱七八糟的假数据。A 拼命地把随手拿过来的假数据模仿成真实数据,并揉进真实数据里。B 则拼命地想把真实数据和假数据区分开。这里,A 就是一个生成模型,类似于卖假货的,一个劲儿地学习如何骗过 B。而 B 则是一个判别模型,类似于警察叔叔,一个劲儿地学习如何分辨出 A 的骗人技巧。如此这般,随着 B 的鉴别技巧的越来越牛,A 的骗人技巧也是越来越纯熟。一个造假一流的 A,就是我们想要的生成模型!我们现在能使用GANs做什么,这几年各种围绕关于GANs的研究应用很多很多。· 学习训练数据的分布;· 在更多的情况是,我们会面临缺乏数据的情况,我们可以通过生成模型来补足。比如,用在半监督学习中;· 多标签预测(同时完成real/fake, 样本类别等的预测);· 根据环境需要生成相应数据(比如,看到一个美女的背影,猜她正面是否会让你失望……)· 可以模拟预测未来数据(用于具有时序关系的图像)· 解决模型推断问题· 学习不错的embedding(特征表示)信息以保密为文化传统的苹果一贯不喜欢对外公布自己的研究成果。但2016年在机器学习的顶级大会NIPS上,苹果AI团队的负责人RussSalakhutdinov宣布,公司已经允许自己的AI研发人员对外公布论文成果。这则消息刚刚宣布没多久,苹果就发表了自己的第一篇论文,题目叫做《通过对抗训练从模拟与无监督图像中学习》,论文描述了如何利用计算机生成的图像而不是真实图像改进算法识别图像能力的训练。此举一方面可以提高苹果在AI界的存在感,同时如果其研究成果出色的话,也能在学术界赢得同行认可,并吸引到AI方面的人才。苹果第一篇AI论文一经投放,便在2017年7月22日,斩获CVPR 2017最佳论文。谷歌新论文使用生成对抗网络的无监督像素级域适应, 发表在CVPR 2017Unsupervised Pixel-Level Domain Adaptation WithGenerative Adversarial Networks对于许多任务而言,收集标注良好的数据集去训练现代的机器学习算法是极其昂贵的。渲染合成数据倒是一个吸引人的选择,本文的方法能以无监督的方式学习一个像素空间中从一个域到另一个域的变换。基于生成对抗网络(GAN)的方法能够使源域(source-domain)图像看起来就像是来自目标域(target domain)的一样。这个模型不仅能生成看似可信的样本,而且表现还极大超越了许多当前最佳的无监督域适应情况。开始介绍面临缺乏数据的情况,我们可以通过生成模型来补足。内容识别填充(: Content-aware fill ,是 photoshop 的一个功能)是一个强大的工具,设计师和摄影师可以用它来填充图片中不想要的部分或者缺失的部分。在填充图片的缺失或损坏的部分时,图像补全和修复是两种密切相关的技术。有很多方法可以实现内容识别填充,图像补全和修复。在这篇博客中,我会介绍 RaymondYeh 和 Chen Chen 等人的一篇论文,“基于感知和语境损失的图像语义修补(Semantic Image Inpainting with Perceptual and ContextualLosses)”。论文在2016年7月26号发布于 arXiv 上,介绍了如何使用 DCGAN 网络来进行图像补全。体验一下半监督学习。将产生式对抗网络(GAN)拓展到半监督学习,通过强制判别器来输出类别标签。我们在一个数据集上训练一个产生式模型 G 以及 一个判别器 D,输入是N类当中的一个。在训练的时候,D被用于预测输入是属于 N+1的哪一个,这个+1是对应了G的输出。这种方法可以用于创造更加有效的分类器,并且可以比普通的GAN 产生更加高质量的样本。文章标题:Semi-Supervised Learning with Generative Adversarial Networks;文章链接: https://arxiv.org/abs/1606.01583。文章标题:Improved Techniques for Training GANs文章链接: https://arxiv.org/abs/1606.03498开始介绍多标签预测(同时完成real/fake, 样本类别等的预测); 转自:专知 完整内容请点击“阅读原文” via: http://mp.weixin.qq.com/s?__biz=MzA4NDEyMzc2Mw==&mid=2649678266&idx=3&sn=b0a9752921c710ce52c46d10bc6e62b9&scene=0#wechat_redirect
wx: 网页版 2017-10-23 21:19
公告板 会议活动 深度学习 视觉 算法 语音 Alex Smola Dave Gershgorn Tuomas Sandholm 行业动态 胡郁 会议 活动 贾佳亚 论文 王永东
「谷歌发布电影动作数据集AVA,57600精准标注视频教AI识别人类行为」【AI WORLD 2017世界人工智能大会倒计时 16 天】大会早鸟票已经售罄,现正式进入全额票阶段。还记得去年一票难求的AI WORLD 2016盛况吗?今年,即将于2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们请到CMU教授、冷扑大师发明人Tuomas Sandholm、 百度副总裁王海峰 、微软全球资深副总裁王永东、亚马逊AWS机器学习总监Alex Smola 、科大讯飞执行总裁胡郁,华为消费者事业群总裁邵洋、腾讯优图实验室杰出科学家贾佳亚等国内外人工智能领袖参会并演讲,一起探讨中国与世界AI的最新趋势。点击文末阅读原文,马上参会!抢票链接: http://www.huodongxing.com/event/2405852054900?td=4231978320026大会官网:http://www.aiworld2017.com 新智元编译 来源:qz.com作者:Dave Gershgorn 编译: 马文 【新智元导读】教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,谷歌最新发布一个电影片段数据集AVA,旨在教机器理解人的活动。 该数据集以人类为中心进行标注,包含80类动作的 57600 个视频片段,有助于人类行为识别系统的研究 数据集地址: https://research.google.com/ava/论文:https://arxiv.org/abs/1705.08421 教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,对个人视频搜索和发现、运动分析和手势界面等应用十分重要。尽管在过去的几年里,对图像进行分类和在图像中寻找目标对象方面取得了令人兴奋的突破,但识别人类的动作仍然是一个巨大的挑战。这是因为动作的定义比视频中的对象的定义要差,因此很难构造一个精细标记的动作视频数据集。许多基准数据集,例如 UCF101、activitynet 和DeepMind 的 Kinetics,都是采用图像分类的标记方案,在数据集中为每个视频或视频片段分配一个标签,而没有数据集能用于包含多个可能执行不同动作的人的复杂场景。 谷歌上周发布一个新的电影片段数据集,旨在教机器理解人的活动。这个数据集被称为 AVA(atomic visual action),这些视频对人类来说并不是很特别的东西——仅仅是 YouTube 上人们喝水、做饭等等的3秒钟视频片段。但每段视频都与一个文件捆绑在一起,这个文件勾勒了机器学习算法应该观察的人,描述他们的姿势,以及他们是否正在与另一个人或物进行互动。就像指着一只狗狗给一个小孩看,并教他说“狗!”,这个数据集是这类场景的数字版本。 与其他动作数据集相比,AVA具有以下几个关键特征: 以人类为中心的标注(Person-centric annotation)。每个动作标签都与一个人相关联,而不是与一个视频或视频剪辑关联。因此,我们能够为在同一场景中执行不同动作的多个人分配不同的标签,这是种情况很常见。原子视觉动作(Atomic visual actions)。我们将动作标签限制在一定时间尺度(3秒),动作需要是物理性质的,并且有清晰的视觉信号。真实的视频材料。我们使用不同类型、不同国家的电影作为AVA的数据源,因此,数据中包含了广泛的人类行为。 3秒视频片段示例,每个片段的中间帧都有边界框标注。(为了清晰起见,每个样本只显示一个边界框) 当视频中有多个人时,每个人都有自己的标签。这样,算法就能知道“握手”的动作需要两个人。 AVA 中共同出现频率最高的动作对 这项技术可以帮助谷歌分析 YouTube 上的视频。它可以应用来更好地投放定向广告,或用于内容过滤。作者在相应的研究论文中写道,最终的目标是教计算机社会视觉智能(social visual intelligence),即“理解人类正在做什么,他们下一步将会做什么,以及他们想要达到的目的。” AVA 数据集的动作标签分布(x轴只包括了词汇表中的一部分标签) AVA 数据集包含 57600 个标记好的视频,详细记录了80类动作。简单的动作,例如站立、说话、倾听和走路等在数据集中更有代表性,每个标签都有超过1万个视频片段。研究人员在论文中写道,使用电影中的片段确实会给他们的工作带来一些偏见,因为电影有其“语法”,一些动作被戏剧化了。 “我们并不认为这些数据是完美的。”论文中写道:“但这比使用由用户上传的内容更好,比如动物杂耍视频、DIY教学视频、儿童生日派对之类的视频等等。” 论文引用中试图找到“不同国籍的顶级演员”,但没有详细说明数据集可能会因种族或性别而产生偏见。研究者希望AVA的发布将有助于人类行为识别系统的研究,为基于个人行为层面的精细时空粒度的标签对复杂活动进行建模提供机会。 原文: https://qz.com/1108090/google-is-teaching-its-ai-how-humans-hug-cook-and-fight/【AI WORLD 2017世界人工智能大会倒计时 16 天】点击图片查看嘉宾与日程。大会门票销售火热,抢票链接: http://www.huodongxing.com/event/2405852054900?td=4231978320026【扫一扫或点击阅读原文抢购大会门票】AI WORLD 2017 世界人工智能大会购票二维码: via: http://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2652006567&idx=4&sn=9c10265351d321ccca4a5fbac1708026&scene=0#wechat_redirect
公告板 会议活动 深度学习 视觉 算法 语音 Alex Smola Dave Gershgorn Tuomas Sandholm 行业动态 胡郁 会议 活动 贾佳亚 论文 王永东
「谷歌发布电影动作数据集AVA,57600精准标注视频教AI识别人类行为」【AI WORLD 2017世界人工智能大会倒计时 16 天】大会早鸟票已经售罄,现正式进入全额票阶段。还记得去年一票难求的AI WORLD 2016盛况吗?今年,即将于2017年11月8日在北京国家会议中心举办的AI World 2017世界人工智能大会上,我们请到CMU教授、冷扑大师发明人Tuomas Sandholm、 百度副总裁王海峰 、微软全球资深副总裁王永东、亚马逊AWS机器学习总监Alex Smola 、科大讯飞执行总裁胡郁,华为消费者事业群总裁邵洋、腾讯优图实验室杰出科学家贾佳亚等国内外人工智能领袖参会并演讲,一起探讨中国与世界AI的最新趋势。点击文末阅读原文,马上参会!抢票链接: http://www.huodongxing.com/event/2405852054900?td=4231978320026大会官网:http://www.aiworld2017.com 新智元编译 来源:qz.com作者:Dave Gershgorn 编译: 马文 【新智元导读】教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,谷歌最新发布一个电影片段数据集AVA,旨在教机器理解人的活动。 该数据集以人类为中心进行标注,包含80类动作的 57600 个视频片段,有助于人类行为识别系统的研究 数据集地址: https://research.google.com/ava/论文:https://arxiv.org/abs/1705.08421 教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,对个人视频搜索和发现、运动分析和手势界面等应用十分重要。尽管在过去的几年里,对图像进行分类和在图像中寻找目标对象方面取得了令人兴奋的突破,但识别人类的动作仍然是一个巨大的挑战。这是因为动作的定义比视频中的对象的定义要差,因此很难构造一个精细标记的动作视频数据集。许多基准数据集,例如 UCF101、activitynet 和DeepMind 的 Kinetics,都是采用图像分类的标记方案,在数据集中为每个视频或视频片段分配一个标签,而没有数据集能用于包含多个可能执行不同动作的人的复杂场景。 谷歌上周发布一个新的电影片段数据集,旨在教机器理解人的活动。这个数据集被称为 AVA(atomic visual action),这些视频对人类来说并不是很特别的东西——仅仅是 YouTube 上人们喝水、做饭等等的3秒钟视频片段。但每段视频都与一个文件捆绑在一起,这个文件勾勒了机器学习算法应该观察的人,描述他们的姿势,以及他们是否正在与另一个人或物进行互动。就像指着一只狗狗给一个小孩看,并教他说“狗!”,这个数据集是这类场景的数字版本。 与其他动作数据集相比,AVA具有以下几个关键特征: 以人类为中心的标注(Person-centric annotation)。每个动作标签都与一个人相关联,而不是与一个视频或视频剪辑关联。因此,我们能够为在同一场景中执行不同动作的多个人分配不同的标签,这是种情况很常见。原子视觉动作(Atomic visual actions)。我们将动作标签限制在一定时间尺度(3秒),动作需要是物理性质的,并且有清晰的视觉信号。真实的视频材料。我们使用不同类型、不同国家的电影作为AVA的数据源,因此,数据中包含了广泛的人类行为。 3秒视频片段示例,每个片段的中间帧都有边界框标注。(为了清晰起见,每个样本只显示一个边界框) 当视频中有多个人时,每个人都有自己的标签。这样,算法就能知道“握手”的动作需要两个人。 AVA 中共同出现频率最高的动作对 这项技术可以帮助谷歌分析 YouTube 上的视频。它可以应用来更好地投放定向广告,或用于内容过滤。作者在相应的研究论文中写道,最终的目标是教计算机社会视觉智能(social visual intelligence),即“理解人类正在做什么,他们下一步将会做什么,以及他们想要达到的目的。” AVA 数据集的动作标签分布(x轴只包括了词汇表中的一部分标签) AVA 数据集包含 57600 个标记好的视频,详细记录了80类动作。简单的动作,例如站立、说话、倾听和走路等在数据集中更有代表性,每个标签都有超过1万个视频片段。研究人员在论文中写道,使用电影中的片段确实会给他们的工作带来一些偏见,因为电影有其“语法”,一些动作被戏剧化了。 “我们并不认为这些数据是完美的。”论文中写道:“但这比使用由用户上传的内容更好,比如动物杂耍视频、DIY教学视频、儿童生日派对之类的视频等等。” 论文引用中试图找到“不同国籍的顶级演员”,但没有详细说明数据集可能会因种族或性别而产生偏见。研究者希望AVA的发布将有助于人类行为识别系统的研究,为基于个人行为层面的精细时空粒度的标签对复杂活动进行建模提供机会。 原文: https://qz.com/1108090/google-is-teaching-its-ai-how-humans-hug-cook-and-fight/【AI WORLD 2017世界人工智能大会倒计时 16 天】点击图片查看嘉宾与日程。大会门票销售火热,抢票链接: http://www.huodongxing.com/event/2405852054900?td=4231978320026【扫一扫或点击阅读原文抢购大会门票】AI WORLD 2017 世界人工智能大会购票二维码: via: http://mp.weixin.qq.com/s?__biz=MzI3MTA0MTk1MA==&mid=2652006567&idx=4&sn=9c10265351d321ccca4a5fbac1708026&scene=0#wechat_redirect
爱可可-爱生活 网页版 2017-10-23 10:37
深度学习
《浅谈深度学习中的代码效率问题》via:鹏博向上 http://t.cn/RW5ZSIi
 爱可可-爱生活 网页版 2017-10-23 06:04
爱可可-爱生活 网页版 2017-10-23 06:04
深度学习 算法 资源 Jason Brownlee 分类 课程
【深度学习文档分类最佳实践】《Best Practices for Document Classification with Deep Learning | Machine Learning Mastery》by Jason Brownlee http://t.cn/RWqfaH4
最新动态
2017-10-23 (9)
 稀土掘金 网页版 2017-10-23 18:39
稀土掘金 网页版 2017-10-23 18:39
深度学习 自然语言处理 Python
最全知乎专栏合集:编程、python、爬虫、数据分析、挖掘、ML、NLP、DL…来掘金看原文[小黄人高兴] http://t.cn/RWcjeiP

 大数据_机器学习 网页版 2017-10-23 18:07
大数据_机器学习 网页版 2017-10-23 18:07
算法 Python 矩阵
用Python实现感知机 (python机器学习一) >>>> 练样本中选取点,预测值为; 如果预测值不等于真实值,即,更新和; 重复步骤2、3,直到达到训练次数或小于指定误差; 输入未知点的特征向量,。 而在第3步中如何…全部算法,下面用python来实现感知机。 0x03 代码实现 首先定义符号函数: 1…全文: http://m.weibo.cn/5291384903/4166075484256470
 AI科技大本营 网页版 2017-10-23 17:57
AI科技大本营 网页版 2017-10-23 17:57
入门 算法
【资源 | 最新机器学习必备十大入门算法!都在这里了】详见: http://t.cn/RWcIfTm 向初学者介绍十大机器学习(ML)算法,并附上数字和示例,方便理解。

 南京轻搜 网页版 2017-10-23 14:33
南京轻搜 网页版 2017-10-23 14:33
【研究发现#机器学习# 可推动经济飞速发展】美国西北大学经济学家研究称,如果机器学习真的能够执行所有人类的任务,产生创新观念,那么经济获得飞速发展就会成为可能。如果快速完善的人工智能能够向市场提供创新动力,进而改善企业工作环境,那么一些工作岗位的薪资可能也会大幅增长? …全文: http://m.weibo.cn/5897818869/4166021508136248

 新智元 网页版 2017-10-23 13:32
新智元 网页版 2017-10-23 13:32
视觉 算法 Trevor Paglen
【新智元导读】麦克阿瑟“天才奖”获得者Trevor Paglen训练AI算法,他的展览项目“看不见的图像的研究”(A Study of Invisible Images),反向展示AI如何认识世界。在此过程中,他注意到一些问题,比如作为业界标准的ImageNet数据集中,有很多图像带有奇怪的标签,如今计算机视觉界中使用最多的一张女…全文: http://m.weibo.cn/5703921756/4166006244775710
新智元 网页版 2017-10-23 13:30
视觉 行业动态
【新智元导读】教机器理解视频中的人的行为是计算机视觉中的一个基本研究问题,谷歌最新发布一个电影片段数据集AVA,旨在教机器理解人的活动。 该数据集以人类为中心进行标注,包含80类动作的 57600 个视频片段,有助于人类行为识别系统的研究。 http://t.cn/RW5eiJO
爱可可-爱生活 网页版 2017-10-23 13:29
会议活动 深度学习 活动
【Nvidia深度学习研讨会资料】“Deep learning workshop” GitHub: https ://github .com/NVIDIA-Korea/deep-learning-workshop

 蚁工厂 网页版 2017-10-23 09:36
蚁工厂 网页版 2017-10-23 09:36
深度学习
#开源项目推荐# plaidml,A framework for making deep learning work everywhere.致力于跨平台开发部署的开源高性能深度学习框架。一方面可以让硬件开发者快速集成到框架里,一方面也可以让框架的使用者有接入各种硬件的能力。 目前已经验证过的硬件有: AMD R9 Nano RX 480 …全文: http://m.weibo.cn/2194035935/4165946861596983

 湾区日报BayArea 网页版 2017-10-23 08:28
湾区日报BayArea 网页版 2017-10-23 08:28
应用 自然语言处理 机器人
【在过去一年,聊天机器人的发展令人失望】感觉从去年Facebook的F8开发者会议后,聊天机器人着实火了起来;但老百姓期望的是真的能聊天的那种bot,而开发者们给出的要嘛是婴幼儿般智商的bot,要嘛是选择题式的菜单界面 http://t.cn/RC24D4h